fork from github/youtube-local
This commit is contained in:
32
.gitattributes
vendored
Normal file
32
.gitattributes
vendored
Normal file
@@ -0,0 +1,32 @@
|
|||||||
|
# Basic .gitattributes for a python repo.
|
||||||
|
|
||||||
|
# Source files
|
||||||
|
# ============
|
||||||
|
*.pxd text
|
||||||
|
*.py text
|
||||||
|
*.py3 text
|
||||||
|
*.pyw text
|
||||||
|
*.pyx text
|
||||||
|
|
||||||
|
*.html text
|
||||||
|
*.xml text
|
||||||
|
*.xhtml text
|
||||||
|
*.htm text
|
||||||
|
*.css text
|
||||||
|
*.txt text
|
||||||
|
|
||||||
|
*.bat text eol=crlf
|
||||||
|
|
||||||
|
# Binary files
|
||||||
|
# ============
|
||||||
|
*.db binary
|
||||||
|
*.p binary
|
||||||
|
*.pkl binary
|
||||||
|
*.pyc binary
|
||||||
|
*.pyd binary
|
||||||
|
*.pyo binary
|
||||||
|
|
||||||
|
# Note: .db, .p, and .pkl files are associated
|
||||||
|
# with the python modules ``pickle``, ``dbm.*``,
|
||||||
|
# ``shelve``, ``marshal``, ``anydbm``, & ``bsddb``
|
||||||
|
# (among others).
|
||||||
16
.gitignore
vendored
Normal file
16
.gitignore
vendored
Normal file
@@ -0,0 +1,16 @@
|
|||||||
|
__pycache__/
|
||||||
|
*$py.class
|
||||||
|
debug/
|
||||||
|
data/
|
||||||
|
python/
|
||||||
|
release/
|
||||||
|
youtube-local/
|
||||||
|
banned_addresses.txt
|
||||||
|
settings.txt
|
||||||
|
get-pip.py
|
||||||
|
latest-dist.zip
|
||||||
|
*.7z
|
||||||
|
*.zip
|
||||||
|
*venv*
|
||||||
|
moy/
|
||||||
|
__pycache__/
|
||||||
62
HACKING.md
Normal file
62
HACKING.md
Normal file
@@ -0,0 +1,62 @@
|
|||||||
|
# Coding guidelines
|
||||||
|
* Follow the [PEP 8 guidelines](https://www.python.org/dev/peps/pep-0008/) for all new Python code as best you can. Some old code doesn't follow PEP 8 yet. This includes limiting line length to 79 characters (with exception for long strings such as URLs that can't reasonably be broken across multiple lines) and using 4 spaces for indentation.
|
||||||
|
|
||||||
|
* Do not use single letter or cryptic names for variables (except iterator variables or the like). When in doubt, choose the more verbose option.
|
||||||
|
|
||||||
|
* For consistency, use ' instead of " for strings for all new code. Only use " when the string contains ' inside it. Exception: " is used for html attributes in Jinja templates.
|
||||||
|
|
||||||
|
* Don't leave trailing whitespaces at the end of lines. Configure your editor the way you need to avoid this from happening.
|
||||||
|
|
||||||
|
* Make commits highly descriptive, so that other people (and yourself in the future) know exactly why a change was made. The first line of the commit is a short summary. Add a blank line and then a more extensive summary. If it is a bug fix, this should include a description of what caused the bug and how this commit fixes it. There's a lot of knowledge you gather while solving a problem. Dump as much of it as possible into the commit for others and yourself to learn from. Mention the issue number (e.g. Fixes #23) in your commit if applicable. [Here](https://www.freecodecamp.org/news/writing-good-commit-messages-a-practical-guide/) are some useful guidelines.
|
||||||
|
|
||||||
|
* The same guidelines apply to commenting code. If a piece of code is not self-explanatory, add a comment explaining what it does and why it's there.
|
||||||
|
|
||||||
|
# Testing and releases
|
||||||
|
* This project uses pytest. To install pytest and any future dependencies needed for development, run pip3 on the requirements-dev.txt file. To run tests, run `python3 -m pytest` rather than just `pytest` because the former will make sure the toplevel directory is in Python's import search path.
|
||||||
|
|
||||||
|
* To build releases for Windows, run `python3 generate_release.py [intended python version here, without v infront]`. The required software (such as 7z, git) are listed in the `generate_release.py` file. For instance, wine is required if building on Linux. The build script will automatically download the embedded Python release to include. Use the latest release of Python 3.7.x so that Vista will be supported. See https://github.com/user234683/youtube-local/issues/6#issuecomment-672608388
|
||||||
|
|
||||||
|
# Overview of the software architecture
|
||||||
|
|
||||||
|
## server.py
|
||||||
|
* This is the entry point, and sets up the HTTP server that listens for incoming requests. It delegates the request to the appropriate "site_handler". For instance, `localhost:8080/youtube.com/...` goes to the `youtube` site handler, whereas `localhost:8080/ytimg.com/...` (the url for video thumbnails) goes to the site handler for just fetching static resources such as images from youtube.
|
||||||
|
|
||||||
|
* The reason for this architecture: the original design philosophy when I first conceived the project was that this would work for any site supported by youtube-dl, including Youtube, Vimeo, DailyMotion, etc. I've dropped this idea for now, though I might pick it up later. (youtube-dl is no longer used)
|
||||||
|
|
||||||
|
* This file uses the raw [WSGI request](https://www.python.org/dev/peps/pep-3333/) format. The WSGI format is a Python standard for how HTTP servers (I use the stock server provided by gevent) should call HTTP applications. So that's why the file contains stuff like `env['REQUEST_METHOD']`.
|
||||||
|
|
||||||
|
|
||||||
|
## Flask and Gevent
|
||||||
|
* The `youtube` handler in server.py then delegates the request to the Flask yt_app object, which the rest of the project uses. [Flask](https://flask.palletsprojects.com/en/1.1.x/) is a web application framework that makes handling requests easier than accessing the raw WSGI requests. Flask (Werkzeug specifically) figures out which function to call for a particular url. Each request handling function is registered into Flask's routing table by using function annotations above it. The request handling functions are always at the bottom of the file for a particular youtube page (channel, watch, playlist, etc.), and they're where you want to look to see how the response gets constructed for a particular url. Miscellaneous request handlers that don't belong anywhere else are located in `__init__.py`, which is where the `yt_app` object is instantiated.
|
||||||
|
|
||||||
|
* The actual html for youtube-local is generated using Jinja templates. Jinja lets you embed a Python-like language inside html files so you can use constructs such as for loops to construct the html for a list of 30 videos given a dictionary with information for those videos. Jinja is included as part of Flask. It has some annoying differences from Python in a lot of details, so check the [docs here](https://jinja.palletsprojects.com/en/2.11.x/) when you use it. The request handling functions will pass the information that has been scraped from Youtube into these templates for the final result.
|
||||||
|
* The project uses the gevent library for parallelism (such as for launching requests in parallel), as opposed to using the async keyword.
|
||||||
|
|
||||||
|
## util.py
|
||||||
|
* util.py is a grab-bag of miscellaneous things; admittedly I need to get around to refactoring it. The biggest thing it has is the `fetch_url` function which is what I use for sending out requests for Youtube. The Tor routing is managed here. `fetch_url` will raise an a `FetchError` exception if the request fails. The parameter `debug_name` in `fetch_url` is the filename that the response from Youtube will be saved to if the hidden debugging option is enabled in settings.txt. So if there's a bug when Youtube changes something, you can check the response from Youtube from that file.
|
||||||
|
|
||||||
|
## Data extraction - protobuf, polymer, and yt_data_extract
|
||||||
|
* proto.py is used for generating what are called ctokens needed when making requests to Youtube. These ctokens use Google's [protobuf](https://developers.google.com/protocol-buffers) format. Figuring out how to generate these in new instances requires some reverse engineering. I have a messy python file I use to make this convenient which you can find under ./youtube/proto_debug.py
|
||||||
|
|
||||||
|
* The responses from Youtube are in a JSON format called polymer (polymer is the name of the 2017-present Youtube layout). The JSON consists of a bunch of nested dictionaries which basically specify the layout of the page via objects called renderers. A renderer represents an object on a page in a similar way to html tags; the renders often contain renders inside them. The Javascript on Youtube's page translates this JSON to HTML. Example: `compactVideoRenderer` represents a video item in you can click on such as in the related videos (so these are called "items" in the codebase). This JSON is very messy. You'll need a JSON prettifier or something that gives you a tree view in order to study it.
|
||||||
|
|
||||||
|
* `yt_data_extract` is a module that parses this this raw JSON page layout and extracts the useful information from it into a standardized dictionary. So for instance, it can take the raw JSON response from the watch page and return a dictionary containing keys such as `title`, `description`,`related_videos (list)`, `likes`, etc. This module contains a lot of abstractions designed to make parsing the polymer format easier and more resilient towards changes from Youtube. (A lot of Youtube extractors just traverse the JSON tree like `response[1]['response']['continuation']['gridContinuationRenderer']['items']...` but this tends to break frequently when Youtube changes things.) If it fails to extract a piece of data, such as the like count, it will place `None` in that entry. Exceptions are not used in this module. So it uses functions which return None if there's a failure, such as `deep_get(response, 1, 'response', 'continuation', 'gridContinuationRenderer', 'items')` which returns None if any of those keys aren't present. The general purpose abstractions are located in `common.py`, while the functions for parsing specific responses (watch page, playlist, channel, etc.) are located in `watch_extraction.py` and `everything_else.py`.
|
||||||
|
|
||||||
|
* Most of these abstractions are self-explanatory, except for `extract_items_from_renderer`, a function that performs a recursive search for the specified renderers. You give it a renderer which contains nested renderers, and a set of the renderer types you want to extract (by default, these are the video/playlist/channel preview items). It will search through the nested renderers and gather the specified items, in addition to the continuation token (ctoken) for the last list of items it finds if there is one. Using this function achieves resiliency against Youtube rearranging the items into a different hierarchy.
|
||||||
|
|
||||||
|
* The `extract_items` function is similar but works on the response object, automatically finding the appropriate renderer to call `extract_items_from_renderer` on.
|
||||||
|
|
||||||
|
|
||||||
|
## Other
|
||||||
|
* subscriptions.py uses SQLite to store data.
|
||||||
|
|
||||||
|
* Hidden settings only relevant to developers (such as for debugging) are not displayed on the settings page. They can be found in the settings.txt file.
|
||||||
|
|
||||||
|
* Since I can't anticipate the things that will trip up beginners to the codebase, if you spend awhile figuring something out, go ahead and make a pull request adding a brief description of your findings to this document to help other beginners.
|
||||||
|
|
||||||
|
## Development tips
|
||||||
|
* When developing functionality to interact with Youtube in new ways, you'll want to use the network tab in your browser's devtools to inspect which requests get made under normal usage of Youtube. You'll also want a tool you can use to construct custom requests and specify headers to reverse engineer the request format. I use the [HeaderTool](https://github.com/loreii/HeaderTool) extension in Firefox, but there's probably a more streamlined program out there.
|
||||||
|
|
||||||
|
* You'll want to have a utility or IDE that can perform full text search on a repository, since this is crucial for navigating unfamiliar codebases to figure out where certain strings appear or where things get defined.
|
||||||
|
|
||||||
|
* If you're confused what the purpose of a particular line/section of code is, you can use the "git blame" feature on github (click the line number and then the three dots) to view the commit where the line of code was created and check the commit message. This will give you an idea of how it was put together.
|
||||||
619
LICENSE
Normal file
619
LICENSE
Normal file
@@ -0,0 +1,619 @@
|
|||||||
|
GNU AFFERO GENERAL PUBLIC LICENSE
|
||||||
|
Version 3, 19 November 2007
|
||||||
|
|
||||||
|
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
||||||
|
Everyone is permitted to copy and distribute verbatim copies
|
||||||
|
of this license document, but changing it is not allowed.
|
||||||
|
|
||||||
|
Preamble
|
||||||
|
|
||||||
|
The GNU Affero General Public License is a free, copyleft license for
|
||||||
|
software and other kinds of works, specifically designed to ensure
|
||||||
|
cooperation with the community in the case of network server software.
|
||||||
|
|
||||||
|
The licenses for most software and other practical works are designed
|
||||||
|
to take away your freedom to share and change the works. By contrast,
|
||||||
|
our General Public Licenses are intended to guarantee your freedom to
|
||||||
|
share and change all versions of a program--to make sure it remains free
|
||||||
|
software for all its users.
|
||||||
|
|
||||||
|
When we speak of free software, we are referring to freedom, not
|
||||||
|
price. Our General Public Licenses are designed to make sure that you
|
||||||
|
have the freedom to distribute copies of free software (and charge for
|
||||||
|
them if you wish), that you receive source code or can get it if you
|
||||||
|
want it, that you can change the software or use pieces of it in new
|
||||||
|
free programs, and that you know you can do these things.
|
||||||
|
|
||||||
|
Developers that use our General Public Licenses protect your rights
|
||||||
|
with two steps: (1) assert copyright on the software, and (2) offer
|
||||||
|
you this License which gives you legal permission to copy, distribute
|
||||||
|
and/or modify the software.
|
||||||
|
|
||||||
|
A secondary benefit of defending all users' freedom is that
|
||||||
|
improvements made in alternate versions of the program, if they
|
||||||
|
receive widespread use, become available for other developers to
|
||||||
|
incorporate. Many developers of free software are heartened and
|
||||||
|
encouraged by the resulting cooperation. However, in the case of
|
||||||
|
software used on network servers, this result may fail to come about.
|
||||||
|
The GNU General Public License permits making a modified version and
|
||||||
|
letting the public access it on a server without ever releasing its
|
||||||
|
source code to the public.
|
||||||
|
|
||||||
|
The GNU Affero General Public License is designed specifically to
|
||||||
|
ensure that, in such cases, the modified source code becomes available
|
||||||
|
to the community. It requires the operator of a network server to
|
||||||
|
provide the source code of the modified version running there to the
|
||||||
|
users of that server. Therefore, public use of a modified version, on
|
||||||
|
a publicly accessible server, gives the public access to the source
|
||||||
|
code of the modified version.
|
||||||
|
|
||||||
|
An older license, called the Affero General Public License and
|
||||||
|
published by Affero, was designed to accomplish similar goals. This is
|
||||||
|
a different license, not a version of the Affero GPL, but Affero has
|
||||||
|
released a new version of the Affero GPL which permits relicensing under
|
||||||
|
this license.
|
||||||
|
|
||||||
|
The precise terms and conditions for copying, distribution and
|
||||||
|
modification follow.
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
0. Definitions.
|
||||||
|
|
||||||
|
"This License" refers to version 3 of the GNU Affero General Public License.
|
||||||
|
|
||||||
|
"Copyright" also means copyright-like laws that apply to other kinds of
|
||||||
|
works, such as semiconductor masks.
|
||||||
|
|
||||||
|
"The Program" refers to any copyrightable work licensed under this
|
||||||
|
License. Each licensee is addressed as "you". "Licensees" and
|
||||||
|
"recipients" may be individuals or organizations.
|
||||||
|
|
||||||
|
To "modify" a work means to copy from or adapt all or part of the work
|
||||||
|
in a fashion requiring copyright permission, other than the making of an
|
||||||
|
exact copy. The resulting work is called a "modified version" of the
|
||||||
|
earlier work or a work "based on" the earlier work.
|
||||||
|
|
||||||
|
A "covered work" means either the unmodified Program or a work based
|
||||||
|
on the Program.
|
||||||
|
|
||||||
|
To "propagate" a work means to do anything with it that, without
|
||||||
|
permission, would make you directly or secondarily liable for
|
||||||
|
infringement under applicable copyright law, except executing it on a
|
||||||
|
computer or modifying a private copy. Propagation includes copying,
|
||||||
|
distribution (with or without modification), making available to the
|
||||||
|
public, and in some countries other activities as well.
|
||||||
|
|
||||||
|
To "convey" a work means any kind of propagation that enables other
|
||||||
|
parties to make or receive copies. Mere interaction with a user through
|
||||||
|
a computer network, with no transfer of a copy, is not conveying.
|
||||||
|
|
||||||
|
An interactive user interface displays "Appropriate Legal Notices"
|
||||||
|
to the extent that it includes a convenient and prominently visible
|
||||||
|
feature that (1) displays an appropriate copyright notice, and (2)
|
||||||
|
tells the user that there is no warranty for the work (except to the
|
||||||
|
extent that warranties are provided), that licensees may convey the
|
||||||
|
work under this License, and how to view a copy of this License. If
|
||||||
|
the interface presents a list of user commands or options, such as a
|
||||||
|
menu, a prominent item in the list meets this criterion.
|
||||||
|
|
||||||
|
1. Source Code.
|
||||||
|
|
||||||
|
The "source code" for a work means the preferred form of the work
|
||||||
|
for making modifications to it. "Object code" means any non-source
|
||||||
|
form of a work.
|
||||||
|
|
||||||
|
A "Standard Interface" means an interface that either is an official
|
||||||
|
standard defined by a recognized standards body, or, in the case of
|
||||||
|
interfaces specified for a particular programming language, one that
|
||||||
|
is widely used among developers working in that language.
|
||||||
|
|
||||||
|
The "System Libraries" of an executable work include anything, other
|
||||||
|
than the work as a whole, that (a) is included in the normal form of
|
||||||
|
packaging a Major Component, but which is not part of that Major
|
||||||
|
Component, and (b) serves only to enable use of the work with that
|
||||||
|
Major Component, or to implement a Standard Interface for which an
|
||||||
|
implementation is available to the public in source code form. A
|
||||||
|
"Major Component", in this context, means a major essential component
|
||||||
|
(kernel, window system, and so on) of the specific operating system
|
||||||
|
(if any) on which the executable work runs, or a compiler used to
|
||||||
|
produce the work, or an object code interpreter used to run it.
|
||||||
|
|
||||||
|
The "Corresponding Source" for a work in object code form means all
|
||||||
|
the source code needed to generate, install, and (for an executable
|
||||||
|
work) run the object code and to modify the work, including scripts to
|
||||||
|
control those activities. However, it does not include the work's
|
||||||
|
System Libraries, or general-purpose tools or generally available free
|
||||||
|
programs which are used unmodified in performing those activities but
|
||||||
|
which are not part of the work. For example, Corresponding Source
|
||||||
|
includes interface definition files associated with source files for
|
||||||
|
the work, and the source code for shared libraries and dynamically
|
||||||
|
linked subprograms that the work is specifically designed to require,
|
||||||
|
such as by intimate data communication or control flow between those
|
||||||
|
subprograms and other parts of the work.
|
||||||
|
|
||||||
|
The Corresponding Source need not include anything that users
|
||||||
|
can regenerate automatically from other parts of the Corresponding
|
||||||
|
Source.
|
||||||
|
|
||||||
|
The Corresponding Source for a work in source code form is that
|
||||||
|
same work.
|
||||||
|
|
||||||
|
2. Basic Permissions.
|
||||||
|
|
||||||
|
All rights granted under this License are granted for the term of
|
||||||
|
copyright on the Program, and are irrevocable provided the stated
|
||||||
|
conditions are met. This License explicitly affirms your unlimited
|
||||||
|
permission to run the unmodified Program. The output from running a
|
||||||
|
covered work is covered by this License only if the output, given its
|
||||||
|
content, constitutes a covered work. This License acknowledges your
|
||||||
|
rights of fair use or other equivalent, as provided by copyright law.
|
||||||
|
|
||||||
|
You may make, run and propagate covered works that you do not
|
||||||
|
convey, without conditions so long as your license otherwise remains
|
||||||
|
in force. You may convey covered works to others for the sole purpose
|
||||||
|
of having them make modifications exclusively for you, or provide you
|
||||||
|
with facilities for running those works, provided that you comply with
|
||||||
|
the terms of this License in conveying all material for which you do
|
||||||
|
not control copyright. Those thus making or running the covered works
|
||||||
|
for you must do so exclusively on your behalf, under your direction
|
||||||
|
and control, on terms that prohibit them from making any copies of
|
||||||
|
your copyrighted material outside their relationship with you.
|
||||||
|
|
||||||
|
Conveying under any other circumstances is permitted solely under
|
||||||
|
the conditions stated below. Sublicensing is not allowed; section 10
|
||||||
|
makes it unnecessary.
|
||||||
|
|
||||||
|
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||||
|
|
||||||
|
No covered work shall be deemed part of an effective technological
|
||||||
|
measure under any applicable law fulfilling obligations under article
|
||||||
|
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
||||||
|
similar laws prohibiting or restricting circumvention of such
|
||||||
|
measures.
|
||||||
|
|
||||||
|
When you convey a covered work, you waive any legal power to forbid
|
||||||
|
circumvention of technological measures to the extent such circumvention
|
||||||
|
is effected by exercising rights under this License with respect to
|
||||||
|
the covered work, and you disclaim any intention to limit operation or
|
||||||
|
modification of the work as a means of enforcing, against the work's
|
||||||
|
users, your or third parties' legal rights to forbid circumvention of
|
||||||
|
technological measures.
|
||||||
|
|
||||||
|
4. Conveying Verbatim Copies.
|
||||||
|
|
||||||
|
You may convey verbatim copies of the Program's source code as you
|
||||||
|
receive it, in any medium, provided that you conspicuously and
|
||||||
|
appropriately publish on each copy an appropriate copyright notice;
|
||||||
|
keep intact all notices stating that this License and any
|
||||||
|
non-permissive terms added in accord with section 7 apply to the code;
|
||||||
|
keep intact all notices of the absence of any warranty; and give all
|
||||||
|
recipients a copy of this License along with the Program.
|
||||||
|
|
||||||
|
You may charge any price or no price for each copy that you convey,
|
||||||
|
and you may offer support or warranty protection for a fee.
|
||||||
|
|
||||||
|
5. Conveying Modified Source Versions.
|
||||||
|
|
||||||
|
You may convey a work based on the Program, or the modifications to
|
||||||
|
produce it from the Program, in the form of source code under the
|
||||||
|
terms of section 4, provided that you also meet all of these conditions:
|
||||||
|
|
||||||
|
a) The work must carry prominent notices stating that you modified
|
||||||
|
it, and giving a relevant date.
|
||||||
|
|
||||||
|
b) The work must carry prominent notices stating that it is
|
||||||
|
released under this License and any conditions added under section
|
||||||
|
7. This requirement modifies the requirement in section 4 to
|
||||||
|
"keep intact all notices".
|
||||||
|
|
||||||
|
c) You must license the entire work, as a whole, under this
|
||||||
|
License to anyone who comes into possession of a copy. This
|
||||||
|
License will therefore apply, along with any applicable section 7
|
||||||
|
additional terms, to the whole of the work, and all its parts,
|
||||||
|
regardless of how they are packaged. This License gives no
|
||||||
|
permission to license the work in any other way, but it does not
|
||||||
|
invalidate such permission if you have separately received it.
|
||||||
|
|
||||||
|
d) If the work has interactive user interfaces, each must display
|
||||||
|
Appropriate Legal Notices; however, if the Program has interactive
|
||||||
|
interfaces that do not display Appropriate Legal Notices, your
|
||||||
|
work need not make them do so.
|
||||||
|
|
||||||
|
A compilation of a covered work with other separate and independent
|
||||||
|
works, which are not by their nature extensions of the covered work,
|
||||||
|
and which are not combined with it such as to form a larger program,
|
||||||
|
in or on a volume of a storage or distribution medium, is called an
|
||||||
|
"aggregate" if the compilation and its resulting copyright are not
|
||||||
|
used to limit the access or legal rights of the compilation's users
|
||||||
|
beyond what the individual works permit. Inclusion of a covered work
|
||||||
|
in an aggregate does not cause this License to apply to the other
|
||||||
|
parts of the aggregate.
|
||||||
|
|
||||||
|
6. Conveying Non-Source Forms.
|
||||||
|
|
||||||
|
You may convey a covered work in object code form under the terms
|
||||||
|
of sections 4 and 5, provided that you also convey the
|
||||||
|
machine-readable Corresponding Source under the terms of this License,
|
||||||
|
in one of these ways:
|
||||||
|
|
||||||
|
a) Convey the object code in, or embodied in, a physical product
|
||||||
|
(including a physical distribution medium), accompanied by the
|
||||||
|
Corresponding Source fixed on a durable physical medium
|
||||||
|
customarily used for software interchange.
|
||||||
|
|
||||||
|
b) Convey the object code in, or embodied in, a physical product
|
||||||
|
(including a physical distribution medium), accompanied by a
|
||||||
|
written offer, valid for at least three years and valid for as
|
||||||
|
long as you offer spare parts or customer support for that product
|
||||||
|
model, to give anyone who possesses the object code either (1) a
|
||||||
|
copy of the Corresponding Source for all the software in the
|
||||||
|
product that is covered by this License, on a durable physical
|
||||||
|
medium customarily used for software interchange, for a price no
|
||||||
|
more than your reasonable cost of physically performing this
|
||||||
|
conveying of source, or (2) access to copy the
|
||||||
|
Corresponding Source from a network server at no charge.
|
||||||
|
|
||||||
|
c) Convey individual copies of the object code with a copy of the
|
||||||
|
written offer to provide the Corresponding Source. This
|
||||||
|
alternative is allowed only occasionally and noncommercially, and
|
||||||
|
only if you received the object code with such an offer, in accord
|
||||||
|
with subsection 6b.
|
||||||
|
|
||||||
|
d) Convey the object code by offering access from a designated
|
||||||
|
place (gratis or for a charge), and offer equivalent access to the
|
||||||
|
Corresponding Source in the same way through the same place at no
|
||||||
|
further charge. You need not require recipients to copy the
|
||||||
|
Corresponding Source along with the object code. If the place to
|
||||||
|
copy the object code is a network server, the Corresponding Source
|
||||||
|
may be on a different server (operated by you or a third party)
|
||||||
|
that supports equivalent copying facilities, provided you maintain
|
||||||
|
clear directions next to the object code saying where to find the
|
||||||
|
Corresponding Source. Regardless of what server hosts the
|
||||||
|
Corresponding Source, you remain obligated to ensure that it is
|
||||||
|
available for as long as needed to satisfy these requirements.
|
||||||
|
|
||||||
|
e) Convey the object code using peer-to-peer transmission, provided
|
||||||
|
you inform other peers where the object code and Corresponding
|
||||||
|
Source of the work are being offered to the general public at no
|
||||||
|
charge under subsection 6d.
|
||||||
|
|
||||||
|
A separable portion of the object code, whose source code is excluded
|
||||||
|
from the Corresponding Source as a System Library, need not be
|
||||||
|
included in conveying the object code work.
|
||||||
|
|
||||||
|
A "User Product" is either (1) a "consumer product", which means any
|
||||||
|
tangible personal property which is normally used for personal, family,
|
||||||
|
or household purposes, or (2) anything designed or sold for incorporation
|
||||||
|
into a dwelling. In determining whether a product is a consumer product,
|
||||||
|
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||||
|
product received by a particular user, "normally used" refers to a
|
||||||
|
typical or common use of that class of product, regardless of the status
|
||||||
|
of the particular user or of the way in which the particular user
|
||||||
|
actually uses, or expects or is expected to use, the product. A product
|
||||||
|
is a consumer product regardless of whether the product has substantial
|
||||||
|
commercial, industrial or non-consumer uses, unless such uses represent
|
||||||
|
the only significant mode of use of the product.
|
||||||
|
|
||||||
|
"Installation Information" for a User Product means any methods,
|
||||||
|
procedures, authorization keys, or other information required to install
|
||||||
|
and execute modified versions of a covered work in that User Product from
|
||||||
|
a modified version of its Corresponding Source. The information must
|
||||||
|
suffice to ensure that the continued functioning of the modified object
|
||||||
|
code is in no case prevented or interfered with solely because
|
||||||
|
modification has been made.
|
||||||
|
|
||||||
|
If you convey an object code work under this section in, or with, or
|
||||||
|
specifically for use in, a User Product, and the conveying occurs as
|
||||||
|
part of a transaction in which the right of possession and use of the
|
||||||
|
User Product is transferred to the recipient in perpetuity or for a
|
||||||
|
fixed term (regardless of how the transaction is characterized), the
|
||||||
|
Corresponding Source conveyed under this section must be accompanied
|
||||||
|
by the Installation Information. But this requirement does not apply
|
||||||
|
if neither you nor any third party retains the ability to install
|
||||||
|
modified object code on the User Product (for example, the work has
|
||||||
|
been installed in ROM).
|
||||||
|
|
||||||
|
The requirement to provide Installation Information does not include a
|
||||||
|
requirement to continue to provide support service, warranty, or updates
|
||||||
|
for a work that has been modified or installed by the recipient, or for
|
||||||
|
the User Product in which it has been modified or installed. Access to a
|
||||||
|
network may be denied when the modification itself materially and
|
||||||
|
adversely affects the operation of the network or violates the rules and
|
||||||
|
protocols for communication across the network.
|
||||||
|
|
||||||
|
Corresponding Source conveyed, and Installation Information provided,
|
||||||
|
in accord with this section must be in a format that is publicly
|
||||||
|
documented (and with an implementation available to the public in
|
||||||
|
source code form), and must require no special password or key for
|
||||||
|
unpacking, reading or copying.
|
||||||
|
|
||||||
|
7. Additional Terms.
|
||||||
|
|
||||||
|
"Additional permissions" are terms that supplement the terms of this
|
||||||
|
License by making exceptions from one or more of its conditions.
|
||||||
|
Additional permissions that are applicable to the entire Program shall
|
||||||
|
be treated as though they were included in this License, to the extent
|
||||||
|
that they are valid under applicable law. If additional permissions
|
||||||
|
apply only to part of the Program, that part may be used separately
|
||||||
|
under those permissions, but the entire Program remains governed by
|
||||||
|
this License without regard to the additional permissions.
|
||||||
|
|
||||||
|
When you convey a copy of a covered work, you may at your option
|
||||||
|
remove any additional permissions from that copy, or from any part of
|
||||||
|
it. (Additional permissions may be written to require their own
|
||||||
|
removal in certain cases when you modify the work.) You may place
|
||||||
|
additional permissions on material, added by you to a covered work,
|
||||||
|
for which you have or can give appropriate copyright permission.
|
||||||
|
|
||||||
|
Notwithstanding any other provision of this License, for material you
|
||||||
|
add to a covered work, you may (if authorized by the copyright holders of
|
||||||
|
that material) supplement the terms of this License with terms:
|
||||||
|
|
||||||
|
a) Disclaiming warranty or limiting liability differently from the
|
||||||
|
terms of sections 15 and 16 of this License; or
|
||||||
|
|
||||||
|
b) Requiring preservation of specified reasonable legal notices or
|
||||||
|
author attributions in that material or in the Appropriate Legal
|
||||||
|
Notices displayed by works containing it; or
|
||||||
|
|
||||||
|
c) Prohibiting misrepresentation of the origin of that material, or
|
||||||
|
requiring that modified versions of such material be marked in
|
||||||
|
reasonable ways as different from the original version; or
|
||||||
|
|
||||||
|
d) Limiting the use for publicity purposes of names of licensors or
|
||||||
|
authors of the material; or
|
||||||
|
|
||||||
|
e) Declining to grant rights under trademark law for use of some
|
||||||
|
trade names, trademarks, or service marks; or
|
||||||
|
|
||||||
|
f) Requiring indemnification of licensors and authors of that
|
||||||
|
material by anyone who conveys the material (or modified versions of
|
||||||
|
it) with contractual assumptions of liability to the recipient, for
|
||||||
|
any liability that these contractual assumptions directly impose on
|
||||||
|
those licensors and authors.
|
||||||
|
|
||||||
|
All other non-permissive additional terms are considered "further
|
||||||
|
restrictions" within the meaning of section 10. If the Program as you
|
||||||
|
received it, or any part of it, contains a notice stating that it is
|
||||||
|
governed by this License along with a term that is a further
|
||||||
|
restriction, you may remove that term. If a license document contains
|
||||||
|
a further restriction but permits relicensing or conveying under this
|
||||||
|
License, you may add to a covered work material governed by the terms
|
||||||
|
of that license document, provided that the further restriction does
|
||||||
|
not survive such relicensing or conveying.
|
||||||
|
|
||||||
|
If you add terms to a covered work in accord with this section, you
|
||||||
|
must place, in the relevant source files, a statement of the
|
||||||
|
additional terms that apply to those files, or a notice indicating
|
||||||
|
where to find the applicable terms.
|
||||||
|
|
||||||
|
Additional terms, permissive or non-permissive, may be stated in the
|
||||||
|
form of a separately written license, or stated as exceptions;
|
||||||
|
the above requirements apply either way.
|
||||||
|
|
||||||
|
8. Termination.
|
||||||
|
|
||||||
|
You may not propagate or modify a covered work except as expressly
|
||||||
|
provided under this License. Any attempt otherwise to propagate or
|
||||||
|
modify it is void, and will automatically terminate your rights under
|
||||||
|
this License (including any patent licenses granted under the third
|
||||||
|
paragraph of section 11).
|
||||||
|
|
||||||
|
However, if you cease all violation of this License, then your
|
||||||
|
license from a particular copyright holder is reinstated (a)
|
||||||
|
provisionally, unless and until the copyright holder explicitly and
|
||||||
|
finally terminates your license, and (b) permanently, if the copyright
|
||||||
|
holder fails to notify you of the violation by some reasonable means
|
||||||
|
prior to 60 days after the cessation.
|
||||||
|
|
||||||
|
Moreover, your license from a particular copyright holder is
|
||||||
|
reinstated permanently if the copyright holder notifies you of the
|
||||||
|
violation by some reasonable means, this is the first time you have
|
||||||
|
received notice of violation of this License (for any work) from that
|
||||||
|
copyright holder, and you cure the violation prior to 30 days after
|
||||||
|
your receipt of the notice.
|
||||||
|
|
||||||
|
Termination of your rights under this section does not terminate the
|
||||||
|
licenses of parties who have received copies or rights from you under
|
||||||
|
this License. If your rights have been terminated and not permanently
|
||||||
|
reinstated, you do not qualify to receive new licenses for the same
|
||||||
|
material under section 10.
|
||||||
|
|
||||||
|
9. Acceptance Not Required for Having Copies.
|
||||||
|
|
||||||
|
You are not required to accept this License in order to receive or
|
||||||
|
run a copy of the Program. Ancillary propagation of a covered work
|
||||||
|
occurring solely as a consequence of using peer-to-peer transmission
|
||||||
|
to receive a copy likewise does not require acceptance. However,
|
||||||
|
nothing other than this License grants you permission to propagate or
|
||||||
|
modify any covered work. These actions infringe copyright if you do
|
||||||
|
not accept this License. Therefore, by modifying or propagating a
|
||||||
|
covered work, you indicate your acceptance of this License to do so.
|
||||||
|
|
||||||
|
10. Automatic Licensing of Downstream Recipients.
|
||||||
|
|
||||||
|
Each time you convey a covered work, the recipient automatically
|
||||||
|
receives a license from the original licensors, to run, modify and
|
||||||
|
propagate that work, subject to this License. You are not responsible
|
||||||
|
for enforcing compliance by third parties with this License.
|
||||||
|
|
||||||
|
An "entity transaction" is a transaction transferring control of an
|
||||||
|
organization, or substantially all assets of one, or subdividing an
|
||||||
|
organization, or merging organizations. If propagation of a covered
|
||||||
|
work results from an entity transaction, each party to that
|
||||||
|
transaction who receives a copy of the work also receives whatever
|
||||||
|
licenses to the work the party's predecessor in interest had or could
|
||||||
|
give under the previous paragraph, plus a right to possession of the
|
||||||
|
Corresponding Source of the work from the predecessor in interest, if
|
||||||
|
the predecessor has it or can get it with reasonable efforts.
|
||||||
|
|
||||||
|
You may not impose any further restrictions on the exercise of the
|
||||||
|
rights granted or affirmed under this License. For example, you may
|
||||||
|
not impose a license fee, royalty, or other charge for exercise of
|
||||||
|
rights granted under this License, and you may not initiate litigation
|
||||||
|
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
||||||
|
any patent claim is infringed by making, using, selling, offering for
|
||||||
|
sale, or importing the Program or any portion of it.
|
||||||
|
|
||||||
|
11. Patents.
|
||||||
|
|
||||||
|
A "contributor" is a copyright holder who authorizes use under this
|
||||||
|
License of the Program or a work on which the Program is based. The
|
||||||
|
work thus licensed is called the contributor's "contributor version".
|
||||||
|
|
||||||
|
A contributor's "essential patent claims" are all patent claims
|
||||||
|
owned or controlled by the contributor, whether already acquired or
|
||||||
|
hereafter acquired, that would be infringed by some manner, permitted
|
||||||
|
by this License, of making, using, or selling its contributor version,
|
||||||
|
but do not include claims that would be infringed only as a
|
||||||
|
consequence of further modification of the contributor version. For
|
||||||
|
purposes of this definition, "control" includes the right to grant
|
||||||
|
patent sublicenses in a manner consistent with the requirements of
|
||||||
|
this License.
|
||||||
|
|
||||||
|
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||||
|
patent license under the contributor's essential patent claims, to
|
||||||
|
make, use, sell, offer for sale, import and otherwise run, modify and
|
||||||
|
propagate the contents of its contributor version.
|
||||||
|
|
||||||
|
In the following three paragraphs, a "patent license" is any express
|
||||||
|
agreement or commitment, however denominated, not to enforce a patent
|
||||||
|
(such as an express permission to practice a patent or covenant not to
|
||||||
|
sue for patent infringement). To "grant" such a patent license to a
|
||||||
|
party means to make such an agreement or commitment not to enforce a
|
||||||
|
patent against the party.
|
||||||
|
|
||||||
|
If you convey a covered work, knowingly relying on a patent license,
|
||||||
|
and the Corresponding Source of the work is not available for anyone
|
||||||
|
to copy, free of charge and under the terms of this License, through a
|
||||||
|
publicly available network server or other readily accessible means,
|
||||||
|
then you must either (1) cause the Corresponding Source to be so
|
||||||
|
available, or (2) arrange to deprive yourself of the benefit of the
|
||||||
|
patent license for this particular work, or (3) arrange, in a manner
|
||||||
|
consistent with the requirements of this License, to extend the patent
|
||||||
|
license to downstream recipients. "Knowingly relying" means you have
|
||||||
|
actual knowledge that, but for the patent license, your conveying the
|
||||||
|
covered work in a country, or your recipient's use of the covered work
|
||||||
|
in a country, would infringe one or more identifiable patents in that
|
||||||
|
country that you have reason to believe are valid.
|
||||||
|
|
||||||
|
If, pursuant to or in connection with a single transaction or
|
||||||
|
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||||
|
covered work, and grant a patent license to some of the parties
|
||||||
|
receiving the covered work authorizing them to use, propagate, modify
|
||||||
|
or convey a specific copy of the covered work, then the patent license
|
||||||
|
you grant is automatically extended to all recipients of the covered
|
||||||
|
work and works based on it.
|
||||||
|
|
||||||
|
A patent license is "discriminatory" if it does not include within
|
||||||
|
the scope of its coverage, prohibits the exercise of, or is
|
||||||
|
conditioned on the non-exercise of one or more of the rights that are
|
||||||
|
specifically granted under this License. You may not convey a covered
|
||||||
|
work if you are a party to an arrangement with a third party that is
|
||||||
|
in the business of distributing software, under which you make payment
|
||||||
|
to the third party based on the extent of your activity of conveying
|
||||||
|
the work, and under which the third party grants, to any of the
|
||||||
|
parties who would receive the covered work from you, a discriminatory
|
||||||
|
patent license (a) in connection with copies of the covered work
|
||||||
|
conveyed by you (or copies made from those copies), or (b) primarily
|
||||||
|
for and in connection with specific products or compilations that
|
||||||
|
contain the covered work, unless you entered into that arrangement,
|
||||||
|
or that patent license was granted, prior to 28 March 2007.
|
||||||
|
|
||||||
|
Nothing in this License shall be construed as excluding or limiting
|
||||||
|
any implied license or other defenses to infringement that may
|
||||||
|
otherwise be available to you under applicable patent law.
|
||||||
|
|
||||||
|
12. No Surrender of Others' Freedom.
|
||||||
|
|
||||||
|
If conditions are imposed on you (whether by court order, agreement or
|
||||||
|
otherwise) that contradict the conditions of this License, they do not
|
||||||
|
excuse you from the conditions of this License. If you cannot convey a
|
||||||
|
covered work so as to satisfy simultaneously your obligations under this
|
||||||
|
License and any other pertinent obligations, then as a consequence you may
|
||||||
|
not convey it at all. For example, if you agree to terms that obligate you
|
||||||
|
to collect a royalty for further conveying from those to whom you convey
|
||||||
|
the Program, the only way you could satisfy both those terms and this
|
||||||
|
License would be to refrain entirely from conveying the Program.
|
||||||
|
|
||||||
|
13. Remote Network Interaction; Use with the GNU General Public License.
|
||||||
|
|
||||||
|
Notwithstanding any other provision of this License, if you modify the
|
||||||
|
Program, your modified version must prominently offer all users
|
||||||
|
interacting with it remotely through a computer network (if your version
|
||||||
|
supports such interaction) an opportunity to receive the Corresponding
|
||||||
|
Source of your version by providing access to the Corresponding Source
|
||||||
|
from a network server at no charge, through some standard or customary
|
||||||
|
means of facilitating copying of software. This Corresponding Source
|
||||||
|
shall include the Corresponding Source for any work covered by version 3
|
||||||
|
of the GNU General Public License that is incorporated pursuant to the
|
||||||
|
following paragraph.
|
||||||
|
|
||||||
|
Notwithstanding any other provision of this License, you have
|
||||||
|
permission to link or combine any covered work with a work licensed
|
||||||
|
under version 3 of the GNU General Public License into a single
|
||||||
|
combined work, and to convey the resulting work. The terms of this
|
||||||
|
License will continue to apply to the part which is the covered work,
|
||||||
|
but the work with which it is combined will remain governed by version
|
||||||
|
3 of the GNU General Public License.
|
||||||
|
|
||||||
|
14. Revised Versions of this License.
|
||||||
|
|
||||||
|
The Free Software Foundation may publish revised and/or new versions of
|
||||||
|
the GNU Affero General Public License from time to time. Such new versions
|
||||||
|
will be similar in spirit to the present version, but may differ in detail to
|
||||||
|
address new problems or concerns.
|
||||||
|
|
||||||
|
Each version is given a distinguishing version number. If the
|
||||||
|
Program specifies that a certain numbered version of the GNU Affero General
|
||||||
|
Public License "or any later version" applies to it, you have the
|
||||||
|
option of following the terms and conditions either of that numbered
|
||||||
|
version or of any later version published by the Free Software
|
||||||
|
Foundation. If the Program does not specify a version number of the
|
||||||
|
GNU Affero General Public License, you may choose any version ever published
|
||||||
|
by the Free Software Foundation.
|
||||||
|
|
||||||
|
If the Program specifies that a proxy can decide which future
|
||||||
|
versions of the GNU Affero General Public License can be used, that proxy's
|
||||||
|
public statement of acceptance of a version permanently authorizes you
|
||||||
|
to choose that version for the Program.
|
||||||
|
|
||||||
|
Later license versions may give you additional or different
|
||||||
|
permissions. However, no additional obligations are imposed on any
|
||||||
|
author or copyright holder as a result of your choosing to follow a
|
||||||
|
later version.
|
||||||
|
|
||||||
|
15. Disclaimer of Warranty.
|
||||||
|
|
||||||
|
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||||
|
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||||
|
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
||||||
|
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||||
|
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||||
|
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||||
|
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||||
|
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||||
|
|
||||||
|
16. Limitation of Liability.
|
||||||
|
|
||||||
|
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||||
|
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||||
|
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
||||||
|
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
||||||
|
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
||||||
|
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
||||||
|
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
||||||
|
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
||||||
|
SUCH DAMAGES.
|
||||||
|
|
||||||
|
17. Interpretation of Sections 15 and 16.
|
||||||
|
|
||||||
|
If the disclaimer of warranty and limitation of liability provided
|
||||||
|
above cannot be given local legal effect according to their terms,
|
||||||
|
reviewing courts shall apply local law that most closely approximates
|
||||||
|
an absolute waiver of all civil liability in connection with the
|
||||||
|
Program, unless a warranty or assumption of liability accompanies a
|
||||||
|
copy of the Program in return for a fee.
|
||||||
|
|
||||||
|
END OF TERMS AND CONDITIONS
|
||||||
196
README.md
Normal file
196
README.md
Normal file
@@ -0,0 +1,196 @@
|
|||||||
|
# youtube-local
|
||||||
|
|
||||||
|
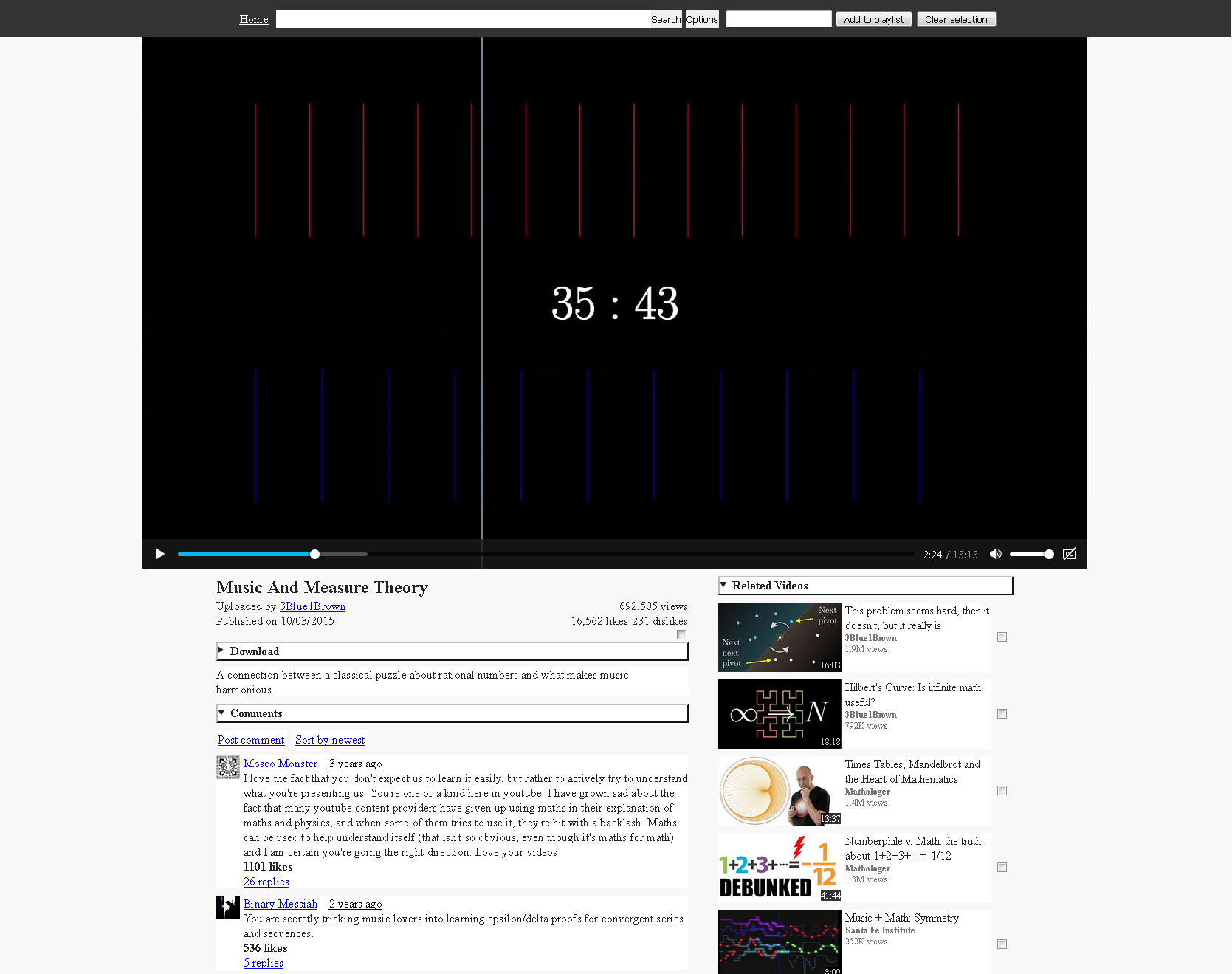
|
||||||
|
youtube-local is a browser-based client written in Python for watching Youtube anonymously and without the lag of the slow page used by Youtube. One of the primary features is that all requests are routed through Tor, except for the video file at googlevideo.com. This is analogous to what HookTube (defunct) and Invidious do, except that you do not have to trust a third-party to respect your privacy. The assumption here is that Google won't put the effort in to incorporate the video file requests into their tracking, as it's not worth pursuing the incredibly small number of users who care about privacy (Tor video routing is also provided as an option). Tor has high latency, so this will not be as fast network-wise as regular Youtube. However, using Tor is optional; when not routing through Tor, video pages may load faster than they do with Youtube's page depending on your browser.
|
||||||
|
|
||||||
|
The Youtube API is not used, so no keys or anything are needed. It uses the same requests as the Youtube webpage.
|
||||||
|
|
||||||
|
## Screenshots
|
||||||
|
[Gray theme](https://user-images.githubusercontent.com/28744867/64483431-8e1c8e80-d1b6-11e9-999c-14d36ddd582f.png)
|
||||||
|
|
||||||
|
[Dark theme](https://user-images.githubusercontent.com/28744867/64483432-8fe65200-d1b6-11e9-90bd-32869542e32e.png)
|
||||||
|
|
||||||
|
[Non-Theater mode](https://user-images.githubusercontent.com/28744867/64483433-92e14280-d1b6-11e9-9b56-2ef5d64c372f.png)
|
||||||
|
|
||||||
|
[Channel](https://user-images.githubusercontent.com/28744867/64483436-95dc3300-d1b6-11e9-8efc-b19b1f1f3bcf.png)
|
||||||
|
|
||||||
|
[Downloads](https://user-images.githubusercontent.com/28744867/64483437-a2608b80-d1b6-11e9-9e5a-4114391b7304.png)
|
||||||
|
|
||||||
|
## Features
|
||||||
|
* Standard pages of Youtube: search, channels, playlists
|
||||||
|
* Anonymity from Google's tracking by routing requests through Tor
|
||||||
|
* Local playlists: These solve the two problems with creating playlists on Youtube: (1) they're datamined and (2) videos frequently get deleted by Youtube and lost from the playlist, making it very difficult to find a reupload as the title of the deleted video is not displayed.
|
||||||
|
* Themes: Light, Gray, and Dark
|
||||||
|
* Subtitles
|
||||||
|
* Easily download videos or their audio
|
||||||
|
* No ads
|
||||||
|
* View comments
|
||||||
|
* Javascript not required
|
||||||
|
* Theater and non-theater mode
|
||||||
|
* Subscriptions that are independent from Youtube
|
||||||
|
* Can import subscriptions from Youtube
|
||||||
|
* Works by checking channels individually
|
||||||
|
* Can be set to automatically check channels.
|
||||||
|
* For efficiency of requests, frequency of checking is based on how quickly channel posts videos
|
||||||
|
* Can mute channels, so as to have a way to "soft" unsubscribe. Muted channels won't be checked automatically or when using the "Check all" button. Videos from these channels will be hidden.
|
||||||
|
* Can tag subscriptions to organize them or check specific tags
|
||||||
|
* Fast page
|
||||||
|
* No distracting/slow layout rearrangement
|
||||||
|
* No lazy-loading of comments; they are ready instantly.
|
||||||
|
* Settings allow fine-tuned control over when/how comments or related videos are shown:
|
||||||
|
1. Shown by default, with click to hide
|
||||||
|
2. Hidden by default, with click to show
|
||||||
|
3. Never shown
|
||||||
|
* Optionally skip sponsored segments using [SponsorBlock](https://github.com/ajayyy/SponsorBlock)'s API
|
||||||
|
* Custom video speeds
|
||||||
|
* Video transcript
|
||||||
|
* Supports all available video qualities: 144p through 2160p
|
||||||
|
|
||||||
|
## Planned features
|
||||||
|
- [ ] Putting videos from subscriptions or local playlists into the related videos
|
||||||
|
- [x] Information about video (geographic regions, region of Tor exit node, etc)
|
||||||
|
- [ ] Ability to delete playlists
|
||||||
|
- [ ] Auto-saving of local playlist videos
|
||||||
|
- [ ] Import youtube playlist into a local playlist
|
||||||
|
- [ ] Rearrange items of local playlist
|
||||||
|
- [x] Video qualities other than 360p and 720p by muxing video and audio
|
||||||
|
- [ ] Corrected .m4a downloads
|
||||||
|
- [x] Indicate if comments are disabled
|
||||||
|
- [x] Indicate how many comments a video has
|
||||||
|
- [ ] Featured channels page
|
||||||
|
- [ ] Channel comments
|
||||||
|
- [x] Video transcript
|
||||||
|
- [x] Automatic Tor circuit change when blocked
|
||||||
|
- [x] Support &t parameter
|
||||||
|
- [ ] Subscriptions: Option to mark what has been watched
|
||||||
|
- [ ] Subscriptions: Option to filter videos based on keywords in title or description
|
||||||
|
- [ ] Subscriptions: Delete old entries and thumbnails
|
||||||
|
- [ ] Support for more sites, such as Vimeo, Dailymotion, LBRY, etc.
|
||||||
|
|
||||||
|
## Installing
|
||||||
|
|
||||||
|
### Windows
|
||||||
|
|
||||||
|
Download the zip file under the Releases page. Unzip it anywhere you choose.
|
||||||
|
|
||||||
|
### Linux/MacOS
|
||||||
|
|
||||||
|
Download the tarball under the Releases page and extract it. `cd` into the directory and run
|
||||||
|
```
|
||||||
|
pip3 install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
**Note**: If pip isn't installed, first try installing it from your package manager. Make sure you install pip for python 3. For example, the package you need on debian is python3-pip rather than python-pip. If your package manager doesn't provide it, try to install it according to [this answer](https://unix.stackexchange.com/a/182467), but make sure you run `python3 get-pip.py` instead of `python get-pip.py`
|
||||||
|
|
||||||
|
- Arch users can use the [AUR package](https://aur.archlinux.org/packages/youtube-local-git) maintained by @ByJumperX4
|
||||||
|
- RPM-based distros such as Fedora/OpenSUSE/RHEL/CentOS can use the [COPR package](https://copr.fedorainfracloud.org/coprs/anarcoco/youtube-local) maintained by @ByJumperX4
|
||||||
|
|
||||||
|
|
||||||
|
### FreeBSD
|
||||||
|
|
||||||
|
If pip isn't installed, first try installing it from the package manager:
|
||||||
|
```
|
||||||
|
pkg install py39-pip
|
||||||
|
```
|
||||||
|
|
||||||
|
Some packages are unable to compile with pip, install them manually:
|
||||||
|
```
|
||||||
|
pkg install py39-gevent py39-sqlite3
|
||||||
|
```
|
||||||
|
|
||||||
|
Download the tarball under the Releases page and extract it. `cd` into the directory and run
|
||||||
|
```
|
||||||
|
pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
**Note**: You may have to start the server redirecting its output to /dev/null to avoid I/O errors:
|
||||||
|
```
|
||||||
|
python3 ./server.py > /dev/null 2>&1 &
|
||||||
|
```
|
||||||
|
|
||||||
|
## Usage
|
||||||
|
|
||||||
|
To run the program on windows, open `run.bat`. On Linux/MacOS, run `python3 server.py`.
|
||||||
|
|
||||||
|
**Note for Mac users**: If you installed Python from the installer on python.org, you will need to have run the file `Install Certificates.command` in the directory `Applications/Python 3.x` where `x` is the minor version of python. Otherwise, you will get the error `certificate verify failed: unable to get local issuer certificate`. There is a similar file in that directory you can run to get the `python3` command installed for the terminal.
|
||||||
|
|
||||||
|
To run it at startup on Windows, right click `run.bat` and click "Create Shortcut." Then, move the shortcut to the Startup folder. You can access the Startup folder by pressing `Windows Key + R` and typing `shell:startup`.
|
||||||
|
|
||||||
|
|
||||||
|
Access youtube URLs by prefixing them with `http://localhost:8080/`, For instance, `http://localhost:8080/https://www.youtube.com/watch?v=vBgulDeV2RU`
|
||||||
|
You can use an addon such as Redirector ([Firefox](https://addons.mozilla.org/en-US/firefox/addon/redirector/)|[Chrome](https://chrome.google.com/webstore/detail/redirector/ocgpenflpmgnfapjedencafcfakcekcd)) to automatically redirect Youtube URLs to youtube-local. I use the include pattern `^(https?://(?:[a-zA-Z0-9_-]*\.)?(?:youtube\.com|youtu\.be|youtube-nocookie\.com)/.*)` and the redirect pattern `http://localhost:8080/$1` (Make sure you're using regular expression mode).
|
||||||
|
|
||||||
|
If you want embeds on the web to also redirect to youtube-local, make sure "Iframes" is checked under advanced options in your redirector rule.
|
||||||
|
|
||||||
|
youtube-local can be added as a search engine in firefox to make searching more convenient. See [here](https://support.mozilla.org/en-US/kb/add-or-remove-search-engine-firefox) for information on firefox search plugins.
|
||||||
|
|
||||||
|
### Portable mode
|
||||||
|
|
||||||
|
If you wish to run this in portable mode, create the empty file "settings.txt" in the program's main directory. If the file is there, settings and data will be stored in the same directory as the program. Otherwise, settings and data will be stored in `C:\Users\[your username]\.youtube-local` on Windows and `~/.youtube-local` on Linux/MacOS.
|
||||||
|
|
||||||
|
### Using Tor
|
||||||
|
|
||||||
|
In the settings page, set "Route Tor" to "On, except video" (the second option). Be sure to save the settings.
|
||||||
|
|
||||||
|
Ensure Tor is listening for Socks5 connections on port 9150. A simple way to accomplish this is by opening the Tor Browser Bundle and leaving it open. However, you will not be accessing the program (at https://localhost:8080) through the Tor Browser. You will use your regular browser for that. Rather, this is just a quick way to give the program access to Tor routing.
|
||||||
|
|
||||||
|
### Standalone Tor
|
||||||
|
|
||||||
|
If you don't want to waste system resources leaving the Tor Browser open in addition to your regular browser, you can configure standalone Tor to run instead using the following instructions.
|
||||||
|
|
||||||
|
For Windows, to make standalone Tor run at startup, press Windows Key + R and type `shell:startup` to open the Startup folder. Create a new shortcut there. For the command of the shortcut, enter `"C:\[path-to-Tor-Browser-directory]\Tor\tor.exe" SOCKSPort 9150 ControlPort 9151`. You can then launch this shortcut to start it. Alternatively, if something isn't working, to see what's wrong, open `cmd.exe` and go to the directory `C:\[path-to-Tor-Browser-directory]\Tor`. Then run `tor SOCKSPort 9150 ControlPort 9151 | more`. The `more` part at the end is just to make sure any errors are displayed, to fix a bug in Windows cmd where tor doesn't display any output. You can stop tor in the task manager.
|
||||||
|
|
||||||
|
For Debian/Ubuntu, you can `sudo apt install tor` to install the command line version of Tor, and then run `sudo systemctl start tor` to run it as a background service that will get started during boot as well. However, Tor on the command line uses the port 9050 by default (rather than the 9150 used by the Tor Browser). So you will need to change `Tor port` to 9050 and `Tor control port` to 9051 in the youtube-local settings page. Additionally, you will need to enable the Tor control port by uncommenting the line `ControlPort 9051`, and setting `CookieAuthentication` to 0 in `/etc/tor/torrc`. If no Tor package is available for your distro, you can configure the `tor` binary located at `./Browser/TorBrowser/Tor/tor` inside the Tor Browser installation location to run at start time, or create a service to do it.
|
||||||
|
|
||||||
|
### Tor video routing
|
||||||
|
|
||||||
|
If you wish to route the video through Tor, set "Route Tor" to "On, including video". Because this is bandwidth-intensive, you are strongly encouraged to donate to the [consortium of Tor node operators](https://torservers.net/donate.html). For instance, donations to [NoiseTor](https://noisetor.net/) go straight towards funding nodes. Using their numbers for bandwidth costs, together with an average of 485 kbit/sec for a diverse sample of videos, and assuming n hours of video watched per day, gives $0.03n/month. A $1/month donation will be a very generous amount to not only offset losses, but help keep the network healthy.
|
||||||
|
|
||||||
|
In general, Tor video routing will be slower (for instance, moving around in the video is quite slow). I've never seen any signs that watch history in youtube-local affects on-site Youtube recommendations. It's likely that requests to googlevideo are logged for some period of time, but are not integrated into Youtube's larger advertisement/recommendation systems, since those presumably depend more heavily on in-page tracking through Javascript rather than CDN requests to googlevideo.
|
||||||
|
|
||||||
|
### Importing subscriptions
|
||||||
|
|
||||||
|
1. Go to the [Google takeout manager](https://takeout.google.com/takeout/custom/youtube).
|
||||||
|
2. Log in if asked.
|
||||||
|
3. Click on "All data included", then on "Deselect all", then select only "subscriptions" and click "OK".
|
||||||
|
4. Click on "Next step" and then on "Create export".
|
||||||
|
5. Click on the "Download" button after it appears.
|
||||||
|
6. From the downloaded takeout zip extract the .csv file. It is usually located under `YouTube and YouTube Music/subscriptions/subscriptions.csv`
|
||||||
|
7. Go to the subscriptions manager in youtube-local. In the import area, select your .csv file, then press import.
|
||||||
|
|
||||||
|
Supported subscriptions import formats:
|
||||||
|
- NewPipe subscriptions export JSON
|
||||||
|
- Google Takeout CSV
|
||||||
|
- Old Google Takeout JSON
|
||||||
|
- OPML format from now-removed YouTube subscriptions manager
|
||||||
|
|
||||||
|
## Contributing
|
||||||
|
|
||||||
|
Pull requests and issues are welcome
|
||||||
|
|
||||||
|
For coding guidelines and an overview of the software architecture, see the HACKING.md file.
|
||||||
|
|
||||||
|
## License
|
||||||
|
|
||||||
|
This project is licensed under the GNU Affero General Public License v3 (GNU AGPLv3) or any later version.
|
||||||
|
|
||||||
|
Permission is hereby granted to the youtube-dl project at [https://github.com/ytdl-org/youtube-dl](https://github.com/ytdl-org/youtube-dl) to relicense any portion of this software under the Unlicense, public domain, or whichever license is in use by youtube-dl at the time of relicensing, for the purpose of inclusion of said portion into youtube-dl. Relicensing permission is not granted for any purpose outside of direct inclusion into the [official repository](https://github.com/ytdl-org/youtube-dl) of youtube-dl. If inclusion happens during the process of a pull-request, relicensing happens at the moment the pull request is merged into youtube-dl; until that moment, any cloned repositories of youtube-dl which make use of this software are subject to the terms of the GNU AGPLv3.
|
||||||
|
|
||||||
|
## Donate
|
||||||
|
|
||||||
|
- Bitcoin: bc1qnxfm8mk2gdcdr56308794a4f97dd7wu6qawguw
|
||||||
|
- Monero: 469tczUEVTX6Y7bMEgTyrUJ2K7R8qVNjn5eh5VVHKvi4QsbMD7vrFW8RaCqM1jmZMR9GM87yByvPKZb8gsSxUzrdGCM1yXv
|
||||||
|
- Ethereum: 0x04828FFa6fa8F68535A22153300e50AfCDC342C4
|
||||||
|
|
||||||
|
## Similar projects
|
||||||
|
- [invidious](https://github.com/iv-org/invidious) Similar to this project, but also allows it to be hosted as a server to serve many users
|
||||||
|
- [Yotter](https://github.com/ytorg/Yotter) Similar to this project and to invidious. Also supports Twitter
|
||||||
|
- [FreeTube](https://github.com/FreeTubeApp/FreeTube) (Similar to this project, but is an electron app outside the browser)
|
||||||
|
- [yt-local](https://git.sr.ht/~heckyel/yt-local) Fork of this project with a different page design
|
||||||
|
- [NewPipe](https://newpipe.schabi.org/) (app for android)
|
||||||
|
- [mps-youtube](https://github.com/mps-youtube/mps-youtube) (terminal-only program)
|
||||||
|
- [youtube-viewer](https://github.com/trizen/youtube-viewer)
|
||||||
|
- [smtube](https://www.smtube.org/)
|
||||||
|
- [Minitube](https://flavio.tordini.org/minitube), [github here](https://github.com/flaviotordini/minitube)
|
||||||
|
- [toogles](https://github.com/mikecrittenden/toogles) (only embeds videos, doesn't use mp4)
|
||||||
|
- [youtube-dl](https://rg3.github.io/youtube-dl/), which this project was based off
|
||||||
247
generate_release.py
Normal file
247
generate_release.py
Normal file
@@ -0,0 +1,247 @@
|
|||||||
|
# Generate a windows release and a generated embedded distribution of python
|
||||||
|
# Latest python version is the argument of the script (or oldwin for
|
||||||
|
# vista, 7 and 32-bit versions)
|
||||||
|
# Requirements: 7z, git
|
||||||
|
# wine is required in order to build on Linux
|
||||||
|
|
||||||
|
import sys
|
||||||
|
import urllib
|
||||||
|
import urllib.request
|
||||||
|
import subprocess
|
||||||
|
import shutil
|
||||||
|
import os
|
||||||
|
import hashlib
|
||||||
|
|
||||||
|
latest_version = sys.argv[1]
|
||||||
|
if len(sys.argv) > 2:
|
||||||
|
bitness = sys.argv[2]
|
||||||
|
else:
|
||||||
|
bitness = '64'
|
||||||
|
|
||||||
|
if latest_version == 'oldwin':
|
||||||
|
bitness = '32'
|
||||||
|
latest_version = '3.7.9'
|
||||||
|
suffix = 'windows-vista-7-only'
|
||||||
|
else:
|
||||||
|
suffix = 'windows'
|
||||||
|
|
||||||
|
def check(code):
|
||||||
|
if code != 0:
|
||||||
|
raise Exception('Got nonzero exit code from command')
|
||||||
|
def check_subp(x):
|
||||||
|
if x.returncode != 0:
|
||||||
|
raise Exception('Got nonzero exit code from command')
|
||||||
|
|
||||||
|
def log(line):
|
||||||
|
print('[generate_release.py] ' + line)
|
||||||
|
|
||||||
|
# https://stackoverflow.com/questions/7833715/python-deleting-certain-file-extensions
|
||||||
|
def remove_files_with_extensions(path, extensions):
|
||||||
|
for root, dirs, files in os.walk(path):
|
||||||
|
for file in files:
|
||||||
|
if os.path.splitext(file)[1] in extensions:
|
||||||
|
os.remove(os.path.join(root, file))
|
||||||
|
|
||||||
|
def download_if_not_exists(file_name, url, sha256=None):
|
||||||
|
if not os.path.exists('./' + file_name):
|
||||||
|
log('Downloading ' + file_name + '..')
|
||||||
|
data = urllib.request.urlopen(url).read()
|
||||||
|
log('Finished downloading ' + file_name)
|
||||||
|
with open('./' + file_name, 'wb') as f:
|
||||||
|
f.write(data)
|
||||||
|
if sha256:
|
||||||
|
digest = hashlib.sha256(data).hexdigest()
|
||||||
|
if digest != sha256:
|
||||||
|
log('Error: ' + file_name + ' has wrong hash: ' + digest)
|
||||||
|
sys.exit(1)
|
||||||
|
else:
|
||||||
|
log('Using existing ' + file_name)
|
||||||
|
|
||||||
|
def wine_run_shell(command):
|
||||||
|
if os.name == 'posix':
|
||||||
|
check(os.system('wine ' + command.replace('\\', '/')))
|
||||||
|
elif os.name == 'nt':
|
||||||
|
check(os.system(command))
|
||||||
|
else:
|
||||||
|
raise Exception('Unsupported OS')
|
||||||
|
|
||||||
|
def wine_run(command_parts):
|
||||||
|
if os.name == 'posix':
|
||||||
|
command_parts = ['wine',] + command_parts
|
||||||
|
if subprocess.run(command_parts).returncode != 0:
|
||||||
|
raise Exception('Got nonzero exit code from command')
|
||||||
|
|
||||||
|
# ---------- Get current release version, for later ----------
|
||||||
|
log('Getting current release version')
|
||||||
|
describe_result = subprocess.run(['git', 'describe', '--tags'], stdout=subprocess.PIPE)
|
||||||
|
if describe_result.returncode != 0:
|
||||||
|
raise Exception('Git describe failed')
|
||||||
|
|
||||||
|
release_tag = describe_result.stdout.strip().decode('ascii')
|
||||||
|
|
||||||
|
|
||||||
|
# ----------- Make copy of youtube-local files using git -----------
|
||||||
|
|
||||||
|
if os.path.exists('./youtube-local'):
|
||||||
|
log('Removing old release')
|
||||||
|
shutil.rmtree('./youtube-local')
|
||||||
|
|
||||||
|
# Export git repository - this will ensure .git and things in gitignore won't
|
||||||
|
# be included. Git only supports exporting archive formats, not into
|
||||||
|
# directories, so pipe into 7z to put it into .\youtube-local (not to be
|
||||||
|
# confused with working directory. I'm calling it the same thing so it will
|
||||||
|
# have that name when extracted from the final release zip archive)
|
||||||
|
log('Making copy of youtube-local files')
|
||||||
|
check(os.system('git archive --format tar master | 7z x -si -ttar -oyoutube-local'))
|
||||||
|
|
||||||
|
if len(os.listdir('./youtube-local')) == 0:
|
||||||
|
raise Exception('Failed to copy youtube-local files')
|
||||||
|
|
||||||
|
|
||||||
|
# ----------- Generate embedded python distribution -----------
|
||||||
|
os.environ['PYTHONDONTWRITEBYTECODE'] = '1' # *.pyc files double the size of the distribution
|
||||||
|
get_pip_url = 'https://bootstrap.pypa.io/get-pip.py'
|
||||||
|
latest_dist_url = 'https://www.python.org/ftp/python/' + latest_version + '/python-' + latest_version
|
||||||
|
if bitness == '32':
|
||||||
|
latest_dist_url += '-embed-win32.zip'
|
||||||
|
else:
|
||||||
|
latest_dist_url += '-embed-amd64.zip'
|
||||||
|
|
||||||
|
# I've verified that all the dlls in the following are signed by Microsoft.
|
||||||
|
# Using this because Microsoft only provides installers whose files can't be
|
||||||
|
# extracted without a special tool.
|
||||||
|
if bitness == '32':
|
||||||
|
visual_c_runtime_url = 'https://github.com/yuempek/vc-archive/raw/master/archives/vc15_(14.10.25017.0)_2017_x86.7z'
|
||||||
|
visual_c_runtime_sha256 = '2549eb4d2ce4cf3a87425ea01940f74368bf1cda378ef8a8a1f1a12ed59f1547'
|
||||||
|
visual_c_name = 'vc15_(14.10.25017.0)_2017_x86.7z'
|
||||||
|
visual_c_path_to_dlls = 'runtime_minimum/System'
|
||||||
|
else:
|
||||||
|
visual_c_runtime_url = 'https://github.com/yuempek/vc-archive/raw/master/archives/vc15_(14.10.25017.0)_2017_x64.7z'
|
||||||
|
visual_c_runtime_sha256 = '4f00b824c37e1017a93fccbd5775e6ee54f824b6786f5730d257a87a3d9ce921'
|
||||||
|
visual_c_name = 'vc15_(14.10.25017.0)_2017_x64.7z'
|
||||||
|
visual_c_path_to_dlls = 'runtime_minimum/System64'
|
||||||
|
|
||||||
|
download_if_not_exists('get-pip.py', get_pip_url)
|
||||||
|
|
||||||
|
python_dist_name = 'python-dist-' + latest_version + '-' + bitness + '.zip'
|
||||||
|
|
||||||
|
download_if_not_exists(python_dist_name, latest_dist_url)
|
||||||
|
download_if_not_exists(visual_c_name,
|
||||||
|
visual_c_runtime_url, sha256=visual_c_runtime_sha256)
|
||||||
|
|
||||||
|
if os.path.exists('./python'):
|
||||||
|
log('Removing old python distribution')
|
||||||
|
shutil.rmtree('./python')
|
||||||
|
|
||||||
|
|
||||||
|
log('Extracting python distribution')
|
||||||
|
|
||||||
|
check(os.system(r'7z -y x -opython ' + python_dist_name))
|
||||||
|
|
||||||
|
log('Executing get-pip.py')
|
||||||
|
wine_run(['./python/python.exe', '-I', 'get-pip.py'])
|
||||||
|
|
||||||
|
'''
|
||||||
|
# Explanation of .pth, ._pth, and isolated mode
|
||||||
|
|
||||||
|
## Isolated mode
|
||||||
|
We want to run in what is called isolated mode, given by the switch -I.
|
||||||
|
This mode prevents the embedded python distribution from searching in
|
||||||
|
global directories for imports
|
||||||
|
|
||||||
|
For example, if a user has `C:\Python37` and the embedded distribution is
|
||||||
|
the same version, importing something using the embedded distribution will
|
||||||
|
search `C:\Python37\Libs\site-packages`. This is not desirable because it
|
||||||
|
means I might forget to distribute a dependency if I have it installed
|
||||||
|
globally and I don't see any import errors. It also means that an outdated
|
||||||
|
package might override the one being distributed and cause other problems.
|
||||||
|
|
||||||
|
Isolated mode also means global environment variables and registry
|
||||||
|
entries will be ignored
|
||||||
|
|
||||||
|
## The trouble with isolated mode
|
||||||
|
Isolated mode also prevents the current working directory (cwd) from
|
||||||
|
being added to `sys.path`. `sys.path` is the list of directories python will
|
||||||
|
search in for imports. In non-isolated mode this is automatically populated
|
||||||
|
with the cwd, `site-packages`, the directory of the python executable, etc.
|
||||||
|
|
||||||
|
# How to get the cwd into sys.path in isolated mode
|
||||||
|
The hack to get this to work is to use a .pth file. Normally, these files
|
||||||
|
are just an additional list of directories to be added to `sys.path`.
|
||||||
|
However, they also allow arbitrary code execution on lines beginning with
|
||||||
|
`import ` (see https://docs.python.org/3/library/site.html). So, we simply
|
||||||
|
add `import sys; sys.path.insert(0, '')` to add the cwd to path. `''` is
|
||||||
|
shorthand for the cwd. See https://bugs.python.org/issue33698#msg318272
|
||||||
|
|
||||||
|
# ._pth files in the embedded distribution
|
||||||
|
A python37._pth file is included in the embedded distribution. The presence
|
||||||
|
of tis file causes the embedded distribution to always use isolated mode
|
||||||
|
(which we want). They are like .pth files, except they do not allow the
|
||||||
|
arbitrary code execution trick. In my experimentation, I found that they
|
||||||
|
prevent .pth files from loading. So the ._pth file will have to be removed
|
||||||
|
and replaced with a .pth. Isolated mode will have to be specified manually.
|
||||||
|
'''
|
||||||
|
|
||||||
|
log('Removing ._pth')
|
||||||
|
major_release = latest_version.split('.')[1]
|
||||||
|
os.remove(r'./python/python3' + major_release + '._pth')
|
||||||
|
|
||||||
|
log('Adding path_fixes.pth')
|
||||||
|
with open(r'./python/path_fixes.pth', 'w', encoding='utf-8') as f:
|
||||||
|
f.write("import sys; sys.path.insert(0, '')\n")
|
||||||
|
|
||||||
|
|
||||||
|
'''# python3x._pth file tells the python executable where to look for files
|
||||||
|
# Need to add the directory where packages are installed,
|
||||||
|
# and the parent directory (which is where the youtube-local files are)
|
||||||
|
major_release = latest_version.split('.')[1]
|
||||||
|
with open('./python/python3' + major_release + '._pth', 'a', encoding='utf-8') as f:
|
||||||
|
f.write('.\\Lib\\site-packages\n')
|
||||||
|
f.write('..\n')'''
|
||||||
|
|
||||||
|
log('Inserting Microsoft C Runtime')
|
||||||
|
check_subp(subprocess.run([r'7z', '-y', 'e', '-opython', visual_c_name, visual_c_path_to_dlls]))
|
||||||
|
|
||||||
|
log('Installing dependencies')
|
||||||
|
wine_run(['./python/python.exe', '-I', '-m', 'pip', 'install', '--no-compile', '-r', './requirements.txt'])
|
||||||
|
|
||||||
|
log('Uninstalling unnecessary gevent stuff')
|
||||||
|
wine_run(['./python/python.exe', '-I', '-m', 'pip', 'uninstall', '--yes', 'cffi', 'pycparser'])
|
||||||
|
shutil.rmtree(r'./python/Lib/site-packages/gevent/tests')
|
||||||
|
shutil.rmtree(r'./python/Lib/site-packages/gevent/testing')
|
||||||
|
remove_files_with_extensions(r'./python/Lib/site-packages/gevent', ['.html']) # bloated html documentation
|
||||||
|
|
||||||
|
log('Uninstalling pip and others')
|
||||||
|
wine_run(['./python/python.exe', '-I', '-m', 'pip', 'uninstall', '--yes', 'pip', 'wheel'])
|
||||||
|
|
||||||
|
log('Removing pyc files') # Have to do this because get-pip and some packages don't respect --no-compile
|
||||||
|
remove_files_with_extensions(r'./python', ['.pyc'])
|
||||||
|
|
||||||
|
log('Removing dist-info and __pycache__')
|
||||||
|
for root, dirs, files in os.walk(r'./python'):
|
||||||
|
for dir in dirs:
|
||||||
|
if dir == '__pycache__' or dir.endswith('.dist-info'):
|
||||||
|
shutil.rmtree(os.path.join(root, dir))
|
||||||
|
|
||||||
|
|
||||||
|
'''log('Removing get-pip.py and zipped distribution')
|
||||||
|
os.remove(r'.\get-pip.py')
|
||||||
|
os.remove(r'.\latest-dist.zip')'''
|
||||||
|
|
||||||
|
print()
|
||||||
|
log('Finished generating python distribution')
|
||||||
|
|
||||||
|
# ----------- Copy generated distribution into release folder -----------
|
||||||
|
log('Copying python distribution into release folder')
|
||||||
|
shutil.copytree(r'./python', r'./youtube-local/python')
|
||||||
|
|
||||||
|
# ----------- Create release zip -----------
|
||||||
|
output_filename = 'youtube-local-' + release_tag + '-' + suffix + '.zip'
|
||||||
|
if os.path.exists('./' + output_filename):
|
||||||
|
log('Removing previous zipped release')
|
||||||
|
os.remove('./' + output_filename)
|
||||||
|
log('Zipping release')
|
||||||
|
check(os.system(r'7z -mx=9 a ' + output_filename + ' ./youtube-local'))
|
||||||
|
|
||||||
|
print('\n')
|
||||||
|
log('Finished')
|
||||||
1
pax_global_header
Normal file
1
pax_global_header
Normal file
@@ -0,0 +1 @@
|
|||||||
|
52 comment=f9306ca0c7c3c154dab16ec9ea1a2a3393a31e93
|
||||||
4
pytest.ini
Normal file
4
pytest.ini
Normal file
@@ -0,0 +1,4 @@
|
|||||||
|
# pytest.ini
|
||||||
|
[pytest]
|
||||||
|
testpaths =
|
||||||
|
tests
|
||||||
1
requirements-dev.txt
Normal file
1
requirements-dev.txt
Normal file
@@ -0,0 +1 @@
|
|||||||
|
pytest>=6.2.1
|
||||||
8
requirements.txt
Normal file
8
requirements.txt
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
Flask>=1.0.3
|
||||||
|
gevent>=1.2.2
|
||||||
|
Brotli>=1.0.7
|
||||||
|
PySocks>=1.6.8
|
||||||
|
urllib3>=1.24.1
|
||||||
|
defusedxml>=0.5.0
|
||||||
|
cachetools>=4.0.0
|
||||||
|
stem>=1.8.0
|
||||||
18
run.bat
Normal file
18
run.bat
Normal file
@@ -0,0 +1,18 @@
|
|||||||
|
@echo off
|
||||||
|
|
||||||
|
REM https://stackoverflow.com/a/25719250
|
||||||
|
REM setlocal makes sure changing directory only applies inside this bat file,
|
||||||
|
REM and not in the command shell.
|
||||||
|
setlocal
|
||||||
|
|
||||||
|
REM So this bat file can be called from a different working directory.
|
||||||
|
REM %~dp0 is the directory with this bat file.
|
||||||
|
cd /d "%~dp0"
|
||||||
|
|
||||||
|
REM This is so brotli and gevent search in the python directory for the
|
||||||
|
REM visual studio c++ runtime dlls
|
||||||
|
set PATH=.\python;%PATH%
|
||||||
|
|
||||||
|
.\python\python.exe -I .\server.py
|
||||||
|
echo Press any key to quit...
|
||||||
|
PAUSE > nul
|
||||||
284
server.py
Normal file
284
server.py
Normal file
@@ -0,0 +1,284 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
from gevent import monkey
|
||||||
|
monkey.patch_all()
|
||||||
|
import gevent.socket
|
||||||
|
|
||||||
|
from youtube import yt_app
|
||||||
|
from youtube import util
|
||||||
|
|
||||||
|
# these are just so the files get run - they import yt_app and add routes to it
|
||||||
|
from youtube import watch, search, playlist, channel, local_playlist, comments, subscriptions
|
||||||
|
|
||||||
|
import settings
|
||||||
|
|
||||||
|
from gevent.pywsgi import WSGIServer
|
||||||
|
import urllib
|
||||||
|
import urllib3
|
||||||
|
import socket
|
||||||
|
import socks, sockshandler
|
||||||
|
import subprocess
|
||||||
|
import re
|
||||||
|
import sys
|
||||||
|
import time
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def youtu_be(env, start_response):
|
||||||
|
id = env['PATH_INFO'][1:]
|
||||||
|
env['PATH_INFO'] = '/watch'
|
||||||
|
if not env['QUERY_STRING']:
|
||||||
|
env['QUERY_STRING'] = 'v=' + id
|
||||||
|
else:
|
||||||
|
env['QUERY_STRING'] += '&v=' + id
|
||||||
|
yield from yt_app(env, start_response)
|
||||||
|
|
||||||
|
RANGE_RE = re.compile(r'bytes=(\d+-(?:\d+)?)')
|
||||||
|
def parse_range(range_header, content_length):
|
||||||
|
# Range header can be like bytes=200-1000 or bytes=200-
|
||||||
|
# amount_received is the length of bytes from the range that have already
|
||||||
|
# been received
|
||||||
|
match = RANGE_RE.fullmatch(range_header.strip())
|
||||||
|
if not match:
|
||||||
|
print('Unsupported range header format:', range_header)
|
||||||
|
return None
|
||||||
|
start, end = match.group(1).split('-')
|
||||||
|
start_byte = int(start)
|
||||||
|
if not end:
|
||||||
|
end_byte = start_byte + content_length - 1
|
||||||
|
else:
|
||||||
|
end_byte = int(end)
|
||||||
|
return start_byte, end_byte
|
||||||
|
|
||||||
|
def proxy_site(env, start_response, video=False):
|
||||||
|
send_headers = {
|
||||||
|
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)',
|
||||||
|
'Accept': '*/*',
|
||||||
|
}
|
||||||
|
current_range_start = 0
|
||||||
|
range_end = None
|
||||||
|
if 'HTTP_RANGE' in env:
|
||||||
|
send_headers['Range'] = env['HTTP_RANGE']
|
||||||
|
|
||||||
|
url = "https://" + env['SERVER_NAME'] + env['PATH_INFO']
|
||||||
|
# remove /name portion
|
||||||
|
if video and '/videoplayback/name/' in url:
|
||||||
|
url = url[0:url.rfind('/name/')]
|
||||||
|
if env['QUERY_STRING']:
|
||||||
|
url += '?' + env['QUERY_STRING']
|
||||||
|
|
||||||
|
try_num = 1
|
||||||
|
first_attempt = True
|
||||||
|
current_attempt_position = 0
|
||||||
|
while try_num <= 3: # Try a given byte position three times
|
||||||
|
if not first_attempt:
|
||||||
|
print('(Try %d)' % try_num, 'Trying with', send_headers['Range'])
|
||||||
|
|
||||||
|
if video:
|
||||||
|
params = urllib.parse.parse_qs(env['QUERY_STRING'])
|
||||||
|
params_use_tor = int(params.get('use_tor', '0')[0])
|
||||||
|
use_tor = (settings.route_tor == 2) or params_use_tor
|
||||||
|
response, cleanup_func = util.fetch_url_response(url, send_headers,
|
||||||
|
use_tor=use_tor,
|
||||||
|
max_redirects=10)
|
||||||
|
else:
|
||||||
|
response, cleanup_func = util.fetch_url_response(url, send_headers)
|
||||||
|
|
||||||
|
response_headers = response.headers
|
||||||
|
#if isinstance(response_headers, urllib3._collections.HTTPHeaderDict):
|
||||||
|
# response_headers = response_headers.items()
|
||||||
|
try:
|
||||||
|
response_headers = list(response_headers.items())
|
||||||
|
except AttributeError:
|
||||||
|
pass
|
||||||
|
if video:
|
||||||
|
response_headers = (list(response_headers)
|
||||||
|
+[('Access-Control-Allow-Origin', '*')])
|
||||||
|
|
||||||
|
if first_attempt:
|
||||||
|
start_response(str(response.status) + ' ' + response.reason,
|
||||||
|
response_headers)
|
||||||
|
|
||||||
|
content_length = int(dict(response_headers).get('Content-Length', 0))
|
||||||
|
if response.status >= 400:
|
||||||
|
print('Error: Youtube returned "%d %s" while routing %s' % (
|
||||||
|
response.status, response.reason, url.split('?')[0]))
|
||||||
|
|
||||||
|
total_received = 0
|
||||||
|
retry = False
|
||||||
|
while True:
|
||||||
|
# a bit over 3 seconds of 360p video
|
||||||
|
# we want each TCP packet to transmit in large multiples,
|
||||||
|
# such as 65,536, so we shouldn't read in small chunks
|
||||||
|
# such as 8192 lest that causes the socket library to limit the
|
||||||
|
# TCP window size
|
||||||
|
# Might need fine-tuning, since this gives us 4*65536
|
||||||
|
# The tradeoff is that larger values (such as 6 seconds) only
|
||||||
|
# allows video to buffer in those increments, meaning user must
|
||||||
|
# wait until the entire chunk is downloaded before video starts
|
||||||
|
# playing
|
||||||
|
content_part = response.read(32*8192)
|
||||||
|
total_received += len(content_part)
|
||||||
|
if not content_part:
|
||||||
|
# Sometimes Youtube closes the connection before sending all of
|
||||||
|
# the content. Retry with a range request for the missing
|
||||||
|
# content. See
|
||||||
|
# https://github.com/user234683/youtube-local/issues/40
|
||||||
|
if total_received < content_length:
|
||||||
|
if 'Range' in send_headers:
|
||||||
|
int_range = parse_range(send_headers['Range'],
|
||||||
|
content_length)
|
||||||
|
if not int_range: # give up b/c unrecognized range
|
||||||
|
break
|
||||||
|
start, end = int_range
|
||||||
|
else:
|
||||||
|
start, end = 0, (content_length - 1)
|
||||||
|
|
||||||
|
fail_byte = start + total_received
|
||||||
|
send_headers['Range'] = 'bytes=%d-%d' % (fail_byte, end)
|
||||||
|
print(
|
||||||
|
'Warning: Youtube closed the connection before byte',
|
||||||
|
str(fail_byte) + '.', 'Expected', start+content_length,
|
||||||
|
'bytes.'
|
||||||
|
)
|
||||||
|
|
||||||
|
retry = True
|
||||||
|
first_attempt = False
|
||||||
|
if fail_byte == current_attempt_position:
|
||||||
|
try_num += 1
|
||||||
|
else:
|
||||||
|
try_num = 1
|
||||||
|
current_attempt_position = fail_byte
|
||||||
|
break
|
||||||
|
yield content_part
|
||||||
|
cleanup_func(response)
|
||||||
|
if retry:
|
||||||
|
# Youtube will return 503 Service Unavailable if you do a bunch
|
||||||
|
# of range requests too quickly.
|
||||||
|
time.sleep(1)
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
else: # no break
|
||||||
|
print('Error: Youtube closed the connection before',
|
||||||
|
'providing all content. Retried three times:', url.split('?')[0])
|
||||||
|
|
||||||
|
def proxy_video(env, start_response):
|
||||||
|
yield from proxy_site(env, start_response, video=True)
|
||||||
|
|
||||||
|
site_handlers = {
|
||||||
|
'youtube.com':yt_app,
|
||||||
|
'youtube-nocookie.com':yt_app,
|
||||||
|
'youtu.be':youtu_be,
|
||||||
|
'ytimg.com': proxy_site,
|
||||||
|
'ggpht.com': proxy_site,
|
||||||
|
'googleusercontent.com': proxy_site,
|
||||||
|
'sponsor.ajay.app': proxy_site,
|
||||||
|
'googlevideo.com': proxy_video,
|
||||||
|
}
|
||||||
|
|
||||||
|
def split_url(url):
|
||||||
|
''' Split https://sub.example.com/foo/bar.html into ('sub.example.com', '/foo/bar.html')'''
|
||||||
|
# XXX: Is this regex safe from REDOS?
|
||||||
|
# python STILL doesn't have a proper regular expression engine like grep uses built in...
|
||||||
|
match = re.match(r'(?:https?://)?([\w-]+(?:\.[\w-]+)+?)(/.*|$)', url)
|
||||||
|
if match is None:
|
||||||
|
raise ValueError('Invalid or unsupported url: ' + url)
|
||||||
|
|
||||||
|
return match.group(1), match.group(2)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def error_code(code, start_response):
|
||||||
|
start_response(code, ())
|
||||||
|
return code.encode()
|
||||||
|
|
||||||
|
def site_dispatch(env, start_response):
|
||||||
|
client_address = env['REMOTE_ADDR']
|
||||||
|
try:
|
||||||
|
# correct malformed query string with ? separators instead of &
|
||||||
|
env['QUERY_STRING'] = env['QUERY_STRING'].replace('?', '&')
|
||||||
|
|
||||||
|
# Some servers such as uWSGI rewrite double slashes // to / by default,
|
||||||
|
# breaking the https:// schema. Some servers provide
|
||||||
|
# REQUEST_URI (nonstandard), which contains the full, original URL.
|
||||||
|
# See https://github.com/user234683/youtube-local/issues/43
|
||||||
|
if 'REQUEST_URI' in env:
|
||||||
|
# Since it's the original url, the server won't handle percent
|
||||||
|
# decoding for us
|
||||||
|
env['PATH_INFO'] = urllib.parse.unquote(
|
||||||
|
env['REQUEST_URI'].split('?')[0]
|
||||||
|
)
|
||||||
|
|
||||||
|
method = env['REQUEST_METHOD']
|
||||||
|
path = env['PATH_INFO']
|
||||||
|
|
||||||
|
if (method=="POST"
|
||||||
|
and client_address not in ('127.0.0.1', '::1')
|
||||||
|
and not settings.allow_foreign_post_requests):
|
||||||
|
yield error_code('403 Forbidden', start_response)
|
||||||
|
return
|
||||||
|
|
||||||
|
# redirect localhost:8080 to localhost:8080/https://youtube.com
|
||||||
|
if path == '' or path == '/':
|
||||||
|
start_response('302 Found', [('Location', '/https://youtube.com')])
|
||||||
|
return
|
||||||
|
|
||||||
|
try:
|
||||||
|
env['SERVER_NAME'], env['PATH_INFO'] = split_url(path[1:])
|
||||||
|
except ValueError:
|
||||||
|
yield error_code('404 Not Found', start_response)
|
||||||
|
return
|
||||||
|
|
||||||
|
base_name = ''
|
||||||
|
for domain in reversed(env['SERVER_NAME'].split('.')):
|
||||||
|
if base_name == '':
|
||||||
|
base_name = domain
|
||||||
|
else:
|
||||||
|
base_name = domain + '.' + base_name
|
||||||
|
|
||||||
|
try:
|
||||||
|
handler = site_handlers[base_name]
|
||||||
|
except KeyError:
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
yield from handler(env, start_response)
|
||||||
|
break
|
||||||
|
else: # did not break
|
||||||
|
yield error_code('404 Not Found', start_response)
|
||||||
|
return
|
||||||
|
except Exception:
|
||||||
|
start_response('500 Internal Server Error', ())
|
||||||
|
yield b'500 Internal Server Error'
|
||||||
|
raise
|
||||||
|
return
|
||||||
|
|
||||||
|
|
||||||
|
class FilteredRequestLog:
|
||||||
|
'''Don't log noisy thumbnail and avatar requests'''
|
||||||
|
filter_re = re.compile(r'''(?x)
|
||||||
|
"GET\ /https://(
|
||||||
|
i[.]ytimg[.]com/|
|
||||||
|
www[.]youtube[.]com/data/subscription_thumbnails/|
|
||||||
|
yt3[.]ggpht[.]com/|
|
||||||
|
www[.]youtube[.]com/api/timedtext|
|
||||||
|
[-\w]+[.]googlevideo[.]com/).*"\ (200|206)
|
||||||
|
''')
|
||||||
|
def __init__(self):
|
||||||
|
pass
|
||||||
|
def write(self, s):
|
||||||
|
if not self.filter_re.search(s):
|
||||||
|
sys.stderr.write(s)
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
if settings.allow_foreign_addresses:
|
||||||
|
server = WSGIServer(('0.0.0.0', settings.port_number), site_dispatch,
|
||||||
|
log=FilteredRequestLog())
|
||||||
|
else:
|
||||||
|
server = WSGIServer(('127.0.0.1', settings.port_number), site_dispatch,
|
||||||
|
log=FilteredRequestLog())
|
||||||
|
print('Started httpserver on port' , settings.port_number)
|
||||||
|
server.serve_forever()
|
||||||
|
|
||||||
|
# for uwsgi, gunicorn, etc.
|
||||||
|
application = site_dispatch
|
||||||
585
settings.py
Normal file
585
settings.py
Normal file
@@ -0,0 +1,585 @@
|
|||||||
|
from youtube import util
|
||||||
|
import ast
|
||||||
|
import re
|
||||||
|
import os
|
||||||
|
import collections
|
||||||
|
|
||||||
|
import flask
|
||||||
|
from flask import request
|
||||||
|
|
||||||
|
SETTINGS_INFO = collections.OrderedDict([
|
||||||
|
('route_tor', {
|
||||||
|
'type': int,
|
||||||
|
'default': 0,
|
||||||
|
'label': 'Route Tor',
|
||||||
|
'comment': '''0 - Off
|
||||||
|
1 - On, except video
|
||||||
|
2 - On, including video (see warnings)''',
|
||||||
|
'options': [
|
||||||
|
(0, 'Off'),
|
||||||
|
(1, 'On, except video'),
|
||||||
|
(2, 'On, including video (see warnings)'),
|
||||||
|
],
|
||||||
|
'category': 'network',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('tor_port', {
|
||||||
|
'type': int,
|
||||||
|
'default': 9150,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'network',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('tor_control_port', {
|
||||||
|
'type': int,
|
||||||
|
'default': 9151,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'network',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('port_number', {
|
||||||
|
'type': int,
|
||||||
|
'default': 8080,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'network',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('allow_foreign_addresses', {
|
||||||
|
'type': bool,
|
||||||
|
'default': False,
|
||||||
|
'comment': '''This will allow others to connect to your Youtube Local instance as a website.
|
||||||
|
For security reasons, enabling this is not recommended.''',
|
||||||
|
'hidden': True,
|
||||||
|
'category': 'network',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('allow_foreign_post_requests', {
|
||||||
|
'type': bool,
|
||||||
|
'default': False,
|
||||||
|
'comment': '''Enables requests from foreign addresses to make post requests.
|
||||||
|
For security reasons, enabling this is not recommended.''',
|
||||||
|
'hidden': True,
|
||||||
|
'category': 'network',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('subtitles_mode', {
|
||||||
|
'type': int,
|
||||||
|
'default': 0,
|
||||||
|
'comment': '''0 - off by default
|
||||||
|
1 - only manually created subtitles on by default
|
||||||
|
2 - enable even if automatically generated is all that's available''',
|
||||||
|
'label': 'Default subtitles mode',
|
||||||
|
'options': [
|
||||||
|
(0, 'Off'),
|
||||||
|
(1, 'Manually created only'),
|
||||||
|
(2, 'Automatic if manual unavailable'),
|
||||||
|
],
|
||||||
|
'category': 'playback',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('subtitles_language', {
|
||||||
|
'type': str,
|
||||||
|
'default': 'en',
|
||||||
|
'comment': '''ISO 639 language code: https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes''',
|
||||||
|
'category': 'playback',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('default_volume', {
|
||||||
|
'type': int,
|
||||||
|
'default': -1,
|
||||||
|
'max': 100,
|
||||||
|
'min': -1,
|
||||||
|
'comment': '''Sets a default volume.
|
||||||
|
Defaults to -1, which means no default value is forced and the browser will set the volume.''',
|
||||||
|
'category': 'playback',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('related_videos_mode', {
|
||||||
|
'type': int,
|
||||||
|
'default': 1,
|
||||||
|
'comment': '''0 - Related videos disabled
|
||||||
|
1 - Related videos always shown
|
||||||
|
2 - Related videos hidden; shown by clicking a button''',
|
||||||
|
'options': [
|
||||||
|
(0, 'Disabled'),
|
||||||
|
(1, 'Always shown'),
|
||||||
|
(2, 'Shown by clicking button'),
|
||||||
|
],
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('comments_mode', {
|
||||||
|
'type': int,
|
||||||
|
'default': 1,
|
||||||
|
'comment': '''0 - Video comments disabled
|
||||||
|
1 - Video comments always shown
|
||||||
|
2 - Video comments hidden; shown by clicking a button''',
|
||||||
|
'options': [
|
||||||
|
(0, 'Disabled'),
|
||||||
|
(1, 'Always shown'),
|
||||||
|
(2, 'Shown by clicking button'),
|
||||||
|
],
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('enable_comment_avatars', {
|
||||||
|
'type': bool,
|
||||||
|
'default': True,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('default_comment_sorting', {
|
||||||
|
'type': int,
|
||||||
|
'default': 0,
|
||||||
|
'comment': '''0 to sort by top
|
||||||
|
1 to sort by newest''',
|
||||||
|
'options': [
|
||||||
|
(0, 'Top'),
|
||||||
|
(1, 'Newest'),
|
||||||
|
],
|
||||||
|
}),
|
||||||
|
|
||||||
|
('theater_mode', {
|
||||||
|
'type': bool,
|
||||||
|
'default': True,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('default_resolution', {
|
||||||
|
'type': int,
|
||||||
|
'default': 720,
|
||||||
|
'comment': '',
|
||||||
|
'options': [
|
||||||
|
(144, '144p'),
|
||||||
|
(240, '240p'),
|
||||||
|
(360, '360p'),
|
||||||
|
(480, '480p'),
|
||||||
|
(720, '720p'),
|
||||||
|
(1080, '1080p'),
|
||||||
|
(1440, '1440p'),
|
||||||
|
(2160, '2160p'),
|
||||||
|
],
|
||||||
|
'category': 'playback',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('autoplay_videos', {
|
||||||
|
'type': bool,
|
||||||
|
'default': False,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'playback',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('codec_rank_h264', {
|
||||||
|
'type': int,
|
||||||
|
'default': 1,
|
||||||
|
'label': 'H.264 Codec Ranking',
|
||||||
|
'comment': '',
|
||||||
|
'options': [(1, '#1'), (2, '#2'), (3, '#3')],
|
||||||
|
'category': 'playback',
|
||||||
|
'description': (
|
||||||
|
'Which video codecs to prefer. Codecs given the same '
|
||||||
|
'ranking will use smaller file size as a tiebreaker.'
|
||||||
|
)
|
||||||
|
}),
|
||||||
|
|
||||||
|
('codec_rank_vp', {
|
||||||
|
'type': int,
|
||||||
|
'default': 2,
|
||||||
|
'label': 'VP8/VP9 Codec Ranking',
|
||||||
|
'comment': '',
|
||||||
|
'options': [(1, '#1'), (2, '#2'), (3, '#3')],
|
||||||
|
'category': 'playback',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('codec_rank_av1', {
|
||||||
|
'type': int,
|
||||||
|
'default': 3,
|
||||||
|
'label': 'AV1 Codec Ranking',
|
||||||
|
'comment': '',
|
||||||
|
'options': [(1, '#1'), (2, '#2'), (3, '#3')],
|
||||||
|
'category': 'playback',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('prefer_uni_sources', {
|
||||||
|
'label': 'Use integrated sources',
|
||||||
|
'type': int,
|
||||||
|
'default': 1,
|
||||||
|
'comment': '',
|
||||||
|
'options': [
|
||||||
|
(0, 'Prefer not'),
|
||||||
|
(1, 'Prefer'),
|
||||||
|
(2, 'Always'),
|
||||||
|
],
|
||||||
|
'category': 'playback',
|
||||||
|
'description': 'If set to Prefer or Always and the default resolution is set to 360p or 720p, uses the unified (integrated) video files which contain audio and video, with buffering managed by the browser. If set to prefer not, uses the separate audio and video files through custom buffer management in av-merge via MediaSource unless they are unavailable.',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('use_video_hotkeys', {
|
||||||
|
'label': 'Enable video hotkeys',
|
||||||
|
'type': bool,
|
||||||
|
'default': True,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('video_player', {
|
||||||
|
'type': int,
|
||||||
|
'default': 1,
|
||||||
|
'comment': '',
|
||||||
|
'options': [
|
||||||
|
(0, 'Browser Default'),
|
||||||
|
(1, 'Plyr'),
|
||||||
|
],
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('proxy_images', {
|
||||||
|
'label': 'Route images',
|
||||||
|
'type': bool,
|
||||||
|
'default': True,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'network',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('use_comments_js', {
|
||||||
|
'label': 'Enable comments.js',
|
||||||
|
'type': bool,
|
||||||
|
'default': True,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('use_sponsorblock_js', {
|
||||||
|
'label': 'Enable SponsorBlock',
|
||||||
|
'type': bool,
|
||||||
|
'default': False,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'playback',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('theme', {
|
||||||
|
'type': int,
|
||||||
|
'default': 0,
|
||||||
|
'comment': '',
|
||||||
|
'options': [
|
||||||
|
(0, 'Light'),
|
||||||
|
(1, 'Gray'),
|
||||||
|
(2, 'Dark'),
|
||||||
|
],
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('font', {
|
||||||
|
'type': int,
|
||||||
|
'default': 1,
|
||||||
|
'comment': '',
|
||||||
|
'options': [
|
||||||
|
(0, 'Browser default'),
|
||||||
|
(1, 'Arial'),
|
||||||
|
(2, 'Liberation Serif'),
|
||||||
|
(3, 'Verdana'),
|
||||||
|
(4, 'Tahoma'),
|
||||||
|
],
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('embed_page_mode', {
|
||||||
|
'type': bool,
|
||||||
|
'label': 'Enable embed page',
|
||||||
|
'default': True,
|
||||||
|
'comment': '',
|
||||||
|
'category': 'interface',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('autocheck_subscriptions', {
|
||||||
|
'type': bool,
|
||||||
|
'default': 0,
|
||||||
|
'comment': '',
|
||||||
|
}),
|
||||||
|
('include_shorts_in_subscriptions', {
|
||||||
|
'type': bool,
|
||||||
|
'default': 0,
|
||||||
|
'comment': '',
|
||||||
|
}),
|
||||||
|
('include_shorts_in_channel', {
|
||||||
|
'type': bool,
|
||||||
|
'default': 1,
|
||||||
|
'comment': '',
|
||||||
|
}),
|
||||||
|
|
||||||
|
('debugging_save_responses', {
|
||||||
|
'type': bool,
|
||||||
|
'default': False,
|
||||||
|
'comment': '''Save all responses from youtube for debugging''',
|
||||||
|
'hidden': True,
|
||||||
|
}),
|
||||||
|
|
||||||
|
('settings_version', {
|
||||||
|
'type': int,
|
||||||
|
'default': 6,
|
||||||
|
'comment': '''Do not change, remove, or comment out this value, or else your settings may be lost or corrupted''',
|
||||||
|
'hidden': True,
|
||||||
|
}),
|
||||||
|
])
|
||||||
|
|
||||||
|
program_directory = os.path.dirname(os.path.realpath(__file__))
|
||||||
|
acceptable_targets = SETTINGS_INFO.keys() | {
|
||||||
|
'enable_comments', 'enable_related_videos', 'preferred_video_codec'
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def comment_string(comment):
|
||||||
|
result = ''
|
||||||
|
for line in comment.splitlines():
|
||||||
|
result += '# ' + line + '\n'
|
||||||
|
return result
|
||||||
|
|
||||||
|
def save_settings(settings_dict):
|
||||||
|
with open(settings_file_path, 'w', encoding='utf-8') as file:
|
||||||
|
for setting_name, setting_info in SETTINGS_INFO.items():
|
||||||
|
file.write(comment_string(setting_info['comment']) + setting_name + ' = ' + repr(settings_dict[setting_name]) + '\n\n')
|
||||||
|
|
||||||
|
def add_missing_settings(settings_dict):
|
||||||
|
result = default_settings()
|
||||||
|
result.update(settings_dict)
|
||||||
|
return result
|
||||||
|
|
||||||
|
def default_settings():
|
||||||
|
return {key: setting_info['default'] for key, setting_info in SETTINGS_INFO.items()}
|
||||||
|
|
||||||
|
def upgrade_to_2(settings_dict):
|
||||||
|
'''Upgrade to settings version 2'''
|
||||||
|
new_settings = settings_dict.copy()
|
||||||
|
if 'enable_comments' in settings_dict:
|
||||||
|
new_settings['comments_mode'] = int(settings_dict['enable_comments'])
|
||||||
|
del new_settings['enable_comments']
|
||||||
|
if 'enable_related_videos' in settings_dict:
|
||||||
|
new_settings['related_videos_mode'] = int(settings_dict['enable_related_videos'])
|
||||||
|
del new_settings['enable_related_videos']
|
||||||
|
new_settings['settings_version'] = 2
|
||||||
|
return new_settings
|
||||||
|
|
||||||
|
def upgrade_to_3(settings_dict):
|
||||||
|
new_settings = settings_dict.copy()
|
||||||
|
if 'route_tor' in settings_dict:
|
||||||
|
new_settings['route_tor'] = int(settings_dict['route_tor'])
|
||||||
|
new_settings['settings_version'] = 3
|
||||||
|
return new_settings
|
||||||
|
def upgrade_to_4(settings_dict):
|
||||||
|
new_settings = settings_dict.copy()
|
||||||
|
if 'preferred_video_codec' in settings_dict:
|
||||||
|
pref = settings_dict['preferred_video_codec']
|
||||||
|
if pref == 0:
|
||||||
|
new_settings['codec_rank_h264'] = 1
|
||||||
|
new_settings['codec_rank_vp'] = 2
|
||||||
|
new_settings['codec_rank_av1'] = 3
|
||||||
|
else:
|
||||||
|
new_settings['codec_rank_h264'] = 3
|
||||||
|
new_settings['codec_rank_vp'] = 2
|
||||||
|
new_settings['codec_rank_av1'] = 1
|
||||||
|
del new_settings['preferred_video_codec']
|
||||||
|
new_settings['settings_version'] = 4
|
||||||
|
return new_settings
|
||||||
|
|
||||||
|
def upgrade_to_5(settings_dict):
|
||||||
|
new_settings = settings_dict.copy()
|
||||||
|
if 'prefer_uni_sources' in settings_dict:
|
||||||
|
new_settings['prefer_uni_sources'] = int(settings_dict['prefer_uni_sources'])
|
||||||
|
new_settings['settings_version'] = 5
|
||||||
|
return new_settings
|
||||||
|
|
||||||
|
def upgrade_to_6(settings_dict):
|
||||||
|
new_settings = settings_dict.copy()
|
||||||
|
if 'gather_googlevideo_domains' in new_settings:
|
||||||
|
del new_settings['gather_googlevideo_domains']
|
||||||
|
new_settings['settings_version'] = 6
|
||||||
|
return new_settings
|
||||||
|
|
||||||
|
upgrade_functions = {
|
||||||
|
1: upgrade_to_2,
|
||||||
|
2: upgrade_to_3,
|
||||||
|
3: upgrade_to_4,
|
||||||
|
4: upgrade_to_5,
|
||||||
|
5: upgrade_to_6,
|
||||||
|
}
|
||||||
|
|
||||||
|
def log_ignored_line(line_number, message):
|
||||||
|
print("WARNING: Ignoring settings.txt line " + str(node.lineno) + " (" + message + ")")
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
if os.path.isfile("settings.txt"):
|
||||||
|
print("Running in portable mode")
|
||||||
|
settings_dir = os.path.normpath('./')
|
||||||
|
data_dir = os.path.normpath('./data')
|
||||||
|
else:
|
||||||
|
print("Running in non-portable mode")
|
||||||
|
settings_dir = os.path.expanduser(os.path.normpath("~/.youtube-local"))
|
||||||
|
data_dir = os.path.expanduser(os.path.normpath("~/.youtube-local/data"))
|
||||||
|
if not os.path.exists(settings_dir):
|
||||||
|
os.makedirs(settings_dir)
|
||||||
|
|
||||||
|
settings_file_path = os.path.join(settings_dir, 'settings.txt')
|
||||||
|
|
||||||
|
try:
|
||||||
|
with open(settings_file_path, 'r', encoding='utf-8') as file:
|
||||||
|
settings_text = file.read()
|
||||||
|
except FileNotFoundError:
|
||||||
|
current_settings_dict = default_settings()
|
||||||
|
save_settings(current_settings_dict)
|
||||||
|
else:
|
||||||
|
if re.fullmatch(r'\s*', settings_text): # blank file
|
||||||
|
current_settings_dict = default_settings()
|
||||||
|
save_settings(current_settings_dict)
|
||||||
|
else:
|
||||||
|
# parse settings in a safe way, without exec
|
||||||
|
current_settings_dict = {}
|
||||||
|
attributes = {
|
||||||
|
ast.Constant: 'value',
|
||||||
|
ast.NameConstant: 'value',
|
||||||
|
ast.Num: 'n',
|
||||||
|
ast.Str: 's',
|
||||||
|
}
|
||||||
|
module_node = ast.parse(settings_text)
|
||||||
|
for node in module_node.body:
|
||||||
|
if type(node) != ast.Assign:
|
||||||
|
log_ignored_line(node.lineno, "only assignments are allowed")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if len(node.targets) > 1:
|
||||||
|
log_ignored_line(node.lineno, "only simple single-variable assignments allowed")
|
||||||
|
continue
|
||||||
|
|
||||||
|
target = node.targets[0]
|
||||||
|
if type(target) != ast.Name:
|
||||||
|
log_ignored_line(node.lineno, "only simple single-variable assignments allowed")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if target.id not in acceptable_targets:
|
||||||
|
log_ignored_line(node.lineno, target.id + " is not a valid setting")
|
||||||
|
continue
|
||||||
|
|
||||||
|
value = None
|
||||||
|
# Negative values
|
||||||
|
if (
|
||||||
|
type(node.value) is ast.UnaryOp
|
||||||
|
and type(node.value.op) is ast.USub
|
||||||
|
and type(node.value.operand) in attributes
|
||||||
|
):
|
||||||
|
value = -node.value.operand.__getattribute__(
|
||||||
|
attributes[type(node.value.operand)]
|
||||||
|
)
|
||||||
|
elif type(node.value) not in attributes:
|
||||||
|
print(type(node.value))
|
||||||
|
log_ignored_line(node.lineno, "only literals allowed for values")
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Regular values
|
||||||
|
if not value:
|
||||||
|
value = node.value.__getattribute__(
|
||||||
|
attributes[type(node.value)]
|
||||||
|
)
|
||||||
|
current_settings_dict[target.id] = value
|
||||||
|
|
||||||
|
# upgrades
|
||||||
|
latest_version = SETTINGS_INFO['settings_version']['default']
|
||||||
|
while current_settings_dict.get('settings_version',1) < latest_version:
|
||||||
|
current_version = current_settings_dict.get('settings_version', 1)
|
||||||
|
print('Upgrading settings.txt to version', current_version+1)
|
||||||
|
upgrade_func = upgrade_functions[current_version]
|
||||||
|
# Must add missing settings here rather than below because
|
||||||
|
# save_settings needs all settings to be present
|
||||||
|
current_settings_dict = add_missing_settings(
|
||||||
|
upgrade_func(current_settings_dict))
|
||||||
|
save_settings(current_settings_dict)
|
||||||
|
|
||||||
|
# some settings not in the file, add those missing settings to the file
|
||||||
|
if not current_settings_dict.keys() >= SETTINGS_INFO.keys():
|
||||||
|
print('Adding missing settings to settings.txt')
|
||||||
|
current_settings_dict = add_missing_settings(current_settings_dict)
|
||||||
|
save_settings(current_settings_dict)
|
||||||
|
|
||||||
|
globals().update(current_settings_dict)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
if route_tor:
|
||||||
|
print("Tor routing is ON")
|
||||||
|
else:
|
||||||
|
print("Tor routing is OFF - your Youtube activity is NOT anonymous")
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
hooks = {}
|
||||||
|
def add_setting_changed_hook(setting, func):
|
||||||
|
'''Called right after new settings take effect'''
|
||||||
|
if setting in hooks:
|
||||||
|
hooks[setting].append(func)
|
||||||
|
else:
|
||||||
|
hooks[setting] = [func]
|
||||||
|
|
||||||
|
|
||||||
|
def set_img_prefix(old_value=None, value=None):
|
||||||
|
global img_prefix
|
||||||
|
if value is None:
|
||||||
|
value = proxy_images
|
||||||
|
if value:
|
||||||
|
img_prefix = '/'
|
||||||
|
else:
|
||||||
|
img_prefix = ''
|
||||||
|
set_img_prefix()
|
||||||
|
add_setting_changed_hook('proxy_images', set_img_prefix)
|
||||||
|
|
||||||
|
|
||||||
|
categories = ['network', 'interface', 'playback', 'other']
|
||||||
|
def settings_page():
|
||||||
|
if request.method == 'GET':
|
||||||
|
settings_by_category = {categ: [] for categ in categories}
|
||||||
|
for setting_name, setting_info in SETTINGS_INFO.items():
|
||||||
|
categ = setting_info.get('category', 'other')
|
||||||
|
settings_by_category[categ].append(
|
||||||
|
(setting_name, setting_info, current_settings_dict[setting_name])
|
||||||
|
)
|
||||||
|
return flask.render_template('settings.html',
|
||||||
|
categories = categories,
|
||||||
|
settings_by_category = settings_by_category,
|
||||||
|
)
|
||||||
|
elif request.method == 'POST':
|
||||||
|
for key, value in request.values.items():
|
||||||
|
if key in SETTINGS_INFO:
|
||||||
|
if SETTINGS_INFO[key]['type'] is bool and value == 'on':
|
||||||
|
current_settings_dict[key] = True
|
||||||
|
else:
|
||||||
|
current_settings_dict[key] = SETTINGS_INFO[key]['type'](value)
|
||||||
|
else:
|
||||||
|
flask.abort(400)
|
||||||
|
|
||||||
|
# need this bullshit because browsers don't send anything when an input is unchecked
|
||||||
|
expected_inputs = {setting_name for setting_name, setting_info in SETTINGS_INFO.items() if not SETTINGS_INFO[setting_name].get('hidden', False)}
|
||||||
|
missing_inputs = expected_inputs - set(request.values.keys())
|
||||||
|
for setting_name in missing_inputs:
|
||||||
|
assert SETTINGS_INFO[setting_name]['type'] is bool, missing_inputs
|
||||||
|
current_settings_dict[setting_name] = False
|
||||||
|
|
||||||
|
# find settings that have changed to prepare setting hook calls
|
||||||
|
to_call = []
|
||||||
|
for setting_name, value in current_settings_dict.items():
|
||||||
|
old_value = globals()[setting_name]
|
||||||
|
if value != old_value and setting_name in hooks:
|
||||||
|
for func in hooks[setting_name]:
|
||||||
|
to_call.append((func, old_value, value))
|
||||||
|
|
||||||
|
globals().update(current_settings_dict)
|
||||||
|
save_settings(current_settings_dict)
|
||||||
|
|
||||||
|
# call setting hooks
|
||||||
|
for func, old_value, value in to_call:
|
||||||
|
func(old_value, value)
|
||||||
|
|
||||||
|
return flask.redirect(util.URL_ORIGIN + '/settings', 303)
|
||||||
|
else:
|
||||||
|
flask.abort(400)
|
||||||
14
tests/conftest.py
Normal file
14
tests/conftest.py
Normal file
@@ -0,0 +1,14 @@
|
|||||||
|
import pytest
|
||||||
|
import urllib3
|
||||||
|
import urllib
|
||||||
|
import urllib.request
|
||||||
|
import socket
|
||||||
|
|
||||||
|
# https://realpython.com/pytest-python-testing/
|
||||||
|
@pytest.fixture(autouse=True)
|
||||||
|
def disable_network_calls(monkeypatch):
|
||||||
|
def stunted_get(*args, **kwargs):
|
||||||
|
raise RuntimeError('Network access not allowed during testing!')
|
||||||
|
monkeypatch.setattr(urllib.request, 'Request', stunted_get)
|
||||||
|
monkeypatch.setattr(urllib3.PoolManager, 'request', stunted_get)
|
||||||
|
monkeypatch.setattr(socket, 'socket', stunted_get)
|
||||||
28
tests/test_responses/429.html
Normal file
28
tests/test_responses/429.html
Normal file
@@ -0,0 +1,28 @@
|
|||||||
|
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
|
||||||
|
<html>
|
||||||
|
<head><meta http-equiv="content-type" content="text/html; charset=utf-8"><meta name="viewport" content="initial-scale=1"><title>https://m.youtube.com/watch?v=aaaaaaaaaaa&pbj=1&bpctr=9999999999</title></head>
|
||||||
|
<body style="font-family: arial, sans-serif; background-color: #fff; color: #000; padding:20px; font-size:18px;" onload="e=document.getElementById('captcha');if(e){e.focus();}">
|
||||||
|
<div style="max-width:400px;">
|
||||||
|
<hr noshade size="1" style="color:#ccc; background-color:#ccc;"><br>
|
||||||
|
<form id="captcha-form" action="index" method="post">
|
||||||
|
<script src="https://www.google.com/recaptcha/api.js" async defer></script>
|
||||||
|
<script>var submitCallback = function(response) {document.getElementById('captcha-form').submit();};</script>
|
||||||
|
<div id="recaptcha" class="g-recaptcha" data-sitekey="6LfwuyUTAAAAAOAmoS0fdqijC2PbbdH4kjq62Y1b" data-callback="submitCallback" data-s="vJ20x5QPFGCo8r3XkMznOwMTCK8wPW_bLLhPDgo_I1cwF6xLuYZlq2G2wZPaSJiE8zx5YnaxJzFQGsyhY6NHQKMAaUTtSP6GAbPtueM35Jq3Hmk-gEAozXvvF0HIjK5oONT7F-06MwXDxA4HOqZyOEbsUG_8JjFcCklQjUNUVVItgyLpIbZ1dQ-IEtCXY5E3KDcgHGznfAyMGk_bby9uCpfxNTQwljGippKv1PIU7dI4d5LLpgBPWF0"></div>
|
||||||
|
<input type='hidden' name='q' value='EhAgAUug_-oCrgAAAAAAAAoQGPe-9u8FIhkA8aeDS_-EXvhS86PaeaDvps8cqCssFqOzMgFy'><input type="hidden" name="continue" value="https://m.youtube.com/watch?v=aaaaaaaaaaa&pbj=1&bpctr=9999999999">
|
||||||
|
</form>
|
||||||
|
<hr noshade size="1" style="color:#ccc; background-color:#ccc;">
|
||||||
|
|
||||||
|
<div style="font-size:13px;">
|
||||||
|
<b>About this page</b><br><br>
|
||||||
|
|
||||||
|
Our systems have detected unusual traffic from your computer network. This page checks to see if it's really you sending the requests, and not a robot. <a href="#" onclick="document.getElementById('infoDiv').style.display='block';">Why did this happen?</a><br><br>
|
||||||
|
|
||||||
|
<div id="infoDiv" style="display:none; background-color:#eee; padding:10px; margin:0 0 15px 0; line-height:1.4em;">
|
||||||
|
This page appears when Google automatically detects requests coming from your computer network which appear to be in violation of the <a href="//www.google.com/policies/terms/">Terms of Service</a>. The block will expire shortly after those requests stop. In the meantime, solving the above CAPTCHA will let you continue to use our services.<br><br>This traffic may have been sent by malicious software, a browser plug-in, or a script that sends automated requests. If you share your network connection, ask your administrator for help — a different computer using the same IP address may be responsible. <a href="//support.google.com/websearch/answer/86640">Learn more</a><br><br>Sometimes you may be asked to solve the CAPTCHA if you are using advanced terms that robots are known to use, or sending requests very quickly.
|
||||||
|
</div>
|
||||||
|
|
||||||
|
IP address: 2001:4ba0:ffea:2ae::a10<br>Time: 2019-12-21T04:28:41Z<br>URL: https://m.youtube.com/watch?v=aaaaaaaaaaa&pbj=1&bpctr=9999999999<br>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
76
tests/test_util.py
Normal file
76
tests/test_util.py
Normal file
@@ -0,0 +1,76 @@
|
|||||||
|
from youtube import util
|
||||||
|
import settings
|
||||||
|
import pytest # overview: https://realpython.com/pytest-python-testing/
|
||||||
|
import urllib3
|
||||||
|
import io
|
||||||
|
import os
|
||||||
|
import stem
|
||||||
|
|
||||||
|
|
||||||
|
def load_test_page(name):
|
||||||
|
with open(os.path.join('./tests/test_responses', name), 'rb') as f:
|
||||||
|
return f.read()
|
||||||
|
|
||||||
|
|
||||||
|
html429 = load_test_page('429.html')
|
||||||
|
|
||||||
|
|
||||||
|
class MockResponse(urllib3.response.HTTPResponse):
|
||||||
|
def __init__(self, body='success', headers=None, status=200, reason=''):
|
||||||
|
print(body[0:10])
|
||||||
|
headers = headers or {}
|
||||||
|
if isinstance(body, str):
|
||||||
|
body = body.encode('utf-8')
|
||||||
|
self.body_io = io.BytesIO(body)
|
||||||
|
self.read = self.body_io.read
|
||||||
|
urllib3.response.HTTPResponse.__init__(
|
||||||
|
self, body=body, headers=headers, status=status,
|
||||||
|
preload_content=False, decode_content=False, reason=reason
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class NewIdentityState():
|
||||||
|
MAX_TRIES = util.TorManager.MAX_TRIES
|
||||||
|
def __init__(self, new_identities_till_success):
|
||||||
|
self.new_identities_till_success = new_identities_till_success
|
||||||
|
|
||||||
|
def new_identity(self, *args, **kwargs):
|
||||||
|
print('newidentity')
|
||||||
|
self.new_identities_till_success -= 1
|
||||||
|
|
||||||
|
def fetch_url_response(self, *args, **kwargs):
|
||||||
|
cleanup_func = (lambda r: None)
|
||||||
|
if self.new_identities_till_success == 0:
|
||||||
|
return MockResponse(), cleanup_func
|
||||||
|
return MockResponse(body=html429, status=429), cleanup_func
|
||||||
|
|
||||||
|
|
||||||
|
class MockController():
|
||||||
|
def authenticate(self, *args, **kwargs):
|
||||||
|
pass
|
||||||
|
@classmethod
|
||||||
|
def from_port(cls, *args, **kwargs):
|
||||||
|
return cls()
|
||||||
|
def __enter__(self, *args, **kwargs):
|
||||||
|
return self
|
||||||
|
def __exit__(self, *args, **kwargs):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
@pytest.mark.parametrize('new_identities_till_success',
|
||||||
|
[i for i in range(0, NewIdentityState.MAX_TRIES+2)])
|
||||||
|
def test_exit_node_retry(monkeypatch, new_identities_till_success):
|
||||||
|
new_identity_state = NewIdentityState(new_identities_till_success)
|
||||||
|
# https://docs.pytest.org/en/stable/monkeypatch.html
|
||||||
|
monkeypatch.setattr(settings, 'route_tor', 1)
|
||||||
|
monkeypatch.setattr(util, 'tor_manager', util.TorManager()) # fresh one
|
||||||
|
MockController.signal = new_identity_state.new_identity
|
||||||
|
monkeypatch.setattr(stem.control, 'Controller', MockController)
|
||||||
|
monkeypatch.setattr(util, 'fetch_url_response',
|
||||||
|
new_identity_state.fetch_url_response)
|
||||||
|
if new_identities_till_success <= NewIdentityState.MAX_TRIES:
|
||||||
|
assert util.fetch_url('url') == b'success'
|
||||||
|
else:
|
||||||
|
with pytest.raises(util.FetchError) as excinfo:
|
||||||
|
util.fetch_url('url')
|
||||||
|
assert int(excinfo.value.code) == 429
|
||||||
116
youtube/__init__.py
Normal file
116
youtube/__init__.py
Normal file
@@ -0,0 +1,116 @@
|
|||||||
|
from youtube import util
|
||||||
|
import flask
|
||||||
|
from flask import request
|
||||||
|
import jinja2
|
||||||
|
import settings
|
||||||
|
import traceback
|
||||||
|
import re
|
||||||
|
from sys import exc_info
|
||||||
|
from youtube.home import get_recommended_videos
|
||||||
|
|
||||||
|
yt_app = flask.Flask(__name__)
|
||||||
|
yt_app.url_map.strict_slashes = False
|
||||||
|
# yt_app.jinja_env.trim_blocks = True
|
||||||
|
# yt_app.jinja_env.lstrip_blocks = True
|
||||||
|
|
||||||
|
# https://stackoverflow.com/questions/39858191/do-statement-not-working-in-jinja
|
||||||
|
yt_app.jinja_env.add_extension('jinja2.ext.do') # why
|
||||||
|
|
||||||
|
yt_app.add_url_rule('/settings', 'settings_page', settings.settings_page, methods=['POST', 'GET'])
|
||||||
|
|
||||||
|
@yt_app.route('/')
|
||||||
|
def homepage():
|
||||||
|
videos = get_recommended_videos()
|
||||||
|
return flask.render_template('home.html', title="Youtube local", recommended_videos=videos)
|
||||||
|
|
||||||
|
|
||||||
|
theme_names = {
|
||||||
|
0: 'light_theme',
|
||||||
|
1: 'gray_theme',
|
||||||
|
2: 'dark_theme',
|
||||||
|
}
|
||||||
|
|
||||||
|
@yt_app.context_processor
|
||||||
|
def inject_theme_preference():
|
||||||
|
return {
|
||||||
|
'theme_path': '/youtube.com/static/' + theme_names[settings.theme] + '.css',
|
||||||
|
'settings': settings,
|
||||||
|
}
|
||||||
|
|
||||||
|
@yt_app.template_filter('commatize')
|
||||||
|
def commatize(num):
|
||||||
|
if num is None:
|
||||||
|
return ''
|
||||||
|
if isinstance(num, str):
|
||||||
|
try:
|
||||||
|
num = int(num)
|
||||||
|
except ValueError:
|
||||||
|
return num
|
||||||
|
return '{:,}'.format(num)
|
||||||
|
|
||||||
|
def timestamp_replacement(match):
|
||||||
|
time_seconds = 0
|
||||||
|
for part in match.group(0).split(':'):
|
||||||
|
time_seconds = 60*time_seconds + int(part)
|
||||||
|
return (
|
||||||
|
'<a href="#" onclick="document.querySelector(\'video\').currentTime='
|
||||||
|
+ str(time_seconds)
|
||||||
|
+ '">' + match.group(0)
|
||||||
|
+ '</a>'
|
||||||
|
)
|
||||||
|
|
||||||
|
TIMESTAMP_RE = re.compile(r'\b(\d?\d:)?\d?\d:\d\d\b')
|
||||||
|
@yt_app.template_filter('timestamps')
|
||||||
|
def timestamps(text):
|
||||||
|
return TIMESTAMP_RE.sub(timestamp_replacement, text)
|
||||||
|
|
||||||
|
@yt_app.errorhandler(500)
|
||||||
|
def error_page(e):
|
||||||
|
slim = request.args.get('slim', False) # whether it was an ajax request
|
||||||
|
if (exc_info()[0] == util.FetchError
|
||||||
|
and exc_info()[1].code == '429'
|
||||||
|
and settings.route_tor
|
||||||
|
):
|
||||||
|
error_message = ('Error: Youtube blocked the request because the Tor'
|
||||||
|
' exit node is overutilized. Try getting a new exit node by'
|
||||||
|
' using the New Identity button in the Tor Browser.')
|
||||||
|
if exc_info()[1].error_message:
|
||||||
|
error_message += '\n\n' + exc_info()[1].error_message
|
||||||
|
if exc_info()[1].ip:
|
||||||
|
error_message += '\n\nExit node IP address: ' + exc_info()[1].ip
|
||||||
|
return flask.render_template('error.html', error_message=error_message, slim=slim), 502
|
||||||
|
elif exc_info()[0] == util.FetchError and exc_info()[1].error_message:
|
||||||
|
return (flask.render_template(
|
||||||
|
'error.html',
|
||||||
|
error_message=exc_info()[1].error_message,
|
||||||
|
slim=slim
|
||||||
|
), 502)
|
||||||
|
return flask.render_template('error.html', traceback=traceback.format_exc(), slim=slim), 500
|
||||||
|
|
||||||
|
font_choices = {
|
||||||
|
0: 'initial',
|
||||||
|
1: 'arial, "liberation sans", sans-serif',
|
||||||
|
2: '"liberation serif", "times new roman", calibri, carlito, serif',
|
||||||
|
3: 'verdana, sans-serif',
|
||||||
|
4: 'tahoma, sans-serif',
|
||||||
|
}
|
||||||
|
|
||||||
|
@yt_app.route('/shared.css')
|
||||||
|
def get_css():
|
||||||
|
return flask.Response(
|
||||||
|
flask.render_template('shared.css',
|
||||||
|
font_family = font_choices[settings.font]
|
||||||
|
),
|
||||||
|
mimetype='text/css',
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
# This is okay because the flask urlize function puts the href as the first
|
||||||
|
# property
|
||||||
|
YOUTUBE_LINK_RE = re.compile(r'<a href="(' + util.YOUTUBE_URL_RE_STR + ')"')
|
||||||
|
old_urlize = jinja2.filters.urlize
|
||||||
|
def prefix_urlize(*args, **kwargs):
|
||||||
|
result = old_urlize(*args, **kwargs)
|
||||||
|
return YOUTUBE_LINK_RE.sub(r'<a href="/\1"', result)
|
||||||
|
jinja2.filters.urlize = prefix_urlize
|
||||||
|
|
||||||
591
youtube/channel.py
Normal file
591
youtube/channel.py
Normal file
@@ -0,0 +1,591 @@
|
|||||||
|
import base64
|
||||||
|
from youtube import (util, yt_data_extract, local_playlist, subscriptions,
|
||||||
|
playlist)
|
||||||
|
from youtube import yt_app
|
||||||
|
import settings
|
||||||
|
|
||||||
|
import urllib
|
||||||
|
import json
|
||||||
|
from string import Template
|
||||||
|
import youtube.proto as proto
|
||||||
|
import html
|
||||||
|
import math
|
||||||
|
import gevent
|
||||||
|
import re
|
||||||
|
import cachetools.func
|
||||||
|
import traceback
|
||||||
|
|
||||||
|
import flask
|
||||||
|
from flask import request
|
||||||
|
|
||||||
|
headers_desktop = (
|
||||||
|
('Accept', '*/*'),
|
||||||
|
('Accept-Language', 'en-US,en;q=0.5'),
|
||||||
|
('X-YouTube-Client-Name', '1'),
|
||||||
|
('X-YouTube-Client-Version', '2.20180830'),
|
||||||
|
) + util.desktop_ua
|
||||||
|
headers_mobile = (
|
||||||
|
('Accept', '*/*'),
|
||||||
|
('Accept-Language', 'en-US,en;q=0.5'),
|
||||||
|
('X-YouTube-Client-Name', '2'),
|
||||||
|
('X-YouTube-Client-Version', '2.20180830'),
|
||||||
|
) + util.mobile_ua
|
||||||
|
real_cookie = (('Cookie', 'VISITOR_INFO1_LIVE=8XihrAcN1l4'),)
|
||||||
|
generic_cookie = (('Cookie', 'VISITOR_INFO1_LIVE=ST1Ti53r4fU'),)
|
||||||
|
|
||||||
|
# added an extra nesting under the 2nd base64 compared to v4
|
||||||
|
# added tab support
|
||||||
|
# changed offset field to uint id 1
|
||||||
|
def channel_ctoken_v5(channel_id, page, sort, tab, view=1):
|
||||||
|
new_sort = (2 if int(sort) == 1 else 1)
|
||||||
|
offset = 30*(int(page) - 1)
|
||||||
|
if tab == 'videos':
|
||||||
|
tab = 15
|
||||||
|
elif tab == 'shorts':
|
||||||
|
tab = 10
|
||||||
|
elif tab == 'streams':
|
||||||
|
tab = 14
|
||||||
|
pointless_nest = proto.string(80226972,
|
||||||
|
proto.string(2, channel_id)
|
||||||
|
+ proto.string(3,
|
||||||
|
proto.percent_b64encode(
|
||||||
|
proto.string(110,
|
||||||
|
proto.string(3,
|
||||||
|
proto.string(tab,
|
||||||
|
proto.string(1,
|
||||||
|
proto.string(1,
|
||||||
|
proto.unpadded_b64encode(
|
||||||
|
proto.string(1,
|
||||||
|
proto.string(1,
|
||||||
|
proto.unpadded_b64encode(
|
||||||
|
proto.string(2,
|
||||||
|
b"ST:"
|
||||||
|
+ proto.unpadded_b64encode(
|
||||||
|
proto.uint(1, offset)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
# targetId, just needs to be present but
|
||||||
|
# doesn't need to be correct
|
||||||
|
+ proto.string(2, "63faaff0-0000-23fe-80f0-582429d11c38")
|
||||||
|
)
|
||||||
|
# 1 - newest, 2 - popular
|
||||||
|
+ proto.uint(3, new_sort)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
return base64.urlsafe_b64encode(pointless_nest).decode('ascii')
|
||||||
|
|
||||||
|
# https://github.com/user234683/youtube-local/issues/151
|
||||||
|
def channel_ctoken_v4(channel_id, page, sort, tab, view=1):
|
||||||
|
new_sort = (2 if int(sort) == 1 else 1)
|
||||||
|
offset = str(30*(int(page) - 1))
|
||||||
|
pointless_nest = proto.string(80226972,
|
||||||
|
proto.string(2, channel_id)
|
||||||
|
+ proto.string(3,
|
||||||
|
proto.percent_b64encode(
|
||||||
|
proto.string(110,
|
||||||
|
proto.string(3,
|
||||||
|
proto.string(15,
|
||||||
|
proto.string(1,
|
||||||
|
proto.string(1,
|
||||||
|
proto.unpadded_b64encode(
|
||||||
|
proto.string(1,
|
||||||
|
proto.unpadded_b64encode(
|
||||||
|
proto.string(2,
|
||||||
|
b"ST:"
|
||||||
|
+ proto.unpadded_b64encode(
|
||||||
|
proto.string(2, offset)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
# targetId, just needs to be present but
|
||||||
|
# doesn't need to be correct
|
||||||
|
+ proto.string(2, "63faaff0-0000-23fe-80f0-582429d11c38")
|
||||||
|
)
|
||||||
|
# 1 - newest, 2 - popular
|
||||||
|
+ proto.uint(3, new_sort)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
return base64.urlsafe_b64encode(pointless_nest).decode('ascii')
|
||||||
|
|
||||||
|
# SORT:
|
||||||
|
# videos:
|
||||||
|
# Popular - 1
|
||||||
|
# Oldest - 2
|
||||||
|
# Newest - 3
|
||||||
|
# playlists:
|
||||||
|
# Oldest - 2
|
||||||
|
# Newest - 3
|
||||||
|
# Last video added - 4
|
||||||
|
|
||||||
|
# view:
|
||||||
|
# grid: 0 or 1
|
||||||
|
# list: 2
|
||||||
|
def channel_ctoken_v3(channel_id, page, sort, tab, view=1):
|
||||||
|
# page > 1 doesn't work when sorting by oldest
|
||||||
|
offset = 30*(int(page) - 1)
|
||||||
|
page_token = proto.string(61, proto.unpadded_b64encode(
|
||||||
|
proto.string(1, proto.unpadded_b64encode(proto.uint(1,offset)))
|
||||||
|
))
|
||||||
|
|
||||||
|
tab = proto.string(2, tab )
|
||||||
|
sort = proto.uint(3, int(sort))
|
||||||
|
|
||||||
|
shelf_view = proto.uint(4, 0)
|
||||||
|
view = proto.uint(6, int(view))
|
||||||
|
continuation_info = proto.string(3,
|
||||||
|
proto.percent_b64encode(tab + sort + shelf_view + view + page_token)
|
||||||
|
)
|
||||||
|
|
||||||
|
channel_id = proto.string(2, channel_id )
|
||||||
|
pointless_nest = proto.string(80226972, channel_id + continuation_info)
|
||||||
|
|
||||||
|
return base64.urlsafe_b64encode(pointless_nest).decode('ascii')
|
||||||
|
|
||||||
|
def channel_ctoken_v2(channel_id, page, sort, tab, view=1):
|
||||||
|
# see https://github.com/iv-org/invidious/issues/1319#issuecomment-671732646
|
||||||
|
# page > 1 doesn't work when sorting by oldest
|
||||||
|
offset = 30*(int(page) - 1)
|
||||||
|
schema_number = {
|
||||||
|
3: 6307666885028338688,
|
||||||
|
2: 17254859483345278706,
|
||||||
|
1: 16570086088270825023,
|
||||||
|
}[int(sort)]
|
||||||
|
page_token = proto.string(61, proto.unpadded_b64encode(proto.string(1,
|
||||||
|
proto.uint(1, schema_number) + proto.string(2,
|
||||||
|
proto.string(1, proto.unpadded_b64encode(proto.uint(1,offset)))
|
||||||
|
)
|
||||||
|
)))
|
||||||
|
|
||||||
|
tab = proto.string(2, tab )
|
||||||
|
sort = proto.uint(3, int(sort))
|
||||||
|
#page = proto.string(15, str(page) )
|
||||||
|
|
||||||
|
shelf_view = proto.uint(4, 0)
|
||||||
|
view = proto.uint(6, int(view))
|
||||||
|
continuation_info = proto.string(3,
|
||||||
|
proto.percent_b64encode(tab + sort + shelf_view + view + page_token)
|
||||||
|
)
|
||||||
|
|
||||||
|
channel_id = proto.string(2, channel_id )
|
||||||
|
pointless_nest = proto.string(80226972, channel_id + continuation_info)
|
||||||
|
|
||||||
|
return base64.urlsafe_b64encode(pointless_nest).decode('ascii')
|
||||||
|
|
||||||
|
def channel_ctoken_v1(channel_id, page, sort, tab, view=1):
|
||||||
|
tab = proto.string(2, tab )
|
||||||
|
sort = proto.uint(3, int(sort))
|
||||||
|
page = proto.string(15, str(page) )
|
||||||
|
# example with shelves in videos tab: https://www.youtube.com/channel/UCNL1ZadSjHpjm4q9j2sVtOA/videos
|
||||||
|
shelf_view = proto.uint(4, 0)
|
||||||
|
view = proto.uint(6, int(view))
|
||||||
|
continuation_info = proto.string(3, proto.percent_b64encode(tab + view + sort + shelf_view + page + proto.uint(23, 0)) )
|
||||||
|
|
||||||
|
channel_id = proto.string(2, channel_id )
|
||||||
|
pointless_nest = proto.string(80226972, channel_id + continuation_info)
|
||||||
|
|
||||||
|
return base64.urlsafe_b64encode(pointless_nest).decode('ascii')
|
||||||
|
|
||||||
|
def channel_about_ctoken(channel_id):
|
||||||
|
return proto.make_protobuf(
|
||||||
|
('base64p',
|
||||||
|
[
|
||||||
|
[2, 80226972,
|
||||||
|
[
|
||||||
|
[2, 2, channel_id],
|
||||||
|
[2, 3,
|
||||||
|
('base64p',
|
||||||
|
[
|
||||||
|
[2, 110,
|
||||||
|
[
|
||||||
|
[2, 3,
|
||||||
|
[
|
||||||
|
[2, 19,
|
||||||
|
[
|
||||||
|
[2, 1, b'66b0e9e9-0000-2820-9589-582429a83980'],
|
||||||
|
]
|
||||||
|
],
|
||||||
|
]
|
||||||
|
],
|
||||||
|
]
|
||||||
|
],
|
||||||
|
]
|
||||||
|
)
|
||||||
|
],
|
||||||
|
]
|
||||||
|
],
|
||||||
|
]
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
def get_channel_tab(channel_id, page="1", sort=3, tab='videos', view=1,
|
||||||
|
ctoken=None, print_status=True):
|
||||||
|
message = 'Got channel tab' if print_status else None
|
||||||
|
|
||||||
|
if not ctoken:
|
||||||
|
if tab in ('videos', 'shorts', 'streams'):
|
||||||
|
ctoken = channel_ctoken_v5(channel_id, page, sort, tab, view)
|
||||||
|
else:
|
||||||
|
ctoken = channel_ctoken_v3(channel_id, page, sort, tab, view)
|
||||||
|
ctoken = ctoken.replace('=', '%3D')
|
||||||
|
|
||||||
|
# Not sure what the purpose of the key is or whether it will change
|
||||||
|
# For now it seems to be constant for the API endpoint, not dependent
|
||||||
|
# on the browsing session or channel
|
||||||
|
key = 'AIzaSyAO_FJ2SlqU8Q4STEHLGCilw_Y9_11qcW8'
|
||||||
|
url = 'https://www.youtube.com/youtubei/v1/browse?key=' + key
|
||||||
|
|
||||||
|
data = {
|
||||||
|
'context': {
|
||||||
|
'client': {
|
||||||
|
'hl': 'en',
|
||||||
|
'gl': 'US',
|
||||||
|
'clientName': 'WEB',
|
||||||
|
'clientVersion': '2.20180830',
|
||||||
|
},
|
||||||
|
},
|
||||||
|
'continuation': ctoken,
|
||||||
|
}
|
||||||
|
|
||||||
|
content_type_header = (('Content-Type', 'application/json'),)
|
||||||
|
content = util.fetch_url(
|
||||||
|
url, headers_desktop + content_type_header,
|
||||||
|
data=json.dumps(data), debug_name='channel_tab', report_text=message)
|
||||||
|
|
||||||
|
return content
|
||||||
|
|
||||||
|
# cache entries expire after 30 minutes
|
||||||
|
number_of_videos_cache = cachetools.TTLCache(128, 30*60)
|
||||||
|
@cachetools.cached(number_of_videos_cache)
|
||||||
|
def get_number_of_videos_channel(channel_id):
|
||||||
|
if channel_id is None:
|
||||||
|
return 1000
|
||||||
|
|
||||||
|
# Uploads playlist
|
||||||
|
playlist_id = 'UU' + channel_id[2:]
|
||||||
|
url = 'https://m.youtube.com/playlist?list=' + playlist_id + '&pbj=1'
|
||||||
|
|
||||||
|
try:
|
||||||
|
response = util.fetch_url(url, headers_mobile,
|
||||||
|
debug_name='number_of_videos', report_text='Got number of videos')
|
||||||
|
except (urllib.error.HTTPError, util.FetchError) as e:
|
||||||
|
traceback.print_exc()
|
||||||
|
print("Couldn't retrieve number of videos")
|
||||||
|
return 1000
|
||||||
|
|
||||||
|
response = response.decode('utf-8')
|
||||||
|
|
||||||
|
# match = re.search(r'"numVideosText":\s*{\s*"runs":\s*\[{"text":\s*"([\d,]*) videos"', response)
|
||||||
|
match = re.search(r'"numVideosText".*?([,\d]+)', response)
|
||||||
|
if match:
|
||||||
|
return int(match.group(1).replace(',',''))
|
||||||
|
else:
|
||||||
|
return 0
|
||||||
|
def set_cached_number_of_videos(channel_id, num_videos):
|
||||||
|
@cachetools.cached(number_of_videos_cache)
|
||||||
|
def dummy_func_using_same_cache(channel_id):
|
||||||
|
return num_videos
|
||||||
|
dummy_func_using_same_cache(channel_id)
|
||||||
|
|
||||||
|
|
||||||
|
channel_id_re = re.compile(r'videos\.xml\?channel_id=([a-zA-Z0-9_-]{24})"')
|
||||||
|
@cachetools.func.lru_cache(maxsize=128)
|
||||||
|
def get_channel_id(base_url):
|
||||||
|
# method that gives the smallest possible response at ~4 kb
|
||||||
|
# needs to be as fast as possible
|
||||||
|
base_url = base_url.replace('https://www', 'https://m') # avoid redirect
|
||||||
|
response = util.fetch_url(base_url + '/about?pbj=1', headers_mobile,
|
||||||
|
debug_name='get_channel_id', report_text='Got channel id').decode('utf-8')
|
||||||
|
match = channel_id_re.search(response)
|
||||||
|
if match:
|
||||||
|
return match.group(1)
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
metadata_cache = cachetools.LRUCache(128)
|
||||||
|
@cachetools.cached(metadata_cache)
|
||||||
|
def get_metadata(channel_id):
|
||||||
|
base_url = 'https://www.youtube.com/channel/' + channel_id
|
||||||
|
polymer_json = util.fetch_url(base_url + '/about?pbj=1',
|
||||||
|
headers_desktop,
|
||||||
|
debug_name='gen_channel_about',
|
||||||
|
report_text='Retrieved channel metadata')
|
||||||
|
info = yt_data_extract.extract_channel_info(json.loads(polymer_json),
|
||||||
|
'about',
|
||||||
|
continuation=False)
|
||||||
|
return extract_metadata_for_caching(info)
|
||||||
|
def set_cached_metadata(channel_id, metadata):
|
||||||
|
@cachetools.cached(metadata_cache)
|
||||||
|
def dummy_func_using_same_cache(channel_id):
|
||||||
|
return metadata
|
||||||
|
dummy_func_using_same_cache(channel_id)
|
||||||
|
def extract_metadata_for_caching(channel_info):
|
||||||
|
metadata = {}
|
||||||
|
for key in ('approx_subscriber_count', 'short_description', 'channel_name',
|
||||||
|
'avatar'):
|
||||||
|
metadata[key] = channel_info[key]
|
||||||
|
return metadata
|
||||||
|
|
||||||
|
|
||||||
|
def get_number_of_videos_general(base_url):
|
||||||
|
return get_number_of_videos_channel(get_channel_id(base_url))
|
||||||
|
|
||||||
|
def get_channel_search_json(channel_id, query, page):
|
||||||
|
offset = proto.unpadded_b64encode(proto.uint(3, (page-1)*30))
|
||||||
|
params = proto.string(2, 'search') + proto.string(15, offset)
|
||||||
|
params = proto.percent_b64encode(params)
|
||||||
|
ctoken = proto.string(2, channel_id) + proto.string(3, params) + proto.string(11, query)
|
||||||
|
ctoken = base64.urlsafe_b64encode(proto.nested(80226972, ctoken)).decode('ascii')
|
||||||
|
|
||||||
|
key = 'AIzaSyAO_FJ2SlqU8Q4STEHLGCilw_Y9_11qcW8'
|
||||||
|
url = 'https://www.youtube.com/youtubei/v1/browse?key=' + key
|
||||||
|
|
||||||
|
data = {
|
||||||
|
'context': {
|
||||||
|
'client': {
|
||||||
|
'hl': 'en',
|
||||||
|
'gl': 'US',
|
||||||
|
'clientName': 'WEB',
|
||||||
|
'clientVersion': '2.20180830',
|
||||||
|
},
|
||||||
|
},
|
||||||
|
'continuation': ctoken,
|
||||||
|
}
|
||||||
|
|
||||||
|
content_type_header = (('Content-Type', 'application/json'),)
|
||||||
|
polymer_json = util.fetch_url(
|
||||||
|
url, headers_desktop + content_type_header,
|
||||||
|
data=json.dumps(data), debug_name='channel_search')
|
||||||
|
|
||||||
|
return polymer_json
|
||||||
|
|
||||||
|
|
||||||
|
def post_process_channel_info(info):
|
||||||
|
info['avatar'] = util.prefix_url(info['avatar'])
|
||||||
|
info['channel_url'] = util.prefix_url(info['channel_url'])
|
||||||
|
for item in info['items']:
|
||||||
|
util.prefix_urls(item)
|
||||||
|
util.add_extra_html_info(item)
|
||||||
|
if info['current_tab'] == 'about':
|
||||||
|
for i, (text, url) in enumerate(info['links']):
|
||||||
|
if isinstance(url, str) and util.YOUTUBE_URL_RE.fullmatch(url):
|
||||||
|
info['links'][i] = (text, util.prefix_url(url))
|
||||||
|
|
||||||
|
|
||||||
|
def get_channel_first_page(base_url=None, tab='videos', channel_id=None):
|
||||||
|
if channel_id:
|
||||||
|
base_url = 'https://www.youtube.com/channel/' + channel_id
|
||||||
|
return util.fetch_url(base_url + '/' + tab + '?pbj=1&view=0',
|
||||||
|
headers_desktop, debug_name='gen_channel_' + tab)
|
||||||
|
|
||||||
|
|
||||||
|
playlist_sort_codes = {'2': "da", '3': "dd", '4': "lad"}
|
||||||
|
|
||||||
|
# youtube.com/[channel_id]/[tab]
|
||||||
|
# youtube.com/user/[username]/[tab]
|
||||||
|
# youtube.com/c/[custom]/[tab]
|
||||||
|
# youtube.com/[custom]/[tab]
|
||||||
|
def get_channel_page_general_url(base_url, tab, request, channel_id=None):
|
||||||
|
|
||||||
|
page_number = int(request.args.get('page', 1))
|
||||||
|
# sort 1: views
|
||||||
|
# sort 2: oldest
|
||||||
|
# sort 3: newest
|
||||||
|
# sort 4: newest - no shorts (Just a kludge on our end, not internal to yt)
|
||||||
|
default_sort = '3' if settings.include_shorts_in_channel else '4'
|
||||||
|
sort = request.args.get('sort', default_sort)
|
||||||
|
view = request.args.get('view', '1')
|
||||||
|
query = request.args.get('query', '')
|
||||||
|
ctoken = request.args.get('ctoken', '')
|
||||||
|
include_shorts = (sort != '4')
|
||||||
|
default_params = (page_number == 1 and sort in ('3', '4') and view == '1')
|
||||||
|
continuation = bool(ctoken) # whether or not we're using a continuation
|
||||||
|
page_size = 30
|
||||||
|
try_channel_api = True
|
||||||
|
polymer_json = None
|
||||||
|
|
||||||
|
# Use the special UU playlist which contains all the channel's uploads
|
||||||
|
if tab == 'videos' and sort in ('3', '4'):
|
||||||
|
if not channel_id:
|
||||||
|
channel_id = get_channel_id(base_url)
|
||||||
|
if page_number == 1 and include_shorts:
|
||||||
|
tasks = (
|
||||||
|
gevent.spawn(playlist.playlist_first_page,
|
||||||
|
'UU' + channel_id[2:],
|
||||||
|
report_text='Retrieved channel videos'),
|
||||||
|
gevent.spawn(get_metadata, channel_id),
|
||||||
|
)
|
||||||
|
gevent.joinall(tasks)
|
||||||
|
util.check_gevent_exceptions(*tasks)
|
||||||
|
|
||||||
|
# Ignore the metadata for now, it is cached and will be
|
||||||
|
# recalled later
|
||||||
|
pl_json = tasks[0].value
|
||||||
|
pl_info = yt_data_extract.extract_playlist_info(pl_json)
|
||||||
|
number_of_videos = pl_info['metadata']['video_count']
|
||||||
|
if number_of_videos is None:
|
||||||
|
number_of_videos = 1000
|
||||||
|
else:
|
||||||
|
set_cached_number_of_videos(channel_id, number_of_videos)
|
||||||
|
else:
|
||||||
|
tasks = (
|
||||||
|
gevent.spawn(playlist.get_videos, 'UU' + channel_id[2:],
|
||||||
|
page_number, include_shorts=include_shorts),
|
||||||
|
gevent.spawn(get_metadata, channel_id),
|
||||||
|
gevent.spawn(get_number_of_videos_channel, channel_id),
|
||||||
|
)
|
||||||
|
gevent.joinall(tasks)
|
||||||
|
util.check_gevent_exceptions(*tasks)
|
||||||
|
|
||||||
|
pl_json = tasks[0].value
|
||||||
|
pl_info = yt_data_extract.extract_playlist_info(pl_json)
|
||||||
|
number_of_videos = tasks[2].value
|
||||||
|
info = pl_info
|
||||||
|
info['channel_id'] = channel_id
|
||||||
|
info['current_tab'] = 'videos'
|
||||||
|
if info['items']: # Success
|
||||||
|
page_size = 100
|
||||||
|
try_channel_api = False
|
||||||
|
else: # Try the first-page method next
|
||||||
|
try_channel_api = True
|
||||||
|
|
||||||
|
# Use the regular channel API
|
||||||
|
if tab in ('shorts', 'streams') or (tab=='videos' and try_channel_api):
|
||||||
|
if channel_id:
|
||||||
|
num_videos_call = (get_number_of_videos_channel, channel_id)
|
||||||
|
else:
|
||||||
|
num_videos_call = (get_number_of_videos_general, base_url)
|
||||||
|
|
||||||
|
# Use ctoken method, which YouTube changes all the time
|
||||||
|
if channel_id and not default_params:
|
||||||
|
if sort == 4:
|
||||||
|
_sort = 3
|
||||||
|
else:
|
||||||
|
_sort = sort
|
||||||
|
page_call = (get_channel_tab, channel_id, page_number, _sort,
|
||||||
|
tab, view, ctoken)
|
||||||
|
# Use the first-page method, which won't break
|
||||||
|
else:
|
||||||
|
page_call = (get_channel_first_page, base_url, tab)
|
||||||
|
|
||||||
|
tasks = (
|
||||||
|
gevent.spawn(*num_videos_call),
|
||||||
|
gevent.spawn(*page_call),
|
||||||
|
)
|
||||||
|
gevent.joinall(tasks)
|
||||||
|
util.check_gevent_exceptions(*tasks)
|
||||||
|
number_of_videos, polymer_json = tasks[0].value, tasks[1].value
|
||||||
|
|
||||||
|
elif tab == 'about':
|
||||||
|
#polymer_json = util.fetch_url(base_url + '/about?pbj=1', headers_desktop, debug_name='gen_channel_about')
|
||||||
|
channel_id = get_channel_id(base_url)
|
||||||
|
ctoken = channel_about_ctoken(channel_id)
|
||||||
|
polymer_json = util.call_youtube_api('web', 'browse', {
|
||||||
|
'continuation': ctoken,
|
||||||
|
})
|
||||||
|
continuation=True
|
||||||
|
elif tab == 'playlists' and page_number == 1:
|
||||||
|
polymer_json = util.fetch_url(base_url+ '/playlists?pbj=1&view=1&sort=' + playlist_sort_codes[sort], headers_desktop, debug_name='gen_channel_playlists')
|
||||||
|
elif tab == 'playlists':
|
||||||
|
polymer_json = get_channel_tab(channel_id, page_number, sort,
|
||||||
|
'playlists', view)
|
||||||
|
continuation = True
|
||||||
|
elif tab == 'search' and channel_id:
|
||||||
|
polymer_json = get_channel_search_json(channel_id, query, page_number)
|
||||||
|
elif tab == 'search':
|
||||||
|
url = base_url + '/search?pbj=1&query=' + urllib.parse.quote(query, safe='')
|
||||||
|
polymer_json = util.fetch_url(url, headers_desktop, debug_name='gen_channel_search')
|
||||||
|
elif tab == 'videos':
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
flask.abort(404, 'Unknown channel tab: ' + tab)
|
||||||
|
|
||||||
|
if polymer_json is not None:
|
||||||
|
info = yt_data_extract.extract_channel_info(
|
||||||
|
json.loads(polymer_json), tab, continuation=continuation
|
||||||
|
)
|
||||||
|
|
||||||
|
if info['error'] is not None:
|
||||||
|
return flask.render_template('error.html', error_message=info['error'])
|
||||||
|
|
||||||
|
if channel_id:
|
||||||
|
info['channel_url'] = 'https://www.youtube.com/channel/' + channel_id
|
||||||
|
info['channel_id'] = channel_id
|
||||||
|
else:
|
||||||
|
channel_id = info['channel_id']
|
||||||
|
|
||||||
|
# Will have microformat present, cache metadata while we have it
|
||||||
|
if channel_id and default_params and tab not in ('videos', 'about'):
|
||||||
|
metadata = extract_metadata_for_caching(info)
|
||||||
|
set_cached_metadata(channel_id, metadata)
|
||||||
|
# Otherwise, populate with our (hopefully cached) metadata
|
||||||
|
elif channel_id and info.get('channel_name') is None:
|
||||||
|
metadata = get_metadata(channel_id)
|
||||||
|
for key, value in metadata.items():
|
||||||
|
yt_data_extract.conservative_update(info, key, value)
|
||||||
|
# need to add this metadata to the videos/playlists
|
||||||
|
additional_info = {
|
||||||
|
'author': info['channel_name'],
|
||||||
|
'author_id': info['channel_id'],
|
||||||
|
'author_url': info['channel_url'],
|
||||||
|
}
|
||||||
|
for item in info['items']:
|
||||||
|
item.update(additional_info)
|
||||||
|
|
||||||
|
if tab in ('videos', 'shorts', 'streams'):
|
||||||
|
info['number_of_videos'] = number_of_videos
|
||||||
|
info['number_of_pages'] = math.ceil(number_of_videos/page_size)
|
||||||
|
info['header_playlist_names'] = local_playlist.get_playlist_names()
|
||||||
|
if tab in ('videos', 'shorts', 'streams', 'playlists'):
|
||||||
|
info['current_sort'] = sort
|
||||||
|
elif tab == 'search':
|
||||||
|
info['search_box_value'] = query
|
||||||
|
info['header_playlist_names'] = local_playlist.get_playlist_names()
|
||||||
|
if tab in ('search', 'playlists'):
|
||||||
|
info['page_number'] = page_number
|
||||||
|
info['subscribed'] = subscriptions.is_subscribed(info['channel_id'])
|
||||||
|
|
||||||
|
post_process_channel_info(info)
|
||||||
|
|
||||||
|
return flask.render_template('channel.html',
|
||||||
|
parameters_dictionary = request.args,
|
||||||
|
**info
|
||||||
|
)
|
||||||
|
|
||||||
|
@yt_app.route('/channel/<channel_id>/')
|
||||||
|
@yt_app.route('/channel/<channel_id>/<tab>')
|
||||||
|
def get_channel_page(channel_id, tab='videos'):
|
||||||
|
return get_channel_page_general_url('https://www.youtube.com/channel/' + channel_id, tab, request, channel_id)
|
||||||
|
|
||||||
|
@yt_app.route('/user/<username>/')
|
||||||
|
@yt_app.route('/user/<username>/<tab>')
|
||||||
|
def get_user_page(username, tab='videos'):
|
||||||
|
return get_channel_page_general_url('https://www.youtube.com/user/' + username, tab, request)
|
||||||
|
|
||||||
|
@yt_app.route('/c/<custom>/')
|
||||||
|
@yt_app.route('/c/<custom>/<tab>')
|
||||||
|
def get_custom_c_page(custom, tab='videos'):
|
||||||
|
return get_channel_page_general_url('https://www.youtube.com/c/' + custom, tab, request)
|
||||||
|
|
||||||
|
@yt_app.route('/<custom>')
|
||||||
|
@yt_app.route('/<custom>/<tab>')
|
||||||
|
def get_toplevel_custom_page(custom, tab='videos'):
|
||||||
|
return get_channel_page_general_url('https://www.youtube.com/' + custom, tab, request)
|
||||||
|
|
||||||
227
youtube/comments.py
Normal file
227
youtube/comments.py
Normal file
@@ -0,0 +1,227 @@
|
|||||||
|
from youtube import proto, util, yt_data_extract
|
||||||
|
from youtube.util import concat_or_none
|
||||||
|
from youtube import yt_app
|
||||||
|
import settings
|
||||||
|
|
||||||
|
import json
|
||||||
|
import base64
|
||||||
|
import urllib
|
||||||
|
import re
|
||||||
|
import traceback
|
||||||
|
|
||||||
|
import flask
|
||||||
|
from flask import request
|
||||||
|
|
||||||
|
# Here's what I know about the secret key (starting with ASJN_i)
|
||||||
|
# *The secret key definitely contains the following information (or perhaps the information is stored at youtube's servers):
|
||||||
|
# -Video id
|
||||||
|
# -Offset
|
||||||
|
# -Sort
|
||||||
|
# *If the video id or sort in the ctoken contradicts the ASJN, the response is an error. The offset encoded outside the ASJN is ignored entirely.
|
||||||
|
# *The ASJN is base64 encoded data, indicated by the fact that the character after "ASJN_i" is one of ("0", "1", "2", "3")
|
||||||
|
# *The encoded data is not valid protobuf
|
||||||
|
# *The encoded data (after the 5 or so bytes that are always the same) is indistinguishable from random data according to a battery of randomness tests
|
||||||
|
# *The ASJN in the ctoken provided by a response changes in regular intervals of about a second or two.
|
||||||
|
# *Old ASJN's continue to work, and start at the same comment even if new comments have been posted since
|
||||||
|
# *The ASJN has no relation with any of the data in the response it came from
|
||||||
|
|
||||||
|
def make_comment_ctoken(video_id, sort=0, offset=0, lc='', secret_key=''):
|
||||||
|
video_id = proto.as_bytes(video_id)
|
||||||
|
secret_key = proto.as_bytes(secret_key)
|
||||||
|
|
||||||
|
|
||||||
|
page_info = proto.string(4,video_id) + proto.uint(6, sort)
|
||||||
|
offset_information = proto.nested(4, page_info) + proto.uint(5, offset)
|
||||||
|
if secret_key:
|
||||||
|
offset_information = proto.string(1, secret_key) + offset_information
|
||||||
|
|
||||||
|
page_params = proto.string(2, video_id)
|
||||||
|
if lc:
|
||||||
|
page_params += proto.string(6, proto.percent_b64encode(proto.string(15, lc)))
|
||||||
|
|
||||||
|
result = proto.nested(2, page_params) + proto.uint(3,6) + proto.nested(6, offset_information)
|
||||||
|
return base64.urlsafe_b64encode(result).decode('ascii')
|
||||||
|
|
||||||
|
|
||||||
|
def request_comments(ctoken, replies=False):
|
||||||
|
url = 'https://m.youtube.com/youtubei/v1/next'
|
||||||
|
url += '?key=AIzaSyAO_FJ2SlqU8Q4STEHLGCilw_Y9_11qcW8'
|
||||||
|
data = json.dumps({
|
||||||
|
'context': {
|
||||||
|
'client': {
|
||||||
|
'hl': 'en',
|
||||||
|
'gl': 'US',
|
||||||
|
'clientName': 'MWEB',
|
||||||
|
'clientVersion': '2.20210804.02.00',
|
||||||
|
},
|
||||||
|
},
|
||||||
|
'continuation': ctoken.replace('=', '%3D'),
|
||||||
|
})
|
||||||
|
|
||||||
|
content = util.fetch_url(
|
||||||
|
url, headers=util.mobile_xhr_headers + util.json_header, data=data,
|
||||||
|
report_text='Retrieved comments', debug_name='request_comments')
|
||||||
|
content = content.decode('utf-8')
|
||||||
|
|
||||||
|
polymer_json = json.loads(content)
|
||||||
|
return polymer_json
|
||||||
|
|
||||||
|
|
||||||
|
def single_comment_ctoken(video_id, comment_id):
|
||||||
|
page_params = proto.string(2, video_id) + proto.string(6, proto.percent_b64encode(proto.string(15, comment_id)))
|
||||||
|
|
||||||
|
result = proto.nested(2, page_params) + proto.uint(3,6)
|
||||||
|
return base64.urlsafe_b64encode(result).decode('ascii')
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def post_process_comments_info(comments_info):
|
||||||
|
for comment in comments_info['comments']:
|
||||||
|
comment['author_url'] = concat_or_none(
|
||||||
|
'/', comment['author_url'])
|
||||||
|
comment['author_avatar'] = concat_or_none(
|
||||||
|
settings.img_prefix, comment['author_avatar'])
|
||||||
|
|
||||||
|
comment['permalink'] = concat_or_none(util.URL_ORIGIN, '/watch?v=',
|
||||||
|
comments_info['video_id'], '&lc=', comment['id'])
|
||||||
|
|
||||||
|
|
||||||
|
reply_count = comment['reply_count']
|
||||||
|
comment['replies_url'] = None
|
||||||
|
if comment['reply_ctoken']:
|
||||||
|
# change max_replies field to 250 in ctoken
|
||||||
|
ctoken = comment['reply_ctoken']
|
||||||
|
ctoken, err = proto.set_protobuf_value(
|
||||||
|
ctoken,
|
||||||
|
'base64p', 6, 3, 9, value=200)
|
||||||
|
if err:
|
||||||
|
print('Error setting ctoken value:')
|
||||||
|
print(err)
|
||||||
|
comment['replies_url'] = None
|
||||||
|
comment['replies_url'] = concat_or_none(util.URL_ORIGIN,
|
||||||
|
'/comments?replies=1&ctoken=' + ctoken)
|
||||||
|
|
||||||
|
if reply_count == 0:
|
||||||
|
comment['view_replies_text'] = 'Reply'
|
||||||
|
elif reply_count == 1:
|
||||||
|
comment['view_replies_text'] = '1 reply'
|
||||||
|
else:
|
||||||
|
comment['view_replies_text'] = str(reply_count) + ' replies'
|
||||||
|
|
||||||
|
|
||||||
|
if comment['approx_like_count'] == '1':
|
||||||
|
comment['likes_text'] = '1 like'
|
||||||
|
else:
|
||||||
|
comment['likes_text'] = (str(comment['approx_like_count'])
|
||||||
|
+ ' likes')
|
||||||
|
|
||||||
|
comments_info['include_avatars'] = settings.enable_comment_avatars
|
||||||
|
if comments_info['ctoken']:
|
||||||
|
ctoken = comments_info['ctoken']
|
||||||
|
if comments_info['is_replies']:
|
||||||
|
replies_param = '&replies=1'
|
||||||
|
# change max_replies field to 250 in ctoken
|
||||||
|
new_ctoken, err = proto.set_protobuf_value(
|
||||||
|
ctoken,
|
||||||
|
'base64p', 6, 3, 9, value=200)
|
||||||
|
if err:
|
||||||
|
print('Error setting ctoken value:')
|
||||||
|
print(err)
|
||||||
|
else:
|
||||||
|
ctoken = new_ctoken
|
||||||
|
else:
|
||||||
|
replies_param = ''
|
||||||
|
comments_info['more_comments_url'] = concat_or_none(util.URL_ORIGIN,
|
||||||
|
'/comments?ctoken=', ctoken, replies_param)
|
||||||
|
|
||||||
|
if comments_info['offset'] is None:
|
||||||
|
comments_info['page_number'] = None
|
||||||
|
else:
|
||||||
|
comments_info['page_number'] = int(comments_info['offset']/20) + 1
|
||||||
|
|
||||||
|
if not comments_info['is_replies']:
|
||||||
|
comments_info['sort_text'] = 'top' if comments_info['sort'] == 0 else 'newest'
|
||||||
|
|
||||||
|
|
||||||
|
comments_info['video_url'] = concat_or_none(util.URL_ORIGIN,
|
||||||
|
'/watch?v=', comments_info['video_id'])
|
||||||
|
comments_info['video_thumbnail'] = concat_or_none(settings.img_prefix, 'https://i.ytimg.com/vi/',
|
||||||
|
comments_info['video_id'], '/mqdefault.jpg')
|
||||||
|
|
||||||
|
|
||||||
|
def video_comments(video_id, sort=0, offset=0, lc='', secret_key=''):
|
||||||
|
try:
|
||||||
|
if settings.comments_mode:
|
||||||
|
comments_info = {'error': None}
|
||||||
|
other_sort_url = (
|
||||||
|
util.URL_ORIGIN + '/comments?ctoken='
|
||||||
|
+ make_comment_ctoken(video_id, sort=1 - sort, lc=lc)
|
||||||
|
)
|
||||||
|
other_sort_text = 'Sort by ' + ('newest' if sort == 0 else 'top')
|
||||||
|
|
||||||
|
this_sort_url = (util.URL_ORIGIN
|
||||||
|
+ '/comments?ctoken='
|
||||||
|
+ make_comment_ctoken(video_id, sort=sort, lc=lc))
|
||||||
|
|
||||||
|
comments_info['comment_links'] = [
|
||||||
|
(other_sort_text, other_sort_url),
|
||||||
|
('Direct link', this_sort_url)
|
||||||
|
]
|
||||||
|
|
||||||
|
ctoken = make_comment_ctoken(video_id, sort, offset, lc)
|
||||||
|
comments_info.update(yt_data_extract.extract_comments_info(
|
||||||
|
request_comments(ctoken), ctoken=ctoken
|
||||||
|
))
|
||||||
|
post_process_comments_info(comments_info)
|
||||||
|
|
||||||
|
return comments_info
|
||||||
|
else:
|
||||||
|
return {}
|
||||||
|
except util.FetchError as e:
|
||||||
|
if e.code == '429' and settings.route_tor:
|
||||||
|
comments_info['error'] = 'Error: Youtube blocked the request because the Tor exit node is overutilized.'
|
||||||
|
if e.error_message:
|
||||||
|
comments_info['error'] += '\n\n' + e.error_message
|
||||||
|
comments_info['error'] += '\n\nExit node IP address: %s' % e.ip
|
||||||
|
else:
|
||||||
|
comments_info['error'] = traceback.format_exc()
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
comments_info['error'] = traceback.format_exc()
|
||||||
|
|
||||||
|
if comments_info.get('error'):
|
||||||
|
print('Error retrieving comments for ' + str(video_id) + ':\n' +
|
||||||
|
comments_info['error'])
|
||||||
|
|
||||||
|
return comments_info
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
@yt_app.route('/comments')
|
||||||
|
def get_comments_page():
|
||||||
|
ctoken = request.args.get('ctoken', '')
|
||||||
|
replies = request.args.get('replies', '0') == '1'
|
||||||
|
|
||||||
|
comments_info = yt_data_extract.extract_comments_info(
|
||||||
|
request_comments(ctoken, replies), ctoken=ctoken
|
||||||
|
)
|
||||||
|
post_process_comments_info(comments_info)
|
||||||
|
|
||||||
|
if not replies:
|
||||||
|
if comments_info['sort'] is None or comments_info['video_id'] is None:
|
||||||
|
other_sort_url = None
|
||||||
|
else:
|
||||||
|
other_sort_url = (
|
||||||
|
util.URL_ORIGIN
|
||||||
|
+ '/comments?ctoken='
|
||||||
|
+ make_comment_ctoken(comments_info['video_id'],
|
||||||
|
sort=1-comments_info['sort'])
|
||||||
|
)
|
||||||
|
other_sort_text = 'Sort by ' + ('newest' if comments_info['sort'] == 0 else 'top')
|
||||||
|
comments_info['comment_links'] = [(other_sort_text, other_sort_url)]
|
||||||
|
|
||||||
|
return flask.render_template('comments_page.html',
|
||||||
|
comments_info = comments_info,
|
||||||
|
slim = request.args.get('slim', False)
|
||||||
|
)
|
||||||
|
|
||||||
10
youtube/cookies.txt
Normal file
10
youtube/cookies.txt
Normal file
@@ -0,0 +1,10 @@
|
|||||||
|
YSC=vxJBAKp8ZBU
|
||||||
|
HSID=ARhJf4ZiTwv-zZ1iN
|
||||||
|
SSID=AtjAHEYvW3yqmlkTm
|
||||||
|
APISID=5FF0_mMhXYMqa3XD/A3qLiaUStJzysC8Ey
|
||||||
|
SAPISID=f2wDD0vsUXOi7YOH/A-KCojLcWvjf_5LhI
|
||||||
|
SID=g.a000yghPLdX7ghgjfg2yjRhNurEJb85QJlEtIc4CehoZd1k8nudOKCgyI9i6xZMPxWJpV5c2PQACgYKAfUSARUSFQHGX2MiqehdQAWbTfgE1onFjpCD6RoVAUF8yKp0XpcgTWwPPW6-9YNEmiRU0076
|
||||||
|
LOGIN_INFO=AFmmF2swRQIhAKhSU8vaPKnJf2gtFOxa7HujVpp4Rm5W01KpmJI88-ohAiAoe4OXpbe-5PKxyujAhe_FhF_F_iihGTz32LDTlUHlSw:QUQ3MjNmeDY5bGFzaThnRzk4Ylpma1hGbEdJTTFLREhFNzh3aGpHcXFENnVOUHpVU0JBdGhzVy1tdkIybmZKUDc1QXFjYTYzaE1LQ0FCUEZ0YXZ0Q0NnckFJanUwU3ZYTVlXN3UwcGV0TVBibTAyZTRGaGswQmxmSjh5akRPLTBhX3cxb2ZRRXdZUk5EVXJCVnRPdktoTE5NNG1jR3dyOG9n
|
||||||
|
VISITOR_INFO1_LIVE=rIHBAH0X_mc
|
||||||
|
PREF=f6=40000000&tz=America.Los_Angeles&f5=20000&f7=140
|
||||||
|
SIDCC=AKEyXzUf9NsQM8hesZiykJAuil-72L9uWd7XNIjSAxYXKrR9OGPRmhT9aSIngXpUEurmmyDA7g
|
||||||
29
youtube/extract_cookies_from_json.py
Normal file
29
youtube/extract_cookies_from_json.py
Normal file
@@ -0,0 +1,29 @@
|
|||||||
|
import json
|
||||||
|
import os
|
||||||
|
|
||||||
|
# List of cookie names needed for YouTube authentication
|
||||||
|
NEEDED_COOKIES = [
|
||||||
|
'SID', 'HSID', 'SSID', 'APISID', 'SAPISID', 'LOGIN_INFO', 'YSC', 'PREF', 'VISITOR_INFO1_LIVE',
|
||||||
|
'SIDCC', 'SECURE3PSID', 'SECURE3PAPISID', 'SECURE3PSIDCC', 'SID', 'SSID', 'HSID', 'SSID', 'APISID', 'SAPISID'
|
||||||
|
]
|
||||||
|
|
||||||
|
def extract_and_save_cookies(json_path, txt_path):
|
||||||
|
with open(json_path, 'r', encoding='utf-8') as f:
|
||||||
|
cookies = json.load(f)
|
||||||
|
found = 0
|
||||||
|
with open(txt_path, 'w', encoding='utf-8') as out:
|
||||||
|
for cookie in cookies:
|
||||||
|
name = cookie.get('Name raw')
|
||||||
|
value = cookie.get('Content raw')
|
||||||
|
if name in NEEDED_COOKIES and value:
|
||||||
|
out.write(f"{name}={value}\n")
|
||||||
|
found += 1
|
||||||
|
print(f"Saved {found} cookies to {txt_path}")
|
||||||
|
if found == 0:
|
||||||
|
print("No needed cookies found! Check your JSON export and NEEDED_COOKIES list.")
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
# Update these paths as needed
|
||||||
|
json_path = os.path.join(os.path.dirname(__file__), 'cookies_export.json')
|
||||||
|
txt_path = os.path.join(os.path.dirname(__file__), 'cookies.txt')
|
||||||
|
extract_and_save_cookies(json_path, txt_path)
|
||||||
38
youtube/fetch_youtube_cookies.py
Normal file
38
youtube/fetch_youtube_cookies.py
Normal file
@@ -0,0 +1,38 @@
|
|||||||
|
import time
|
||||||
|
from selenium import webdriver
|
||||||
|
from selenium.webdriver.firefox.options import Options
|
||||||
|
import os
|
||||||
|
|
||||||
|
def save_cookies_to_txt(cookies, path):
|
||||||
|
with open(path, 'w', encoding='utf-8') as f:
|
||||||
|
for cookie in cookies:
|
||||||
|
if 'name' in cookie and 'value' in cookie:
|
||||||
|
f.write(f"{cookie['name']}={cookie['value']}\n")
|
||||||
|
|
||||||
|
def main():
|
||||||
|
# Update this path to your actual Mercury profile directory
|
||||||
|
mercury_profile_path = r"C:/Users/spong/AppData/Roaming/mercury/Profiles"
|
||||||
|
# Auto-detect the first profile (or let user specify)
|
||||||
|
profiles = [d for d in os.listdir(mercury_profile_path) if d.endswith('.default') or d.endswith('.default-release') or d.endswith('.default-esr')]
|
||||||
|
if not profiles:
|
||||||
|
print("No Mercury profiles found in:", mercury_profile_path)
|
||||||
|
return
|
||||||
|
profile_dir = os.path.join(mercury_profile_path, profiles[0])
|
||||||
|
print(f"Using Mercury profile: {profile_dir}")
|
||||||
|
firefox_options = Options()
|
||||||
|
firefox_options.set_preference('profile', profile_dir)
|
||||||
|
# Set Mercury browser binary location
|
||||||
|
firefox_options.binary_location = r"C:/Program Files/Mercury/mercury.exe" # Update this path if needed
|
||||||
|
print("Opening Mercury browser to https://www.youtube.com using your real profile ...")
|
||||||
|
driver = webdriver.Firefox(options=firefox_options)
|
||||||
|
driver.get('https://www.youtube.com')
|
||||||
|
print("If not already logged in, log in to your YouTube account in the opened browser window.")
|
||||||
|
input("Press Enter here after you have logged in and the YouTube homepage is fully loaded...")
|
||||||
|
cookies = driver.get_cookies()
|
||||||
|
cookies_path = os.path.join(os.path.dirname(__file__), 'cookies.txt')
|
||||||
|
save_cookies_to_txt(cookies, cookies_path)
|
||||||
|
print(f"Cookies saved to {cookies_path}")
|
||||||
|
driver.quit()
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
40
youtube/home.py
Normal file
40
youtube/home.py
Normal file
@@ -0,0 +1,40 @@
|
|||||||
|
from youtube import util
|
||||||
|
import flask
|
||||||
|
import os
|
||||||
|
|
||||||
|
def get_youtube_cookies():
|
||||||
|
"""Read cookies.txt and return a dict of cookies for YouTube requests."""
|
||||||
|
cookies_path = os.path.join(os.path.dirname(__file__), 'cookies.txt')
|
||||||
|
cookies = {}
|
||||||
|
if os.path.isfile(cookies_path):
|
||||||
|
with open(cookies_path, 'r', encoding='utf-8') as f:
|
||||||
|
for line in f:
|
||||||
|
line = line.strip()
|
||||||
|
if not line or line.startswith('#') or '=' not in line:
|
||||||
|
continue
|
||||||
|
k, v = line.split('=', 1)
|
||||||
|
cookies[k.strip()] = v.strip()
|
||||||
|
return cookies
|
||||||
|
|
||||||
|
def get_recommended_videos():
|
||||||
|
# Use YouTube's browse API to get the home feed (recommended videos)
|
||||||
|
data = {"browseId": "FEwhat_to_watch"}
|
||||||
|
cookies = get_youtube_cookies()
|
||||||
|
response = util.call_youtube_api("web", "browse", data, cookies=cookies)
|
||||||
|
response_json = flask.json.loads(response)
|
||||||
|
# Extract video list from response_json
|
||||||
|
try:
|
||||||
|
contents = response_json["contents"]["twoColumnBrowseResultsRenderer"]["tabs"][0]["tabRenderer"]["content"]["richGridRenderer"]["contents"]
|
||||||
|
videos = []
|
||||||
|
for item in contents:
|
||||||
|
renderer = item.get("richItemRenderer", {}).get("content", {}).get("videoRenderer")
|
||||||
|
if renderer:
|
||||||
|
videos.append(renderer)
|
||||||
|
# If no videos found, check for nudge/empty feed
|
||||||
|
if not videos:
|
||||||
|
print("No recommended videos found. YouTube may require login or watch history.")
|
||||||
|
return videos
|
||||||
|
except Exception as e:
|
||||||
|
print("Error extracting recommended videos:", e)
|
||||||
|
print("Response JSON:", response_json)
|
||||||
|
return []
|
||||||
197
youtube/local_playlist.py
Normal file
197
youtube/local_playlist.py
Normal file
@@ -0,0 +1,197 @@
|
|||||||
|
from youtube import util, yt_data_extract
|
||||||
|
from youtube import yt_app
|
||||||
|
import settings
|
||||||
|
|
||||||
|
import os
|
||||||
|
import json
|
||||||
|
import html
|
||||||
|
import gevent
|
||||||
|
import urllib
|
||||||
|
import math
|
||||||
|
|
||||||
|
import flask
|
||||||
|
from flask import request
|
||||||
|
|
||||||
|
playlists_directory = os.path.join(settings.data_dir, "playlists")
|
||||||
|
thumbnails_directory = os.path.join(settings.data_dir, "playlist_thumbnails")
|
||||||
|
|
||||||
|
def video_ids_in_playlist(name):
|
||||||
|
try:
|
||||||
|
with open(os.path.join(playlists_directory, name + ".txt"), 'r', encoding='utf-8') as file:
|
||||||
|
videos = file.read()
|
||||||
|
return set(json.loads(video)['id'] for video in videos.splitlines())
|
||||||
|
except FileNotFoundError:
|
||||||
|
return set()
|
||||||
|
|
||||||
|
def add_to_playlist(name, video_info_list):
|
||||||
|
if not os.path.exists(playlists_directory):
|
||||||
|
os.makedirs(playlists_directory)
|
||||||
|
ids = video_ids_in_playlist(name)
|
||||||
|
missing_thumbnails = []
|
||||||
|
with open(os.path.join(playlists_directory, name + ".txt"), "a", encoding='utf-8') as file:
|
||||||
|
for info in video_info_list:
|
||||||
|
id = json.loads(info)['id']
|
||||||
|
if id not in ids:
|
||||||
|
file.write(info + "\n")
|
||||||
|
missing_thumbnails.append(id)
|
||||||
|
gevent.spawn(util.download_thumbnails, os.path.join(thumbnails_directory, name), missing_thumbnails)
|
||||||
|
|
||||||
|
|
||||||
|
def add_extra_info_to_videos(videos, playlist_name):
|
||||||
|
'''Adds extra information necessary for rendering the video item HTML
|
||||||
|
|
||||||
|
Downloads missing thumbnails'''
|
||||||
|
try:
|
||||||
|
thumbnails = set(os.listdir(os.path.join(thumbnails_directory,
|
||||||
|
playlist_name)))
|
||||||
|
except FileNotFoundError:
|
||||||
|
thumbnails = set()
|
||||||
|
missing_thumbnails = []
|
||||||
|
|
||||||
|
for video in videos:
|
||||||
|
video['type'] = 'video'
|
||||||
|
util.add_extra_html_info(video)
|
||||||
|
if video['id'] + '.jpg' in thumbnails:
|
||||||
|
video['thumbnail'] = (
|
||||||
|
'/https://youtube.com/data/playlist_thumbnails/'
|
||||||
|
+ playlist_name
|
||||||
|
+ '/' + video['id'] + '.jpg')
|
||||||
|
else:
|
||||||
|
video['thumbnail'] = util.get_thumbnail_url(video['id'])
|
||||||
|
missing_thumbnails.append(video['id'])
|
||||||
|
|
||||||
|
gevent.spawn(util.download_thumbnails,
|
||||||
|
os.path.join(thumbnails_directory, playlist_name),
|
||||||
|
missing_thumbnails)
|
||||||
|
|
||||||
|
|
||||||
|
def read_playlist(name):
|
||||||
|
'''Returns a list of videos for the given playlist name'''
|
||||||
|
playlist_path = os.path.join(playlists_directory, name + '.txt')
|
||||||
|
with open(playlist_path, 'r', encoding='utf-8') as f:
|
||||||
|
data = f.read()
|
||||||
|
|
||||||
|
videos = []
|
||||||
|
videos_json = data.splitlines()
|
||||||
|
for video_json in videos_json:
|
||||||
|
try:
|
||||||
|
info = json.loads(video_json)
|
||||||
|
videos.append(info)
|
||||||
|
except json.decoder.JSONDecodeError:
|
||||||
|
if not video_json.strip() == '':
|
||||||
|
print('Corrupt playlist video entry: ' + video_json)
|
||||||
|
return videos
|
||||||
|
|
||||||
|
|
||||||
|
def get_local_playlist_videos(name, offset=0, amount=50):
|
||||||
|
videos = read_playlist(name)
|
||||||
|
add_extra_info_to_videos(videos, name)
|
||||||
|
return videos[offset:offset+amount], len(videos)
|
||||||
|
|
||||||
|
|
||||||
|
def get_playlist_names():
|
||||||
|
try:
|
||||||
|
items = os.listdir(playlists_directory)
|
||||||
|
except FileNotFoundError:
|
||||||
|
return
|
||||||
|
for item in items:
|
||||||
|
name, ext = os.path.splitext(item)
|
||||||
|
if ext == '.txt':
|
||||||
|
yield name
|
||||||
|
|
||||||
|
def remove_from_playlist(name, video_info_list):
|
||||||
|
ids = [json.loads(video)['id'] for video in video_info_list]
|
||||||
|
with open(os.path.join(playlists_directory, name + ".txt"), 'r', encoding='utf-8') as file:
|
||||||
|
videos = file.read()
|
||||||
|
videos_in = videos.splitlines()
|
||||||
|
videos_out = []
|
||||||
|
for video in videos_in:
|
||||||
|
if json.loads(video)['id'] not in ids:
|
||||||
|
videos_out.append(video)
|
||||||
|
with open(os.path.join(playlists_directory, name + ".txt"), 'w', encoding='utf-8') as file:
|
||||||
|
file.write("\n".join(videos_out) + "\n")
|
||||||
|
|
||||||
|
try:
|
||||||
|
thumbnails = set(os.listdir(os.path.join(thumbnails_directory, name)))
|
||||||
|
except FileNotFoundError:
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
to_delete = thumbnails & set(id + ".jpg" for id in ids)
|
||||||
|
for file in to_delete:
|
||||||
|
os.remove(os.path.join(thumbnails_directory, name, file))
|
||||||
|
|
||||||
|
return len(videos_out)
|
||||||
|
|
||||||
|
|
||||||
|
@yt_app.route('/playlists', methods=['GET'])
|
||||||
|
@yt_app.route('/playlists/<playlist_name>', methods=['GET'])
|
||||||
|
def get_local_playlist_page(playlist_name=None):
|
||||||
|
if playlist_name is None:
|
||||||
|
playlists = [(name, util.URL_ORIGIN + '/playlists/' + name) for name in get_playlist_names()]
|
||||||
|
return flask.render_template('local_playlists_list.html', playlists=playlists)
|
||||||
|
else:
|
||||||
|
page = int(request.args.get('page', 1))
|
||||||
|
offset = 50*(page - 1)
|
||||||
|
videos, num_videos = get_local_playlist_videos(playlist_name, offset=offset, amount=50)
|
||||||
|
return flask.render_template('local_playlist.html',
|
||||||
|
header_playlist_names = get_playlist_names(),
|
||||||
|
playlist_name = playlist_name,
|
||||||
|
videos = videos,
|
||||||
|
num_pages = math.ceil(num_videos/50),
|
||||||
|
parameters_dictionary = request.args,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@yt_app.route('/playlists/<playlist_name>', methods=['POST'])
|
||||||
|
def path_edit_playlist(playlist_name):
|
||||||
|
'''Called when making changes to the playlist from that playlist's page'''
|
||||||
|
if request.values['action'] == 'remove':
|
||||||
|
videos_to_remove = request.values.getlist('video_info_list')
|
||||||
|
number_of_videos_remaining = remove_from_playlist(playlist_name, videos_to_remove)
|
||||||
|
redirect_page_number = min(int(request.values.get('page', 1)), math.ceil(number_of_videos_remaining/50))
|
||||||
|
return flask.redirect(util.URL_ORIGIN + request.path + '?page=' + str(redirect_page_number))
|
||||||
|
elif request.values['action'] == 'remove_playlist':
|
||||||
|
try:
|
||||||
|
os.remove(os.path.join(playlists_directory, playlist_name + ".txt"))
|
||||||
|
except OSError:
|
||||||
|
pass
|
||||||
|
return flask.redirect(util.URL_ORIGIN + '/playlists')
|
||||||
|
elif request.values['action'] == 'export':
|
||||||
|
videos = read_playlist(playlist_name)
|
||||||
|
fmt = request.values['export_format']
|
||||||
|
if fmt in ('ids', 'urls'):
|
||||||
|
prefix = ''
|
||||||
|
if fmt == 'urls':
|
||||||
|
prefix = 'https://www.youtube.com/watch?v='
|
||||||
|
id_list = '\n'.join(prefix + v['id'] for v in videos)
|
||||||
|
id_list += '\n'
|
||||||
|
resp = flask.Response(id_list, mimetype='text/plain')
|
||||||
|
cd = 'attachment; filename="%s.txt"' % playlist_name
|
||||||
|
resp.headers['Content-Disposition'] = cd
|
||||||
|
return resp
|
||||||
|
elif fmt == 'json':
|
||||||
|
json_data = json.dumps({'videos': videos}, indent=2,
|
||||||
|
sort_keys=True)
|
||||||
|
resp = flask.Response(json_data, mimetype='text/json')
|
||||||
|
cd = 'attachment; filename="%s.json"' % playlist_name
|
||||||
|
resp.headers['Content-Disposition'] = cd
|
||||||
|
return resp
|
||||||
|
else:
|
||||||
|
flask.abort(400)
|
||||||
|
else:
|
||||||
|
flask.abort(400)
|
||||||
|
|
||||||
|
|
||||||
|
@yt_app.route('/edit_playlist', methods=['POST'])
|
||||||
|
def edit_playlist():
|
||||||
|
'''Called when adding videos to a playlist from elsewhere'''
|
||||||
|
if request.values['action'] == 'add':
|
||||||
|
add_to_playlist(request.values['playlist_name'], request.values.getlist('video_info_list'))
|
||||||
|
return '', 204
|
||||||
|
else:
|
||||||
|
flask.abort(400)
|
||||||
|
|
||||||
|
@yt_app.route('/data/playlist_thumbnails/<playlist_name>/<thumbnail>')
|
||||||
|
def serve_thumbnail(playlist_name, thumbnail):
|
||||||
|
# .. is necessary because flask always uses the application directory at ./youtube, not the working directory
|
||||||
|
return flask.send_from_directory(os.path.join('..', thumbnails_directory, playlist_name), thumbnail)
|
||||||
11
youtube/opensearch.xml
Normal file
11
youtube/opensearch.xml
Normal file
@@ -0,0 +1,11 @@
|
|||||||
|
<SearchPlugin xmlns="http://www.mozilla.org/2006/browser/search/">
|
||||||
|
<ShortName>Youtube local</ShortName>
|
||||||
|
<Description>no CIA shit in the background</Description>
|
||||||
|
<InputEncoding>UTF-8</InputEncoding>
|
||||||
|
<Image width="16" height="16">data:image/x-icon;base64,AAABAAEAEBAAAAEACAAlAgAAFgAAAIlQTkcNChoKAAAADUlIRFIAAAAQAAAAEAgGAAAAH/P/YQAAAexJREFUOI2lkzFPmlEUhp/73fshtCUCRtvQkJoKMrDQJvoHnBzUhc3EH0DUQf+As6tujo4M6mTiIDp0kGiMTRojTRNSW6o12iD4YYXv3g7Qr4O0ScM7npz7vOe+J0fk83lDF7K6eQygwkdHhI+P0bYNxmBXq5RmZui5vGQgn0f7fKi7O4oLC1gPD48BP9JpnpRKJFZXcQMB3m1u4vr9NHp76d/bo39/n4/z84ROThBa4/r91OJxMKb9BSn5mskAIOt1eq6uEFpjVyrEcjk+T0+TXlzkbTZLuFDAur9/nIFRipuREQCe7+zgBgK8mZvj/fIylVTKa/6UzXKbSnnuHkA0GnwbH/cA0a0takND3IyOEiwWAXBiMYTWjzLwtvB9bAyAwMUF8ZUVPiwtYTWbHqA6PIxoNv8OMLbN3eBga9TZWYQxaKX+AJJJhOv+AyAlT0slAG6TSX5n8+zszJugkzxA4PzcK9YSCQCk42DXaq1aGwqgfT5ebG9jpMQyUjKwu8vrtbWWqxC83NjAd31NsO2uleJnX58HCJ6eEjk8BGNQAA+RCOXJScpTU2AMwnUxlkXk4ACA+2iUSKGArNeRjkMsl6M8MYHQGtHpmIxSvFpfRzoORinQGqvZBCEwQoAxfMlkaIRCnQH/o66v8Re19MavaDNLfgAAAABJRU5ErkJggg==</Image>
|
||||||
|
|
||||||
|
<Url type="text/html" method="GET" template="$host_url/youtube.com/results">
|
||||||
|
<Param name="search_query" value="{searchTerms}"/>
|
||||||
|
</Url>
|
||||||
|
<SearchForm>$host_url/youtube.com/results</SearchForm>
|
||||||
|
</SearchPlugin>
|
||||||
127
youtube/playlist.py
Normal file
127
youtube/playlist.py
Normal file
@@ -0,0 +1,127 @@
|
|||||||
|
from youtube import util, yt_data_extract, proto, local_playlist
|
||||||
|
from youtube import yt_app
|
||||||
|
import settings
|
||||||
|
|
||||||
|
import base64
|
||||||
|
import urllib
|
||||||
|
import json
|
||||||
|
import string
|
||||||
|
import gevent
|
||||||
|
import math
|
||||||
|
from flask import request
|
||||||
|
import flask
|
||||||
|
|
||||||
|
|
||||||
|
def playlist_ctoken(playlist_id, offset, include_shorts=True):
|
||||||
|
|
||||||
|
offset = proto.uint(1, offset)
|
||||||
|
offset = b'PT:' + proto.unpadded_b64encode(offset)
|
||||||
|
offset = proto.string(15, offset)
|
||||||
|
if not include_shorts:
|
||||||
|
offset += proto.string(104, proto.uint(2, 1))
|
||||||
|
|
||||||
|
continuation_info = proto.string( 3, proto.percent_b64encode(offset) )
|
||||||
|
|
||||||
|
playlist_id = proto.string(2, 'VL' + playlist_id )
|
||||||
|
pointless_nest = proto.string(80226972, playlist_id + continuation_info)
|
||||||
|
|
||||||
|
return base64.urlsafe_b64encode(pointless_nest).decode('ascii')
|
||||||
|
|
||||||
|
|
||||||
|
def playlist_first_page(playlist_id, report_text="Retrieved playlist",
|
||||||
|
use_mobile=False):
|
||||||
|
if use_mobile:
|
||||||
|
url = 'https://m.youtube.com/playlist?list=' + playlist_id + '&pbj=1'
|
||||||
|
content = util.fetch_url(
|
||||||
|
url, util.mobile_xhr_headers,
|
||||||
|
report_text=report_text, debug_name='playlist_first_page'
|
||||||
|
)
|
||||||
|
content = json.loads(content.decode('utf-8'))
|
||||||
|
else:
|
||||||
|
url = 'https://www.youtube.com/playlist?list=' + playlist_id + '&pbj=1'
|
||||||
|
content = util.fetch_url(
|
||||||
|
url, util.desktop_xhr_headers,
|
||||||
|
report_text=report_text, debug_name='playlist_first_page'
|
||||||
|
)
|
||||||
|
content = json.loads(content.decode('utf-8'))
|
||||||
|
|
||||||
|
return content
|
||||||
|
|
||||||
|
|
||||||
|
def get_videos(playlist_id, page, include_shorts=True, use_mobile=False,
|
||||||
|
report_text='Retrieved playlist'):
|
||||||
|
# mobile requests return 20 videos per page
|
||||||
|
if use_mobile:
|
||||||
|
page_size = 20
|
||||||
|
headers = util.mobile_xhr_headers
|
||||||
|
# desktop requests return 100 videos per page
|
||||||
|
else:
|
||||||
|
page_size = 100
|
||||||
|
headers = util.desktop_xhr_headers
|
||||||
|
|
||||||
|
url = "https://m.youtube.com/playlist?ctoken="
|
||||||
|
url += playlist_ctoken(playlist_id, (int(page)-1)*page_size,
|
||||||
|
include_shorts=include_shorts)
|
||||||
|
url += "&pbj=1"
|
||||||
|
content = util.fetch_url(
|
||||||
|
url, headers, report_text=report_text,
|
||||||
|
debug_name='playlist_videos'
|
||||||
|
)
|
||||||
|
|
||||||
|
info = json.loads(content.decode('utf-8'))
|
||||||
|
return info
|
||||||
|
|
||||||
|
|
||||||
|
@yt_app.route('/playlist')
|
||||||
|
def get_playlist_page():
|
||||||
|
if 'list' not in request.args:
|
||||||
|
abort(400)
|
||||||
|
|
||||||
|
playlist_id = request.args.get('list')
|
||||||
|
page = request.args.get('page', '1')
|
||||||
|
|
||||||
|
if page == '1':
|
||||||
|
first_page_json = playlist_first_page(playlist_id)
|
||||||
|
this_page_json = first_page_json
|
||||||
|
else:
|
||||||
|
tasks = (
|
||||||
|
gevent.spawn(
|
||||||
|
playlist_first_page, playlist_id,
|
||||||
|
report_text="Retrieved playlist info", use_mobile=True
|
||||||
|
),
|
||||||
|
gevent.spawn(get_videos, playlist_id, page)
|
||||||
|
)
|
||||||
|
gevent.joinall(tasks)
|
||||||
|
util.check_gevent_exceptions(*tasks)
|
||||||
|
first_page_json, this_page_json = tasks[0].value, tasks[1].value
|
||||||
|
|
||||||
|
info = yt_data_extract.extract_playlist_info(this_page_json)
|
||||||
|
if info['error']:
|
||||||
|
return flask.render_template('error.html', error_message = info['error'])
|
||||||
|
|
||||||
|
if page != '1':
|
||||||
|
info['metadata'] = yt_data_extract.extract_playlist_metadata(first_page_json)
|
||||||
|
|
||||||
|
util.prefix_urls(info['metadata'])
|
||||||
|
for item in info.get('items', ()):
|
||||||
|
util.prefix_urls(item)
|
||||||
|
util.add_extra_html_info(item)
|
||||||
|
if 'id' in item:
|
||||||
|
item['thumbnail'] = settings.img_prefix + 'https://i.ytimg.com/vi/' + item['id'] + '/default.jpg'
|
||||||
|
|
||||||
|
item['url'] += '&list=' + playlist_id
|
||||||
|
if item['index']:
|
||||||
|
item['url'] += '&index=' + str(item['index'])
|
||||||
|
|
||||||
|
video_count = yt_data_extract.deep_get(info, 'metadata', 'video_count')
|
||||||
|
if video_count is None:
|
||||||
|
video_count = 1000
|
||||||
|
|
||||||
|
return flask.render_template('playlist.html',
|
||||||
|
header_playlist_names = local_playlist.get_playlist_names(),
|
||||||
|
video_list = info.get('items', []),
|
||||||
|
num_pages = math.ceil(video_count/100),
|
||||||
|
parameters_dictionary = request.args,
|
||||||
|
|
||||||
|
**info['metadata']
|
||||||
|
).encode('utf-8')
|
||||||
217
youtube/proto.py
Normal file
217
youtube/proto.py
Normal file
@@ -0,0 +1,217 @@
|
|||||||
|
from math import ceil
|
||||||
|
import base64
|
||||||
|
import io
|
||||||
|
import traceback
|
||||||
|
|
||||||
|
def byte(n):
|
||||||
|
return bytes((n,))
|
||||||
|
|
||||||
|
|
||||||
|
def varint_encode(offset):
|
||||||
|
'''In this encoding system, for each 8-bit byte, the first bit is 1 if there are more bytes, and 0 is this is the last one.
|
||||||
|
The next 7 bits are data. These 7-bit sections represent the data in Little endian order. For example, suppose the data is
|
||||||
|
aaaaaaabbbbbbbccccccc (each of these sections is 7 bits). It will be encoded as:
|
||||||
|
1ccccccc 1bbbbbbb 0aaaaaaa
|
||||||
|
|
||||||
|
This encoding is used in youtube parameters to encode offsets and to encode the length for length-prefixed data.
|
||||||
|
See https://developers.google.com/protocol-buffers/docs/encoding#varints for more info.'''
|
||||||
|
needed_bytes = ceil(offset.bit_length()/7) or 1 # (0).bit_length() returns 0, but we need 1 in that case.
|
||||||
|
encoded_bytes = bytearray(needed_bytes)
|
||||||
|
for i in range(0, needed_bytes - 1):
|
||||||
|
encoded_bytes[i] = (offset & 127) | 128 # 7 least significant bits
|
||||||
|
offset = offset >> 7
|
||||||
|
encoded_bytes[-1] = offset & 127 # leave first bit as zero for last byte
|
||||||
|
|
||||||
|
return bytes(encoded_bytes)
|
||||||
|
|
||||||
|
|
||||||
|
def varint_decode(encoded):
|
||||||
|
decoded = 0
|
||||||
|
for i, byte in enumerate(encoded):
|
||||||
|
decoded |= (byte & 127) << 7*i
|
||||||
|
|
||||||
|
if not (byte & 128):
|
||||||
|
break
|
||||||
|
return decoded
|
||||||
|
|
||||||
|
|
||||||
|
def string(field_number, data):
|
||||||
|
data = as_bytes(data)
|
||||||
|
return _proto_field(2, field_number, varint_encode(len(data)) + data)
|
||||||
|
nested = string
|
||||||
|
|
||||||
|
def uint(field_number, value):
|
||||||
|
return _proto_field(0, field_number, varint_encode(value))
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def _proto_field(wire_type, field_number, data):
|
||||||
|
''' See https://developers.google.com/protocol-buffers/docs/encoding#structure '''
|
||||||
|
return varint_encode( (field_number << 3) | wire_type) + data
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def percent_b64encode(data):
|
||||||
|
return base64.urlsafe_b64encode(data).replace(b'=', b'%3D')
|
||||||
|
|
||||||
|
|
||||||
|
def unpadded_b64encode(data):
|
||||||
|
return base64.urlsafe_b64encode(data).replace(b'=', b'')
|
||||||
|
|
||||||
|
def as_bytes(value):
|
||||||
|
if isinstance(value, str):
|
||||||
|
return value.encode('utf-8')
|
||||||
|
return value
|
||||||
|
|
||||||
|
|
||||||
|
def read_varint(data):
|
||||||
|
result = 0
|
||||||
|
i = 0
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
byte = data.read(1)[0]
|
||||||
|
except IndexError:
|
||||||
|
if i == 0:
|
||||||
|
raise EOFError()
|
||||||
|
raise Exception('Unterminated varint starting at ' + str(data.tell() - i))
|
||||||
|
result |= (byte & 127) << 7*i
|
||||||
|
if not byte & 128:
|
||||||
|
break
|
||||||
|
|
||||||
|
i += 1
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
def read_group(data, end_sequence):
|
||||||
|
start = data.tell()
|
||||||
|
index = data.original.find(end_sequence, start)
|
||||||
|
if index == -1:
|
||||||
|
raise Exception('Unterminated group')
|
||||||
|
data.seek(index + len(end_sequence))
|
||||||
|
return data.original[start:index]
|
||||||
|
|
||||||
|
def read_protobuf(data):
|
||||||
|
data_original = data
|
||||||
|
data = io.BytesIO(data)
|
||||||
|
data.original = data_original
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
tag = read_varint(data)
|
||||||
|
except EOFError:
|
||||||
|
break
|
||||||
|
wire_type = tag & 7
|
||||||
|
field_number = tag >> 3
|
||||||
|
|
||||||
|
if wire_type == 0:
|
||||||
|
value = read_varint(data)
|
||||||
|
elif wire_type == 1:
|
||||||
|
value = data.read(8)
|
||||||
|
elif wire_type == 2:
|
||||||
|
length = read_varint(data)
|
||||||
|
value = data.read(length)
|
||||||
|
elif wire_type == 3:
|
||||||
|
end_bytes = encode_varint((field_number << 3) | 4)
|
||||||
|
value = read_group(data, end_bytes)
|
||||||
|
elif wire_type == 5:
|
||||||
|
value = data.read(4)
|
||||||
|
else:
|
||||||
|
raise Exception("Unknown wire type: " + str(wire_type) + ", Tag: " + bytes_to_hex(succinct_encode(tag)) + ", at position " + str(data.tell()))
|
||||||
|
yield (wire_type, field_number, value)
|
||||||
|
|
||||||
|
def parse(data, include_wire_type=False):
|
||||||
|
'''Returns a dict mapping field numbers to values
|
||||||
|
|
||||||
|
data is the protobuf structure, which must not be b64-encoded'''
|
||||||
|
if include_wire_type:
|
||||||
|
return {field_number: [wire_type, value]
|
||||||
|
for wire_type, field_number, value in read_protobuf(data)}
|
||||||
|
return {field_number: value
|
||||||
|
for _, field_number, value in read_protobuf(data)}
|
||||||
|
|
||||||
|
|
||||||
|
base64_enc_funcs = {
|
||||||
|
'base64': base64.urlsafe_b64encode,
|
||||||
|
'base64s': unpadded_b64encode,
|
||||||
|
'base64p': percent_b64encode,
|
||||||
|
}
|
||||||
|
def _make_protobuf(data):
|
||||||
|
'''
|
||||||
|
Input: Recursive list of protobuf objects or base-64 encodings
|
||||||
|
Output: Protobuf bytestring
|
||||||
|
Each protobuf object takes the form [wire_type, field_number, field_data]
|
||||||
|
If a string protobuf has a list/tuple of length 2, this has the form
|
||||||
|
(base64 type, data)
|
||||||
|
The base64 types are
|
||||||
|
- base64 means a base64 encode with equals sign paddings
|
||||||
|
- base64s means a base64 encode without padding
|
||||||
|
- base64p means a url base64 encode with equals signs replaced with %3D
|
||||||
|
'''
|
||||||
|
# must be dict mapping field_number to [wire_type, value]
|
||||||
|
if isinstance(data, dict):
|
||||||
|
new_data = []
|
||||||
|
for field_num, (wire_type, value) in sorted(data.items()):
|
||||||
|
new_data.append((wire_type, field_num, value))
|
||||||
|
data = new_data
|
||||||
|
if isinstance(data, str):
|
||||||
|
return data.encode('utf-8')
|
||||||
|
elif len(data) == 2 and data[0] in list(base64_enc_funcs.keys()):
|
||||||
|
return base64_enc_funcs[data[0]](_make_protobuf(data[1]))
|
||||||
|
elif isinstance(data, list):
|
||||||
|
result = b''
|
||||||
|
for field in data:
|
||||||
|
if field[0] == 0:
|
||||||
|
result += uint(field[1], field[2])
|
||||||
|
elif field[0] == 2:
|
||||||
|
result += string(field[1], _make_protobuf(field[2]))
|
||||||
|
else:
|
||||||
|
raise NotImplementedError('Wire type ' + str(field[0])
|
||||||
|
+ ' not implemented')
|
||||||
|
return result
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
def make_protobuf(data):
|
||||||
|
return _make_protobuf(data).decode('ascii')
|
||||||
|
|
||||||
|
|
||||||
|
def _set_protobuf_value(data, *path, value):
|
||||||
|
if not path:
|
||||||
|
return value
|
||||||
|
op = path[0]
|
||||||
|
if op in base64_enc_funcs:
|
||||||
|
inner_data = b64_to_bytes(data)
|
||||||
|
return base64_enc_funcs[op](
|
||||||
|
_set_protobuf_value(inner_data, *path[1:], value=value)
|
||||||
|
)
|
||||||
|
pb_dict = parse(data, include_wire_type=True)
|
||||||
|
pb_dict[op][1] = _set_protobuf_value(
|
||||||
|
pb_dict[op][1], *path[1:], value=value
|
||||||
|
)
|
||||||
|
return _make_protobuf(pb_dict)
|
||||||
|
|
||||||
|
|
||||||
|
def set_protobuf_value(data, *path, value):
|
||||||
|
'''Set a field's value in a raw protobuf structure
|
||||||
|
|
||||||
|
path is a list of field numbers and/or base64 encoding directives
|
||||||
|
|
||||||
|
The directives are
|
||||||
|
base64: normal base64 encoding with equal signs padding
|
||||||
|
base64s ("stripped"): no padding
|
||||||
|
base64p: %3D instead of = for padding
|
||||||
|
|
||||||
|
return new_protobuf, err'''
|
||||||
|
try:
|
||||||
|
new_protobuf = _set_protobuf_value(data, *path, value=value)
|
||||||
|
return new_protobuf.decode('ascii'), None
|
||||||
|
except Exception:
|
||||||
|
return None, traceback.format_exc()
|
||||||
|
|
||||||
|
|
||||||
|
def b64_to_bytes(data):
|
||||||
|
if isinstance(data, bytes):
|
||||||
|
data = data.decode('ascii')
|
||||||
|
data = data.replace("%3D", "=")
|
||||||
|
return base64.urlsafe_b64decode(data + "="*((4 - len(data)%4)%4) )
|
||||||
|
|
||||||
590
youtube/proto_debug.py
Normal file
590
youtube/proto_debug.py
Normal file
@@ -0,0 +1,590 @@
|
|||||||
|
# TODO: clean this file up more and heavily refactor
|
||||||
|
|
||||||
|
''' Helper functions for reverse engineering protobuf.
|
||||||
|
|
||||||
|
Basic guide:
|
||||||
|
|
||||||
|
Run interactively with python3 -i proto_debug.py
|
||||||
|
|
||||||
|
The function dec will decode a base64 string
|
||||||
|
(regardless of whether it includes = or %3D at the end) to a bytestring
|
||||||
|
|
||||||
|
The function pb (parse_protobuf) will return a list of tuples.
|
||||||
|
Each tuple is (wire_type, field_number, field_data)
|
||||||
|
|
||||||
|
The function enc encodes as base64 (inverse of dec)
|
||||||
|
The function uenc is like enc but replaces = with %3D
|
||||||
|
|
||||||
|
See https://developers.google.com/protocol-buffers/docs/encoding#structure
|
||||||
|
|
||||||
|
Example usage:
|
||||||
|
>>> pb(dec('4qmFsgJcEhhVQ1lPX2phYl9lc3VGUlY0YjE3QUp0QXcaQEVnWjJhV1JsYjNNWUF5QUFNQUU0QWVvREdFTm5Ua1JSVlVWVFEzZHBYM2gwTTBaeFRuRkZiRFZqUWclM0QlM0Q%3D'))
|
||||||
|
[(2, 80226972, b'\x12\x18UCYO_jab_esuFRV4b17AJtAw\x1a@EgZ2aWRlb3MYAyAAMAE4AeoDGENnTkRRVUVTQ3dpX3h0M0ZxTnFFbDVjQg%3D%3D')]
|
||||||
|
|
||||||
|
>>> pb(b'\x12\x18UCYO_jab_esuFRV4b17AJtAw\x1a@EgZ2aWRlb3MYAyAAMAE4AeoDGENnTkRRVUVTQ3dpX3h0M0ZxTnFFbDVjQg%3D%3D')
|
||||||
|
[(2, 2, b'UCYO_jab_esuFRV4b17AJtAw'), (2, 3, b'EgZ2aWRlb3MYAyAAMAE4AeoDGENnTkRRVUVTQ3dpX3h0M0ZxTnFFbDVjQg%3D%3D')]
|
||||||
|
|
||||||
|
>>> pb(dec(b'EgZ2aWRlb3MYAyAAMAE4AeoDGENnTkRRVUVTQ3dpX3h0M0ZxTnFFbDVjQg%3D%3D'))
|
||||||
|
[(2, 2, b'videos'), (0, 3, 3), (0, 4, 0), (0, 6, 1), (0, 7, 1), (2, 61, b'CgNDQUESCwi_xt3FqNqEl5cB')]
|
||||||
|
|
||||||
|
>>> pb(dec(b'CgNDQUESCwi_xt3FqNqEl5cB'))
|
||||||
|
[(2, 1, b'CAA'), (2, 2, b'\x08\xbf\xc6\xdd\xc5\xa8\xda\x84\x97\x97\x01')]
|
||||||
|
|
||||||
|
>>> pb(b'\x08\xbf\xc6\xdd\xc5\xa8\xda\x84\x97\x97\x01')
|
||||||
|
[(0, 1, 10893665244101960511)]
|
||||||
|
|
||||||
|
>>> pb(dec(b'CAA'))
|
||||||
|
[(0, 1, 0)]
|
||||||
|
|
||||||
|
The function recursive_pb will try to do dec/pb recursively automatically.
|
||||||
|
It's a dumb function (so might try to dec or pb something that isn't really
|
||||||
|
base64 or protobuf) so be careful.
|
||||||
|
The function pp will pretty print the recursive structure:
|
||||||
|
|
||||||
|
>>> pp(recursive_pb('4qmFsgJcEhhVQ1lPX2phYl9lc3VGUlY0YjE3QUp0QXcaQEVnWjJhV1JsYjNNWUF5QUFNQUU0QWVvREdFTm5Ua1JSVlVWVFEzZHBYM2gwTTBaeFRuRkZiRFZqUWclM0QlM0Q%3D'))
|
||||||
|
|
||||||
|
('base64p',
|
||||||
|
[
|
||||||
|
[2, 80226972,
|
||||||
|
[
|
||||||
|
[2, 2, b'UCYO_jab_esuFRV4b17AJtAw'],
|
||||||
|
[2, 3,
|
||||||
|
('base64p',
|
||||||
|
[
|
||||||
|
[2, 2, b'videos'],
|
||||||
|
[0, 3, 3],
|
||||||
|
[0, 4, 0],
|
||||||
|
[0, 6, 1],
|
||||||
|
[0, 7, 1],
|
||||||
|
[2, 61,
|
||||||
|
('base64?',
|
||||||
|
[
|
||||||
|
[2, 1, b'CAA'],
|
||||||
|
[2, 2,
|
||||||
|
[
|
||||||
|
[0, 1, 10893665244101960511],
|
||||||
|
]
|
||||||
|
],
|
||||||
|
]
|
||||||
|
)
|
||||||
|
],
|
||||||
|
]
|
||||||
|
)
|
||||||
|
],
|
||||||
|
]
|
||||||
|
],
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
- base64 means a base64 encode with equals sign paddings
|
||||||
|
- base64s means a base64 encode without padding
|
||||||
|
- base64p means a url base64 encode with equals signs replaced with %3D
|
||||||
|
- base64? means the base64 type cannot be inferred because of the length
|
||||||
|
|
||||||
|
make_proto is the inverse function. It will take a recursive_pb structure and
|
||||||
|
make a ctoken out of it, so in general,
|
||||||
|
x == make_proto(recursive_pb(x))
|
||||||
|
|
||||||
|
There are some other functions I wrote while reverse engineering stuff
|
||||||
|
that may or may not be useful.
|
||||||
|
'''
|
||||||
|
|
||||||
|
|
||||||
|
import urllib.request
|
||||||
|
import urllib.parse
|
||||||
|
import re
|
||||||
|
import time
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import pprint
|
||||||
|
|
||||||
|
|
||||||
|
# ------ from proto.py -----------------------------------------------
|
||||||
|
from math import ceil
|
||||||
|
import base64
|
||||||
|
import io
|
||||||
|
|
||||||
|
def byte(n):
|
||||||
|
return bytes((n,))
|
||||||
|
|
||||||
|
|
||||||
|
def varint_encode(offset):
|
||||||
|
'''In this encoding system, for each 8-bit byte, the first bit is 1 if there are more bytes, and 0 is this is the last one.
|
||||||
|
The next 7 bits are data. These 7-bit sections represent the data in Little endian order. For example, suppose the data is
|
||||||
|
aaaaaaabbbbbbbccccccc (each of these sections is 7 bits). It will be encoded as:
|
||||||
|
1ccccccc 1bbbbbbb 0aaaaaaa
|
||||||
|
|
||||||
|
This encoding is used in youtube parameters to encode offsets and to encode the length for length-prefixed data.
|
||||||
|
See https://developers.google.com/protocol-buffers/docs/encoding#varints for more info.'''
|
||||||
|
needed_bytes = ceil(offset.bit_length()/7) or 1 # (0).bit_length() returns 0, but we need 1 in that case.
|
||||||
|
encoded_bytes = bytearray(needed_bytes)
|
||||||
|
for i in range(0, needed_bytes - 1):
|
||||||
|
encoded_bytes[i] = (offset & 127) | 128 # 7 least significant bits
|
||||||
|
offset = offset >> 7
|
||||||
|
encoded_bytes[-1] = offset & 127 # leave first bit as zero for last byte
|
||||||
|
|
||||||
|
return bytes(encoded_bytes)
|
||||||
|
|
||||||
|
|
||||||
|
def varint_decode(encoded):
|
||||||
|
decoded = 0
|
||||||
|
for i, byte in enumerate(encoded):
|
||||||
|
decoded |= (byte & 127) << 7*i
|
||||||
|
|
||||||
|
if not (byte & 128):
|
||||||
|
break
|
||||||
|
return decoded
|
||||||
|
|
||||||
|
|
||||||
|
def string(field_number, data):
|
||||||
|
data = as_bytes(data)
|
||||||
|
return _proto_field(2, field_number, varint_encode(len(data)) + data)
|
||||||
|
nested = string
|
||||||
|
|
||||||
|
def uint(field_number, value):
|
||||||
|
return _proto_field(0, field_number, varint_encode(value))
|
||||||
|
|
||||||
|
|
||||||
|
def _proto_field(wire_type, field_number, data):
|
||||||
|
''' See https://developers.google.com/protocol-buffers/docs/encoding#structure '''
|
||||||
|
return varint_encode( (field_number << 3) | wire_type) + data
|
||||||
|
|
||||||
|
|
||||||
|
def percent_b64encode(data):
|
||||||
|
return base64.urlsafe_b64encode(data).replace(b'=', b'%3D')
|
||||||
|
|
||||||
|
|
||||||
|
def unpadded_b64encode(data):
|
||||||
|
return base64.urlsafe_b64encode(data).replace(b'=', b'')
|
||||||
|
|
||||||
|
|
||||||
|
def as_bytes(value):
|
||||||
|
if isinstance(value, str):
|
||||||
|
return value.encode('utf-8')
|
||||||
|
return value
|
||||||
|
|
||||||
|
|
||||||
|
def read_varint(data):
|
||||||
|
result = 0
|
||||||
|
i = 0
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
byte = data.read(1)[0]
|
||||||
|
except IndexError:
|
||||||
|
if i == 0:
|
||||||
|
raise EOFError()
|
||||||
|
raise Exception('Unterminated varint starting at ' + str(data.tell() - i))
|
||||||
|
result |= (byte & 127) << 7*i
|
||||||
|
if not byte & 128:
|
||||||
|
break
|
||||||
|
|
||||||
|
i += 1
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
def read_group(data, end_sequence):
|
||||||
|
start = data.tell()
|
||||||
|
index = data.original.find(end_sequence, start)
|
||||||
|
if index == -1:
|
||||||
|
raise Exception('Unterminated group')
|
||||||
|
data.seek(index + len(end_sequence))
|
||||||
|
return data.original[start:index]
|
||||||
|
|
||||||
|
|
||||||
|
def parse(data, include_wire_type=False):
|
||||||
|
'''Returns a dict mapping field numbers to values
|
||||||
|
|
||||||
|
data is the protobuf structure, which must not be b64-encoded'''
|
||||||
|
if include_wire_type:
|
||||||
|
return {field_number: [wire_type, value]
|
||||||
|
for wire_type, field_number, value in read_protobuf(data)}
|
||||||
|
return {field_number: value
|
||||||
|
for _, field_number, value in read_protobuf(data)}
|
||||||
|
|
||||||
|
|
||||||
|
base64_enc_funcs = {
|
||||||
|
'base64': base64.urlsafe_b64encode,
|
||||||
|
'base64s': unpadded_b64encode,
|
||||||
|
'base64p': percent_b64encode,
|
||||||
|
'base64?': base64.urlsafe_b64encode,
|
||||||
|
}
|
||||||
|
def _make_protobuf(data):
|
||||||
|
# must be dict mapping field_number to [wire_type, value]
|
||||||
|
if isinstance(data, dict):
|
||||||
|
new_data = []
|
||||||
|
for field_num, (wire_type, value) in sorted(data.items()):
|
||||||
|
new_data.append((wire_type, field_num, value))
|
||||||
|
data = new_data
|
||||||
|
if isinstance(data, str):
|
||||||
|
return data.encode('utf-8')
|
||||||
|
elif len(data) == 2 and data[0] in list(base64_enc_funcs.keys()):
|
||||||
|
return base64_enc_funcs[data[0]](_make_protobuf(data[1]))
|
||||||
|
elif isinstance(data, list):
|
||||||
|
result = b''
|
||||||
|
for field in data:
|
||||||
|
if field[0] == 0:
|
||||||
|
result += uint(field[1], field[2])
|
||||||
|
elif field[0] == 2:
|
||||||
|
result += string(field[1], _make_protobuf(field[2]))
|
||||||
|
else:
|
||||||
|
raise NotImplementedError('Wire type ' + str(field[0])
|
||||||
|
+ ' not implemented')
|
||||||
|
return result
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
def make_protobuf(data):
|
||||||
|
return _make_protobuf(data).decode('ascii')
|
||||||
|
make_proto = make_protobuf
|
||||||
|
|
||||||
|
|
||||||
|
def _set_protobuf_value(data, *path, value):
|
||||||
|
if not path:
|
||||||
|
return value
|
||||||
|
op = path[0]
|
||||||
|
if op in base64_enc_funcs:
|
||||||
|
inner_data = b64_to_bytes(data)
|
||||||
|
return base64_enc_funcs[op](
|
||||||
|
_set_protobuf_value(inner_data, *path[1:], value=value)
|
||||||
|
)
|
||||||
|
pb_dict = parse(data, include_wire_type=True)
|
||||||
|
pb_dict[op][1] = _set_protobuf_value(
|
||||||
|
pb_dict[op][1], *path[1:], value=value
|
||||||
|
)
|
||||||
|
return _make_protobuf(pb_dict)
|
||||||
|
|
||||||
|
|
||||||
|
def set_protobuf_value(data, *path, value):
|
||||||
|
'''Set a field's value in a raw protobuf structure
|
||||||
|
|
||||||
|
path is a list of field numbers and/or base64 encoding directives
|
||||||
|
|
||||||
|
The directives are
|
||||||
|
base64: normal base64 encoding with equal signs padding
|
||||||
|
base64s ("stripped"): no padding
|
||||||
|
base64p: %3D instead of = for padding
|
||||||
|
|
||||||
|
return new_protobuf, err'''
|
||||||
|
try:
|
||||||
|
new_protobuf = _set_protobuf_value(data, *path, value=value)
|
||||||
|
return new_protobuf.decode('ascii'), None
|
||||||
|
except Exception:
|
||||||
|
return None, traceback.format_exc()
|
||||||
|
|
||||||
|
|
||||||
|
def b64_to_bytes(data):
|
||||||
|
if isinstance(data, bytes):
|
||||||
|
data = data.decode('ascii')
|
||||||
|
data = data.replace("%3D", "=")
|
||||||
|
return base64.urlsafe_b64decode(data + "="*((4 - len(data)%4)%4) )
|
||||||
|
# --------------------------------------------------------------------
|
||||||
|
|
||||||
|
|
||||||
|
dec = b64_to_bytes
|
||||||
|
|
||||||
|
|
||||||
|
def get_b64_type(data):
|
||||||
|
'''return base64, base64s, base64p, or base64?'''
|
||||||
|
if isinstance(data, str):
|
||||||
|
data = data.encode('ascii')
|
||||||
|
if data.endswith(b'='):
|
||||||
|
return 'base64'
|
||||||
|
if data.endswith(b'%3D'):
|
||||||
|
return 'base64p'
|
||||||
|
# Length of data means it wouldn't have an equals sign,
|
||||||
|
# so we can't tell which type it is.
|
||||||
|
if len(data) % 4 == 0:
|
||||||
|
return 'base64?'
|
||||||
|
|
||||||
|
return 'base64s'
|
||||||
|
|
||||||
|
|
||||||
|
def enc(t):
|
||||||
|
return base64.urlsafe_b64encode(t).decode('ascii')
|
||||||
|
|
||||||
|
def uenc(t):
|
||||||
|
return enc(t).replace("=", "%3D")
|
||||||
|
|
||||||
|
def b64_to_ascii(t):
|
||||||
|
return base64.urlsafe_b64decode(t).decode('ascii', errors='replace')
|
||||||
|
|
||||||
|
def b64_to_bin(t):
|
||||||
|
decoded = base64.urlsafe_b64decode(t)
|
||||||
|
#print(len(decoded)*8)
|
||||||
|
return " ".join(["{:08b}".format(x) for x in decoded])
|
||||||
|
|
||||||
|
def bytes_to_bin(t):
|
||||||
|
return " ".join(["{:08b}".format(x) for x in t])
|
||||||
|
def bin_to_bytes(t):
|
||||||
|
return int(t, 2).to_bytes((len(t) + 7) // 8, 'big')
|
||||||
|
|
||||||
|
def bytes_to_hex(t):
|
||||||
|
return ' '.join(hex(n)[2:].zfill(2) for n in t)
|
||||||
|
tohex = bytes_to_hex
|
||||||
|
fromhex = bytes.fromhex
|
||||||
|
|
||||||
|
|
||||||
|
def aligned_ascii(data):
|
||||||
|
return ' '.join(' ' + chr(n) if n in range(32,128) else ' _' for n in data)
|
||||||
|
|
||||||
|
def parse_protobuf(data, mutable=False, spec=()):
|
||||||
|
data_original = data
|
||||||
|
data = io.BytesIO(data)
|
||||||
|
data.original = data_original
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
tag = read_varint(data)
|
||||||
|
except EOFError:
|
||||||
|
break
|
||||||
|
wire_type = tag & 7
|
||||||
|
field_number = tag >> 3
|
||||||
|
|
||||||
|
if wire_type == 0:
|
||||||
|
value = read_varint(data)
|
||||||
|
elif wire_type == 1:
|
||||||
|
value = data.read(8)
|
||||||
|
elif wire_type == 2:
|
||||||
|
length = read_varint(data)
|
||||||
|
value = data.read(length)
|
||||||
|
elif wire_type == 3:
|
||||||
|
end_bytes = varint_encode((field_number << 3) | 4)
|
||||||
|
value = read_group(data, end_bytes)
|
||||||
|
elif wire_type == 5:
|
||||||
|
value = data.read(4)
|
||||||
|
else:
|
||||||
|
raise Exception("Unknown wire type: " + str(wire_type) + ", Tag: " + bytes_to_hex(varint_encode(tag)) + ", at position " + str(data.tell()))
|
||||||
|
if mutable:
|
||||||
|
yield [wire_type, field_number, value]
|
||||||
|
else:
|
||||||
|
yield (wire_type, field_number, value)
|
||||||
|
read_protobuf = parse_protobuf
|
||||||
|
|
||||||
|
|
||||||
|
def pb(data, mutable=False):
|
||||||
|
return list(parse_protobuf(data, mutable=mutable))
|
||||||
|
|
||||||
|
|
||||||
|
def bytes_to_base4(data):
|
||||||
|
result = ''
|
||||||
|
for b in data:
|
||||||
|
result += str(b >> 6) + str((b >> 4) & 0b11) + str((b >> 2) & 0b11) + str(b & 0b11)
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
import re
|
||||||
|
import struct
|
||||||
|
import binascii
|
||||||
|
|
||||||
|
|
||||||
|
# Base32 encoding/decoding must be done in Python
|
||||||
|
_b32alphabet = b'abcdefghijklmnopqrstuvwxyz012345'
|
||||||
|
_b32tab2 = None
|
||||||
|
_b32rev = None
|
||||||
|
|
||||||
|
bytes_types = (bytes, bytearray) # Types acceptable as binary data
|
||||||
|
|
||||||
|
def _bytes_from_decode_data(s):
|
||||||
|
if isinstance(s, str):
|
||||||
|
try:
|
||||||
|
return s.encode('ascii')
|
||||||
|
except UnicodeEncodeError:
|
||||||
|
raise ValueError('string argument should contain only ASCII characters')
|
||||||
|
if isinstance(s, bytes_types):
|
||||||
|
return s
|
||||||
|
try:
|
||||||
|
return memoryview(s).tobytes()
|
||||||
|
except TypeError:
|
||||||
|
raise TypeError("argument should be a bytes-like object or ASCII "
|
||||||
|
"string, not %r" % s.__class__.__name__) from None
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def b32decode(s, casefold=False, map01=None):
|
||||||
|
"""Decode the Base32 encoded bytes-like object or ASCII string s.
|
||||||
|
|
||||||
|
Optional casefold is a flag specifying whether a lowercase alphabet is
|
||||||
|
acceptable as input. For security purposes, the default is False.
|
||||||
|
|
||||||
|
RFC 3548 allows for optional mapping of the digit 0 (zero) to the
|
||||||
|
letter O (oh), and for optional mapping of the digit 1 (one) to
|
||||||
|
either the letter I (eye) or letter L (el). The optional argument
|
||||||
|
map01 when not None, specifies which letter the digit 1 should be
|
||||||
|
mapped to (when map01 is not None, the digit 0 is always mapped to
|
||||||
|
the letter O). For security purposes the default is None, so that
|
||||||
|
0 and 1 are not allowed in the input.
|
||||||
|
|
||||||
|
The result is returned as a bytes object. A binascii.Error is raised if
|
||||||
|
the input is incorrectly padded or if there are non-alphabet
|
||||||
|
characters present in the input.
|
||||||
|
"""
|
||||||
|
global _b32rev
|
||||||
|
# Delay the initialization of the table to not waste memory
|
||||||
|
# if the function is never called
|
||||||
|
if _b32rev is None:
|
||||||
|
_b32rev = {v: k for k, v in enumerate(_b32alphabet)}
|
||||||
|
s = _bytes_from_decode_data(s)
|
||||||
|
if len(s) % 8:
|
||||||
|
raise binascii.Error('Incorrect padding')
|
||||||
|
# Handle section 2.4 zero and one mapping. The flag map01 will be either
|
||||||
|
# False, or the character to map the digit 1 (one) to. It should be
|
||||||
|
# either L (el) or I (eye).
|
||||||
|
if map01 is not None:
|
||||||
|
map01 = _bytes_from_decode_data(map01)
|
||||||
|
assert len(map01) == 1, repr(map01)
|
||||||
|
s = s.translate(bytes.maketrans(b'01', b'O' + map01))
|
||||||
|
if casefold:
|
||||||
|
s = s.upper()
|
||||||
|
# Strip off pad characters from the right. We need to count the pad
|
||||||
|
# characters because this will tell us how many null bytes to remove from
|
||||||
|
# the end of the decoded string.
|
||||||
|
l = len(s)
|
||||||
|
s = s.rstrip(b'=')
|
||||||
|
padchars = l - len(s)
|
||||||
|
# Now decode the full quanta
|
||||||
|
decoded = bytearray()
|
||||||
|
b32rev = _b32rev
|
||||||
|
for i in range(0, len(s), 8):
|
||||||
|
quanta = s[i: i + 8]
|
||||||
|
acc = 0
|
||||||
|
try:
|
||||||
|
for c in quanta:
|
||||||
|
acc = (acc << 5) + b32rev[c]
|
||||||
|
except KeyError:
|
||||||
|
raise binascii.Error('Non-base32 digit found') from None
|
||||||
|
decoded += acc.to_bytes(5, 'big')
|
||||||
|
# Process the last, partial quanta
|
||||||
|
if padchars:
|
||||||
|
acc <<= 5 * padchars
|
||||||
|
last = acc.to_bytes(5, 'big')
|
||||||
|
if padchars == 1:
|
||||||
|
decoded[-5:] = last[:-1]
|
||||||
|
elif padchars == 3:
|
||||||
|
decoded[-5:] = last[:-2]
|
||||||
|
elif padchars == 4:
|
||||||
|
decoded[-5:] = last[:-3]
|
||||||
|
elif padchars == 6:
|
||||||
|
decoded[-5:] = last[:-4]
|
||||||
|
else:
|
||||||
|
raise binascii.Error('Incorrect padding')
|
||||||
|
return bytes(decoded)
|
||||||
|
|
||||||
|
def dec32(data):
|
||||||
|
if isinstance(data, bytes):
|
||||||
|
data = data.decode('ascii')
|
||||||
|
return b32decode(data + "="*((8 - len(data)%8)%8))
|
||||||
|
|
||||||
|
|
||||||
|
_patterns = [
|
||||||
|
(b'UC', 24), # channel
|
||||||
|
(b'PL', 34), # playlist
|
||||||
|
(b'LL', 24), # liked videos playlist
|
||||||
|
(b'UU', 24), # user uploads playlist
|
||||||
|
(b'RD', 15), # radio mix
|
||||||
|
(b'RD', 43), # radio mix
|
||||||
|
(b'', 11), # video
|
||||||
|
(b'Ug', 26), # comment
|
||||||
|
(b'Ug', 49), # comment reply (of form parent_id.reply_id)
|
||||||
|
(b'9', 22), # comment reply id
|
||||||
|
]
|
||||||
|
def is_youtube_object_id(data):
|
||||||
|
try:
|
||||||
|
if isinstance(data, str):
|
||||||
|
data = data.encode('ascii')
|
||||||
|
except Exception:
|
||||||
|
return False
|
||||||
|
|
||||||
|
for start_sequence, length in _patterns:
|
||||||
|
if len(data) == length and data.startswith(start_sequence):
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def recursive_pb(data):
|
||||||
|
try:
|
||||||
|
# check if this fits the basic requirements for base64
|
||||||
|
if isinstance(data, str) or all(i > 32 for i in data):
|
||||||
|
if len(data) > 11 and not is_youtube_object_id(data):
|
||||||
|
raw_data = b64_to_bytes(data)
|
||||||
|
b64_type = get_b64_type(data)
|
||||||
|
|
||||||
|
rpb = recursive_pb(raw_data)
|
||||||
|
if rpb == raw_data:
|
||||||
|
# could not interpret as protobuf, probably not b64
|
||||||
|
return data
|
||||||
|
return (b64_type, rpb)
|
||||||
|
else:
|
||||||
|
return data
|
||||||
|
except Exception as e:
|
||||||
|
return data
|
||||||
|
|
||||||
|
try:
|
||||||
|
result = pb(data, mutable=True)
|
||||||
|
except Exception as e:
|
||||||
|
return data
|
||||||
|
|
||||||
|
for tuple in result:
|
||||||
|
if tuple[0] == 2:
|
||||||
|
tuple[2] = recursive_pb(tuple[2])
|
||||||
|
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def indent_lines(lines, indent):
|
||||||
|
return re.sub(r'^', ' '*indent, lines, flags=re.MULTILINE)
|
||||||
|
|
||||||
|
def _pp(obj, indent): # not my best work
|
||||||
|
if isinstance(obj, tuple):
|
||||||
|
if len(obj) == 3: # (wire_type, field_number, data)
|
||||||
|
return obj.__repr__()
|
||||||
|
else: # (base64, [...])
|
||||||
|
return ('(' + obj[0].__repr__() + ',\n'
|
||||||
|
+ indent_lines(_pp(obj[1], indent), indent) + '\n'
|
||||||
|
+ ')')
|
||||||
|
elif isinstance(obj, list):
|
||||||
|
# [wire_type, field_number, data]
|
||||||
|
if (len(obj) == 3
|
||||||
|
and not any(isinstance(x, (list, tuple)) for x in obj)
|
||||||
|
):
|
||||||
|
return obj.__repr__()
|
||||||
|
|
||||||
|
# [wire_type, field_number, [...]]
|
||||||
|
elif (len(obj) == 3
|
||||||
|
and not any(isinstance(x, (list, tuple)) for x in obj[0:2])
|
||||||
|
):
|
||||||
|
return ('[' + obj[0].__repr__() + ', ' + obj[1].__repr__() + ',\n'
|
||||||
|
+ indent_lines(_pp(obj[2], indent), indent) + '\n'
|
||||||
|
+ ']')
|
||||||
|
else:
|
||||||
|
s = '[\n'
|
||||||
|
for x in obj:
|
||||||
|
s += indent_lines(_pp(x, indent), indent) + ',\n'
|
||||||
|
s += ']'
|
||||||
|
return s
|
||||||
|
else:
|
||||||
|
return obj.__repr__()
|
||||||
|
|
||||||
|
def pp(obj, indent=1):
|
||||||
|
'''Pretty prints the recursive pb structure'''
|
||||||
|
print(_pp(obj, indent))
|
||||||
|
|
||||||
|
|
||||||
|
desktop_user_agent = 'Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0'
|
||||||
|
desktop_headers = (
|
||||||
|
('Accept', '*/*'),
|
||||||
|
('Accept-Language', 'en-US,en;q=0.5'),
|
||||||
|
('X-YouTube-Client-Name', '1'),
|
||||||
|
('X-YouTube-Client-Version', '2.20180830'),
|
||||||
|
) + (('User-Agent', desktop_user_agent),)
|
||||||
|
|
||||||
|
mobile_user_agent = 'Mozilla/5.0 (Linux; Android 7.0; Redmi Note 4 Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Mobile Safari/537.36'
|
||||||
|
mobile_headers = (
|
||||||
|
('Accept', '*/*'),
|
||||||
|
('Accept-Language', 'en-US,en;q=0.5'),
|
||||||
|
('X-YouTube-Client-Name', '2'),
|
||||||
|
('X-YouTube-Client-Version', '2.20180830'),
|
||||||
|
) + (('User-Agent', mobile_user_agent),)
|
||||||
|
|
||||||
|
|
||||||
113
youtube/search.py
Normal file
113
youtube/search.py
Normal file
@@ -0,0 +1,113 @@
|
|||||||
|
from youtube import util, yt_data_extract, proto, local_playlist
|
||||||
|
from youtube import yt_app
|
||||||
|
import settings
|
||||||
|
|
||||||
|
import json
|
||||||
|
import urllib
|
||||||
|
import base64
|
||||||
|
import mimetypes
|
||||||
|
from flask import request
|
||||||
|
import flask
|
||||||
|
import os
|
||||||
|
|
||||||
|
# Sort: 1
|
||||||
|
# Upload date: 2
|
||||||
|
# View count: 3
|
||||||
|
# Rating: 1
|
||||||
|
# Relevance: 0
|
||||||
|
# Offset: 9
|
||||||
|
# Filters: 2
|
||||||
|
# Upload date: 1
|
||||||
|
# Type: 2
|
||||||
|
# Duration: 3
|
||||||
|
|
||||||
|
|
||||||
|
features = {
|
||||||
|
'4k': 14,
|
||||||
|
'hd': 4,
|
||||||
|
'hdr': 25,
|
||||||
|
'subtitles': 5,
|
||||||
|
'creative_commons': 6,
|
||||||
|
'3d': 7,
|
||||||
|
'live': 8,
|
||||||
|
'purchased': 9,
|
||||||
|
'360': 15,
|
||||||
|
'location': 23,
|
||||||
|
}
|
||||||
|
|
||||||
|
def page_number_to_sp_parameter(page, autocorrect, sort, filters):
|
||||||
|
offset = (int(page) - 1)*20 # 20 results per page
|
||||||
|
autocorrect = proto.nested(8, proto.uint(1, 1 - int(autocorrect) ))
|
||||||
|
filters_enc = proto.nested(2, proto.uint(1, filters['time']) + proto.uint(2, filters['type']) + proto.uint(3, filters['duration']))
|
||||||
|
result = proto.uint(1, sort) + filters_enc + autocorrect + proto.uint(9, offset) + proto.string(61, b'')
|
||||||
|
return base64.urlsafe_b64encode(result).decode('ascii')
|
||||||
|
|
||||||
|
def get_search_json(query, page, autocorrect, sort, filters):
|
||||||
|
url = "https://www.youtube.com/results?search_query=" + urllib.parse.quote_plus(query)
|
||||||
|
headers = {
|
||||||
|
'Host': 'www.youtube.com',
|
||||||
|
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)',
|
||||||
|
'Accept': '*/*',
|
||||||
|
'Accept-Language': 'en-US,en;q=0.5',
|
||||||
|
'X-YouTube-Client-Name': '1',
|
||||||
|
'X-YouTube-Client-Version': '2.20180418',
|
||||||
|
}
|
||||||
|
url += "&pbj=1&sp=" + page_number_to_sp_parameter(page, autocorrect, sort, filters).replace("=", "%3D")
|
||||||
|
content = util.fetch_url(url, headers=headers, report_text="Got search results", debug_name='search_results')
|
||||||
|
info = json.loads(content)
|
||||||
|
return info
|
||||||
|
|
||||||
|
|
||||||
|
@yt_app.route('/results')
|
||||||
|
@yt_app.route('/search')
|
||||||
|
def get_search_page():
|
||||||
|
query = request.args.get('search_query') or request.args.get('query')
|
||||||
|
if query is None:
|
||||||
|
return flask.render_template('base.html', title='Search')
|
||||||
|
elif query.startswith('https://www.youtube.com') or query.startswith('https://www.youtu.be'):
|
||||||
|
return flask.redirect(f'/{query}')
|
||||||
|
|
||||||
|
page = request.args.get("page", "1")
|
||||||
|
autocorrect = int(request.args.get("autocorrect", "1"))
|
||||||
|
sort = int(request.args.get("sort", "0"))
|
||||||
|
filters = {}
|
||||||
|
filters['time'] = int(request.args.get("time", "0"))
|
||||||
|
filters['type'] = int(request.args.get("type", "0"))
|
||||||
|
filters['duration'] = int(request.args.get("duration", "0"))
|
||||||
|
polymer_json = get_search_json(query, page, autocorrect, sort, filters)
|
||||||
|
|
||||||
|
search_info = yt_data_extract.extract_search_info(polymer_json)
|
||||||
|
if search_info['error']:
|
||||||
|
return flask.render_template('error.html', error_message = search_info['error'])
|
||||||
|
|
||||||
|
for extract_item_info in search_info['items']:
|
||||||
|
util.prefix_urls(extract_item_info)
|
||||||
|
util.add_extra_html_info(extract_item_info)
|
||||||
|
|
||||||
|
corrections = search_info['corrections']
|
||||||
|
if corrections['type'] == 'did_you_mean':
|
||||||
|
corrected_query_string = request.args.to_dict(flat=False)
|
||||||
|
corrected_query_string['search_query'] = [corrections['corrected_query']]
|
||||||
|
corrections['corrected_query_url'] = util.URL_ORIGIN + '/results?' + urllib.parse.urlencode(corrected_query_string, doseq=True)
|
||||||
|
elif corrections['type'] == 'showing_results_for':
|
||||||
|
no_autocorrect_query_string = request.args.to_dict(flat=False)
|
||||||
|
no_autocorrect_query_string['autocorrect'] = ['0']
|
||||||
|
no_autocorrect_query_url = util.URL_ORIGIN + '/results?' + urllib.parse.urlencode(no_autocorrect_query_string, doseq=True)
|
||||||
|
corrections['original_query_url'] = no_autocorrect_query_url
|
||||||
|
|
||||||
|
return flask.render_template('search.html',
|
||||||
|
header_playlist_names = local_playlist.get_playlist_names(),
|
||||||
|
query = query,
|
||||||
|
estimated_results = search_info['estimated_results'],
|
||||||
|
estimated_pages = search_info['estimated_pages'],
|
||||||
|
corrections = search_info['corrections'],
|
||||||
|
results = search_info['items'],
|
||||||
|
parameters_dictionary = request.args,
|
||||||
|
)
|
||||||
|
|
||||||
|
@yt_app.route('/opensearch.xml')
|
||||||
|
def get_search_engine_xml():
|
||||||
|
with open(os.path.join(settings.program_directory, 'youtube/opensearch.xml'), 'rb') as f:
|
||||||
|
content = f.read().replace(b'$host_url',
|
||||||
|
request.host_url.rstrip('/').encode())
|
||||||
|
return flask.Response(content, mimetype='application/xml')
|
||||||
196
youtube/static/comments.css
Normal file
196
youtube/static/comments.css
Normal file
@@ -0,0 +1,196 @@
|
|||||||
|
.video-metadata{
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: auto 1fr;
|
||||||
|
grid-template-rows: auto auto 1fr;
|
||||||
|
grid-template-areas:
|
||||||
|
"video-metadata-thumbnail-box title"
|
||||||
|
"video-metadata-thumbnail-box page"
|
||||||
|
"video-metadata-thumbnail-box sort";
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
.video-metadata > .video-metadata-thumbnail-box{
|
||||||
|
grid-area: video-metadata-thumbnail-box;
|
||||||
|
/* https://www.smashingmagazine.com/2020/03/setting-height-width-images-important-again/ */
|
||||||
|
position: relative;
|
||||||
|
width:320px;
|
||||||
|
max-width:100%;
|
||||||
|
}
|
||||||
|
.video-metadata > .video-metadata-thumbnail-box:before{
|
||||||
|
display: block;
|
||||||
|
content: "";
|
||||||
|
height: 0px;
|
||||||
|
padding-top: calc(180/320*100%);
|
||||||
|
}
|
||||||
|
.video-metadata-thumbnail-box img{
|
||||||
|
position: absolute;
|
||||||
|
top: 0;
|
||||||
|
left: 0;
|
||||||
|
width: 100%;
|
||||||
|
height: 100%;
|
||||||
|
}
|
||||||
|
.video-metadata > .title{
|
||||||
|
word-wrap:break-word;
|
||||||
|
grid-area: title;
|
||||||
|
}
|
||||||
|
.video-metadata > h2{
|
||||||
|
grid-area: page;
|
||||||
|
font-size: 0.875rem;
|
||||||
|
}
|
||||||
|
.video-metadata > span{
|
||||||
|
grid-area: sort;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment-form{
|
||||||
|
display: grid;
|
||||||
|
align-content: start;
|
||||||
|
justify-items: start;
|
||||||
|
align-items: start;
|
||||||
|
}
|
||||||
|
#comment-account-options{
|
||||||
|
display:grid;
|
||||||
|
grid-auto-flow: column;
|
||||||
|
grid-column-gap: 10px;
|
||||||
|
margin-top:10px;
|
||||||
|
margin-bottom:10px;
|
||||||
|
}
|
||||||
|
#comment-account-options a{
|
||||||
|
margin-left:10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comments-area{
|
||||||
|
display:grid;
|
||||||
|
}
|
||||||
|
.comments-area textarea{
|
||||||
|
resize: vertical;
|
||||||
|
justify-self:stretch;
|
||||||
|
}
|
||||||
|
.post-comment-button{
|
||||||
|
margin-top:10px;
|
||||||
|
justify-self:end;
|
||||||
|
}
|
||||||
|
.comment-links{
|
||||||
|
display:grid;
|
||||||
|
grid-auto-flow: column;
|
||||||
|
grid-column-gap: 10px;
|
||||||
|
justify-content:start;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comments{
|
||||||
|
margin-top:10px;
|
||||||
|
grid-row-gap: 10px;
|
||||||
|
display: grid;
|
||||||
|
align-content:start;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment{
|
||||||
|
display:grid;
|
||||||
|
grid-template-columns: repeat(3, auto) 1fr;
|
||||||
|
grid-template-rows: repeat(4, auto);
|
||||||
|
grid-template-areas:
|
||||||
|
"author-avatar author-name permalink ."
|
||||||
|
"author-avatar comment-text comment-text comment-text"
|
||||||
|
"author-avatar comment-likes comment-likes comment-likes"
|
||||||
|
". bottom-row bottom-row bottom-row";
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
justify-content: start;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment .author-avatar{
|
||||||
|
grid-area: author-avatar;
|
||||||
|
align-self: start;
|
||||||
|
margin-right: 5px;
|
||||||
|
height:32px;
|
||||||
|
width:32px;
|
||||||
|
}
|
||||||
|
.comment .author-avatar-img{
|
||||||
|
max-height: 100%;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment .author-name{
|
||||||
|
grid-area: author-name;
|
||||||
|
margin-right:15px;
|
||||||
|
white-space: nowrap;
|
||||||
|
overflow:hidden;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment .text{
|
||||||
|
grid-area: comment-text;
|
||||||
|
white-space: pre-wrap;
|
||||||
|
min-width: 0;
|
||||||
|
word-wrap: break-word;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment .permalink{
|
||||||
|
grid-area: permalink;
|
||||||
|
white-space: nowrap;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
.comment .likes{
|
||||||
|
grid-area: comment-likes;
|
||||||
|
font-weight:bold;
|
||||||
|
white-space: nowrap;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment .bottom-row{
|
||||||
|
grid-area: bottom-row;
|
||||||
|
justify-self:start;
|
||||||
|
}
|
||||||
|
|
||||||
|
details.replies > summary{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
border-style: outset;
|
||||||
|
border-width: 1px;
|
||||||
|
font-weight: bold;
|
||||||
|
padding: 2px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.replies-open-new-tab{
|
||||||
|
display: inline-block;
|
||||||
|
margin-top: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
details.replies .comment{
|
||||||
|
max-width: 600px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.more-comments{
|
||||||
|
justify-self:center;
|
||||||
|
margin-top:10px;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media (max-width:500px){
|
||||||
|
.video-metadata{
|
||||||
|
grid-template-columns: 1fr;
|
||||||
|
grid-template-rows: 1fr auto auto auto;
|
||||||
|
grid-template-areas:
|
||||||
|
"video-metadata-thumbnail-box"
|
||||||
|
"title"
|
||||||
|
"page"
|
||||||
|
"sort";
|
||||||
|
}
|
||||||
|
.video-metadata > .video-metadata-thumbnail-box{
|
||||||
|
grid-area: video-metadata-thumbnail-box;
|
||||||
|
/* Switching these is required. Otherwise it breaks for some reason. CSS is terrible */
|
||||||
|
width: 100%;
|
||||||
|
max-width: 320px;
|
||||||
|
}
|
||||||
|
.comment{
|
||||||
|
grid-template-columns: auto 1fr;
|
||||||
|
grid-template-rows: repeat(5, auto);
|
||||||
|
grid-template-areas:
|
||||||
|
"author-avatar author-name"
|
||||||
|
"author-avatar comment-text"
|
||||||
|
"author-avatar comment-likes"
|
||||||
|
"author-avatar permalink"
|
||||||
|
". bottom-row";
|
||||||
|
}
|
||||||
|
.comment .author-name{
|
||||||
|
margin-right: 0px;
|
||||||
|
}
|
||||||
|
.comment .permalink{
|
||||||
|
justify-self: start;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
}
|
||||||
66
youtube/static/dark_theme.css
Normal file
66
youtube/static/dark_theme.css
Normal file
@@ -0,0 +1,66 @@
|
|||||||
|
body{
|
||||||
|
--interface-color: #333333;
|
||||||
|
--text-color: #cccccc;
|
||||||
|
--background-color: #000000;
|
||||||
|
--video-background-color: #080808;
|
||||||
|
--link-color-rgb: 34, 170, 255;
|
||||||
|
--visited-link-color-rgb: 119, 85, 255;
|
||||||
|
}
|
||||||
|
|
||||||
|
a:link {
|
||||||
|
color: rgb(var(--link-color-rgb));
|
||||||
|
}
|
||||||
|
|
||||||
|
a:visited {
|
||||||
|
color: rgb(var(--visited-link-color-rgb));
|
||||||
|
}
|
||||||
|
|
||||||
|
a:not([href]){
|
||||||
|
color: var(--text-color);
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment .permalink{
|
||||||
|
color: #ffffff;
|
||||||
|
}
|
||||||
|
|
||||||
|
.setting-item{
|
||||||
|
background-color: #444444;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
.muted{
|
||||||
|
background-color: #111111;
|
||||||
|
color: gray;
|
||||||
|
}
|
||||||
|
|
||||||
|
.muted a:link {
|
||||||
|
color: #10547f;
|
||||||
|
}
|
||||||
|
|
||||||
|
.button,
|
||||||
|
input,
|
||||||
|
select,
|
||||||
|
button[type=submit]{
|
||||||
|
color: var(--text-color);
|
||||||
|
background-color: #444444;
|
||||||
|
border: 1px solid var(--text-color);
|
||||||
|
border-radius: 3px;
|
||||||
|
padding: 2px 3px;
|
||||||
|
}
|
||||||
|
.button:hover,
|
||||||
|
input:hover,
|
||||||
|
select:hover,
|
||||||
|
button[type=submit]:hover{
|
||||||
|
background-color: #222222;
|
||||||
|
}
|
||||||
|
|
||||||
|
input[type="checkbox"]{
|
||||||
|
-webkit-filter: invert(85%) hue-rotate(18deg) brightness(1.7);
|
||||||
|
filter: invert(85%) hue-rotate(18deg) brightness(1.7);
|
||||||
|
}
|
||||||
|
input[type="checkbox"]:checked{
|
||||||
|
-webkit-filter: none;
|
||||||
|
filter: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
BIN
youtube/static/favicon.ico
Normal file
BIN
youtube/static/favicon.ico
Normal file
Binary file not shown.
|
After Width: | Height: | Size: 5.6 KiB |
20
youtube/static/gray_theme.css
Normal file
20
youtube/static/gray_theme.css
Normal file
@@ -0,0 +1,20 @@
|
|||||||
|
body{
|
||||||
|
--interface-color: #dadada;
|
||||||
|
--text-color: #222222;
|
||||||
|
--background-color: #bcbcbc;
|
||||||
|
--video-background-color: #dadada;
|
||||||
|
--link-color-rgb: 0, 0, 238;
|
||||||
|
--visited-link-color-rgb: 85, 26, 139;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment .permalink{
|
||||||
|
color: #000000;
|
||||||
|
}
|
||||||
|
|
||||||
|
.setting-item{
|
||||||
|
background-color: #eeeeee;
|
||||||
|
}
|
||||||
|
|
||||||
|
.muted{
|
||||||
|
background-color: #888888;
|
||||||
|
}
|
||||||
986
youtube/static/js/av-merge.js
Normal file
986
youtube/static/js/av-merge.js
Normal file
@@ -0,0 +1,986 @@
|
|||||||
|
// Heavily modified from
|
||||||
|
// https://github.com/nickdesaulniers/netfix/issues/4#issuecomment-578856471
|
||||||
|
// which was in turn modified from
|
||||||
|
// https://github.com/nickdesaulniers/netfix/blob/gh-pages/demo/bufferWhenNeeded.html
|
||||||
|
|
||||||
|
// Useful reading:
|
||||||
|
// https://stackoverflow.com/questions/35177797/what-exactly-is-fragmented-mp4fmp4-how-is-it-different-from-normal-mp4
|
||||||
|
// https://axel.isouard.fr/blog/2016/05/24/streaming-webm-video-over-html5-with-media-source
|
||||||
|
|
||||||
|
// We start by parsing the sidx (segment index) table in order to get the
|
||||||
|
// byte ranges of the segments. The byte range of the sidx table is provided
|
||||||
|
// by the indexRange variable by YouTube
|
||||||
|
|
||||||
|
// Useful info, as well as segments vs sequence mode (we use segments mode)
|
||||||
|
// https://joshuatz.com/posts/2020/appending-videos-in-javascript-with-mediasource-buffers/
|
||||||
|
|
||||||
|
// SourceBuffer data limits:
|
||||||
|
// https://developers.google.com/web/updates/2017/10/quotaexceedederror
|
||||||
|
|
||||||
|
// TODO: Call abort to cancel in-progress appends?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
function AVMerge(video, srcInfo, startTime){
|
||||||
|
this.audioSource = null;
|
||||||
|
this.videoSource = null;
|
||||||
|
this.avRatio = null;
|
||||||
|
this.videoStream = null;
|
||||||
|
this.audioStream = null;
|
||||||
|
this.seeking = false;
|
||||||
|
this.startTime = startTime;
|
||||||
|
this.video = video;
|
||||||
|
this.mediaSource = null;
|
||||||
|
this.closed = false;
|
||||||
|
this.opened = false;
|
||||||
|
this.audioEndOfStreamCalled = false;
|
||||||
|
this.videoEndOfStreamCalled = false;
|
||||||
|
if (!('MediaSource' in window)) {
|
||||||
|
reportError('MediaSource not supported.');
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
|
||||||
|
// Find supported video and audio sources
|
||||||
|
for (var src of srcInfo['videos']) {
|
||||||
|
if (MediaSource.isTypeSupported(src['mime_codec'])) {
|
||||||
|
reportDebug('Using video source', src['mime_codec'],
|
||||||
|
src['quality_string'], 'itag', src['itag']);
|
||||||
|
this.videoSource = src;
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
for (var src of srcInfo['audios']) {
|
||||||
|
if (MediaSource.isTypeSupported(src['mime_codec'])) {
|
||||||
|
reportDebug('Using audio source', src['mime_codec'],
|
||||||
|
src['quality_string'], 'itag', src['itag']);
|
||||||
|
this.audioSource = src;
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
if (this.videoSource === null)
|
||||||
|
reportError('No supported video MIME type or codec found: ',
|
||||||
|
srcInfo['videos'].map(s => s.mime_codec).join(', '));
|
||||||
|
if (this.audioSource === null)
|
||||||
|
reportError('No supported audio MIME type or codec found: ',
|
||||||
|
srcInfo['audios'].map(s => s.mime_codec).join(', '));
|
||||||
|
if (this.videoSource === null || this.audioSource === null)
|
||||||
|
return;
|
||||||
|
|
||||||
|
if (this.videoSource.bitrate && this.audioSource.bitrate)
|
||||||
|
this.avRatio = this.audioSource.bitrate/this.videoSource.bitrate;
|
||||||
|
else
|
||||||
|
this.avRatio = 1/10;
|
||||||
|
|
||||||
|
this.setup();
|
||||||
|
}
|
||||||
|
AVMerge.prototype.setup = function() {
|
||||||
|
this.mediaSource = new MediaSource();
|
||||||
|
this.video.src = URL.createObjectURL(this.mediaSource);
|
||||||
|
this.mediaSource.onsourceopen = this.sourceOpen.bind(this);
|
||||||
|
}
|
||||||
|
|
||||||
|
AVMerge.prototype.sourceOpen = function(_) {
|
||||||
|
// If after calling mediaSource.endOfStream, the user seeks back
|
||||||
|
// into the video, the sourceOpen event will be fired again. Do not
|
||||||
|
// overwrite the streams.
|
||||||
|
this.audioEndOfStreamCalled = false;
|
||||||
|
this.videoEndOfStreamCalled = false;
|
||||||
|
if (this.opened)
|
||||||
|
return;
|
||||||
|
this.opened = true;
|
||||||
|
this.videoStream = new Stream(this, this.videoSource, this.startTime,
|
||||||
|
this.avRatio);
|
||||||
|
this.audioStream = new Stream(this, this.audioSource, this.startTime,
|
||||||
|
this.avRatio);
|
||||||
|
|
||||||
|
this.videoStream.setup();
|
||||||
|
this.audioStream.setup();
|
||||||
|
|
||||||
|
this.timeUpdateEvt = addEvent(this.video, 'timeupdate',
|
||||||
|
this.checkBothBuffers.bind(this));
|
||||||
|
this.seekingEvt = addEvent(this.video, 'seeking',
|
||||||
|
debounce(this.seek.bind(this), 500));
|
||||||
|
//this.video.onseeked = function() {console.log('seeked')};
|
||||||
|
}
|
||||||
|
AVMerge.prototype.close = function() {
|
||||||
|
if (this.closed)
|
||||||
|
return;
|
||||||
|
this.closed = true;
|
||||||
|
this.videoStream.close();
|
||||||
|
this.audioStream.close();
|
||||||
|
this.timeUpdateEvt.remove();
|
||||||
|
this.seekingEvt.remove();
|
||||||
|
if (this.mediaSource.readyState == 'open')
|
||||||
|
this.mediaSource.endOfStream();
|
||||||
|
}
|
||||||
|
AVMerge.prototype.checkBothBuffers = function() {
|
||||||
|
this.audioStream.checkBuffer();
|
||||||
|
this.videoStream.checkBuffer();
|
||||||
|
}
|
||||||
|
AVMerge.prototype.seek = function(e) {
|
||||||
|
if (this.mediaSource.readyState === 'open') {
|
||||||
|
this.seeking = true;
|
||||||
|
this.audioStream.handleSeek();
|
||||||
|
this.videoStream.handleSeek();
|
||||||
|
this.seeking = false;
|
||||||
|
} else {
|
||||||
|
reportWarning('seek but not open? readyState:',
|
||||||
|
this.mediaSource.readyState);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
AVMerge.prototype.audioEndOfStream = function() {
|
||||||
|
if (this.videoEndOfStreamCalled && !this.audioEndOfStreamCalled) {
|
||||||
|
reportDebug('Calling mediaSource.endOfStream()');
|
||||||
|
this.mediaSource.endOfStream();
|
||||||
|
}
|
||||||
|
this.audioEndOfStreamCalled = true;
|
||||||
|
}
|
||||||
|
AVMerge.prototype.videoEndOfStream = function() {
|
||||||
|
if (this.audioEndOfStreamCalled && !this.videoEndOfStreamCalled) {
|
||||||
|
reportDebug('Calling mediaSource.endOfStream()');
|
||||||
|
this.mediaSource.endOfStream();
|
||||||
|
}
|
||||||
|
this.videoEndOfStreamCalled = true;
|
||||||
|
}
|
||||||
|
AVMerge.prototype.printDebuggingInfo = function() {
|
||||||
|
reportDebug('videoSource:', this.videoSource);
|
||||||
|
reportDebug('audioSource:', this.videoSource);
|
||||||
|
reportDebug('video sidx:', this.videoStream.sidx);
|
||||||
|
reportDebug('audio sidx:', this.audioStream.sidx);
|
||||||
|
reportDebug('video updating', this.videoStream.sourceBuffer.updating);
|
||||||
|
reportDebug('audio updating', this.audioStream.sourceBuffer.updating);
|
||||||
|
reportDebug('video duration:', this.video.duration);
|
||||||
|
reportDebug('video current time:', this.video.currentTime);
|
||||||
|
reportDebug('mediaSource.readyState:', this.mediaSource.readyState);
|
||||||
|
reportDebug('videoEndOfStreamCalled', this.videoEndOfStreamCalled);
|
||||||
|
reportDebug('audioEndOfStreamCalled', this.audioEndOfStreamCalled);
|
||||||
|
for (let obj of [this.videoStream, this.audioStream]) {
|
||||||
|
reportDebug(obj.streamType, 'stream buffered times:');
|
||||||
|
for (let i=0; i<obj.sourceBuffer.buffered.length; i++) {
|
||||||
|
reportDebug(String(obj.sourceBuffer.buffered.start(i)) + '-'
|
||||||
|
+ String(obj.sourceBuffer.buffered.end(i)));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
function Stream(avMerge, source, startTime, avRatio) {
|
||||||
|
this.avMerge = avMerge;
|
||||||
|
this.video = avMerge.video;
|
||||||
|
this.url = source['url'];
|
||||||
|
this.ext = source['ext'];
|
||||||
|
this.fileSize = source['file_size'];
|
||||||
|
this.closed = false;
|
||||||
|
this.mimeCodec = source['mime_codec']
|
||||||
|
this.streamType = source['acodec'] ? 'audio' : 'video';
|
||||||
|
if (this.streamType == 'audio') {
|
||||||
|
this.bufferTarget = avRatio*50*10**6;
|
||||||
|
} else {
|
||||||
|
this.bufferTarget = 50*10**6; // 50 megabytes
|
||||||
|
}
|
||||||
|
|
||||||
|
this.initRange = source['init_range'];
|
||||||
|
this.indexRange = source['index_range'];
|
||||||
|
|
||||||
|
this.startTime = startTime;
|
||||||
|
this.mediaSource = avMerge.mediaSource;
|
||||||
|
this.sidx = null;
|
||||||
|
this.appendRetries = 0;
|
||||||
|
this.appendQueue = []; // list of [segmentIdx, data]
|
||||||
|
this.sourceBuffer = this.mediaSource.addSourceBuffer(this.mimeCodec);
|
||||||
|
this.sourceBuffer.mode = 'segments';
|
||||||
|
this.sourceBuffer.addEventListener('error', (e) => {
|
||||||
|
this.reportError('sourceBuffer error', e);
|
||||||
|
});
|
||||||
|
this.updateendEvt = addEvent(this.sourceBuffer, 'updateend', (e) => {
|
||||||
|
if (this.appendQueue.length != 0) {
|
||||||
|
this.appendSegment(...this.appendQueue.shift());
|
||||||
|
}
|
||||||
|
});
|
||||||
|
}
|
||||||
|
Stream.prototype.setup = async function(){
|
||||||
|
// Group requests together
|
||||||
|
if (this.initRange.end+1 == this.indexRange.start){
|
||||||
|
fetchRange(
|
||||||
|
this.url,
|
||||||
|
this.initRange.start,
|
||||||
|
this.indexRange.end,
|
||||||
|
'Initialization+index segments',
|
||||||
|
).then(
|
||||||
|
(buffer) => {
|
||||||
|
var init_end = this.initRange.end - this.initRange.start + 1;
|
||||||
|
var index_start = this.indexRange.start - this.initRange.start;
|
||||||
|
var index_end = this.indexRange.end - this.initRange.start + 1;
|
||||||
|
this.setupInitSegment(buffer.slice(0, init_end));
|
||||||
|
this.setupSegmentIndex(buffer.slice(index_start, index_end));
|
||||||
|
}
|
||||||
|
);
|
||||||
|
} else {
|
||||||
|
// initialization data
|
||||||
|
await fetchRange(
|
||||||
|
this.url,
|
||||||
|
this.initRange.start,
|
||||||
|
this.initRange.end,
|
||||||
|
'Initialization segment',
|
||||||
|
).then(this.setupInitSegment.bind(this));
|
||||||
|
|
||||||
|
// sidx (segment index) table
|
||||||
|
fetchRange(
|
||||||
|
this.url,
|
||||||
|
this.indexRange.start,
|
||||||
|
this.indexRange.end,
|
||||||
|
'Index segment',
|
||||||
|
).then(this.setupSegmentIndex.bind(this));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
Stream.prototype.setupInitSegment = function(initSegment) {
|
||||||
|
if (this.ext == 'webm')
|
||||||
|
this.sidx = extractWebmInitializationInfo(initSegment);
|
||||||
|
this.appendSegment(null, initSegment);
|
||||||
|
}
|
||||||
|
Stream.prototype.setupSegmentIndex = async function(indexSegment){
|
||||||
|
if (this.ext == 'webm') {
|
||||||
|
this.sidx.entries = parseWebmCues(indexSegment, this.sidx);
|
||||||
|
if (this.fileSize) {
|
||||||
|
let lastIdx = this.sidx.entries.length - 1;
|
||||||
|
this.sidx.entries[lastIdx].end = this.fileSize - 1;
|
||||||
|
}
|
||||||
|
for (let entry of this.sidx.entries) {
|
||||||
|
entry.subSegmentDuration = entry.tickEnd - entry.tickStart + 1;
|
||||||
|
if (entry.end)
|
||||||
|
entry.referencedSize = entry.end - entry.start + 1;
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
var box = unbox(indexSegment);
|
||||||
|
this.sidx = sidx_parse(box.data, this.indexRange.end+1);
|
||||||
|
}
|
||||||
|
this.fetchSegmentIfNeeded(this.getSegmentIdx(this.startTime));
|
||||||
|
}
|
||||||
|
Stream.prototype.close = function() {
|
||||||
|
// Prevents appendSegment adding to buffer if request finishes
|
||||||
|
// after closing
|
||||||
|
this.closed = true;
|
||||||
|
if (this.sourceBuffer.updating)
|
||||||
|
this.sourceBuffer.abort();
|
||||||
|
this.mediaSource.removeSourceBuffer(this.sourceBuffer);
|
||||||
|
this.updateendEvt.remove();
|
||||||
|
}
|
||||||
|
Stream.prototype.appendSegment = function(segmentIdx, chunk) {
|
||||||
|
if (this.closed)
|
||||||
|
return;
|
||||||
|
|
||||||
|
this.reportDebug('Received segment', segmentIdx)
|
||||||
|
|
||||||
|
// cannot append right now, schedule for updateend
|
||||||
|
if (this.sourceBuffer.updating) {
|
||||||
|
this.reportDebug('sourceBuffer updating, queueing for later');
|
||||||
|
this.appendQueue.push([segmentIdx, chunk]);
|
||||||
|
if (this.appendQueue.length > 2){
|
||||||
|
this.reportWarning('appendQueue length:', this.appendQueue.length);
|
||||||
|
}
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
try {
|
||||||
|
this.sourceBuffer.appendBuffer(chunk);
|
||||||
|
if (segmentIdx !== null)
|
||||||
|
this.sidx.entries[segmentIdx].have = true;
|
||||||
|
this.appendRetries = 0;
|
||||||
|
} catch (e) {
|
||||||
|
if (e.name !== 'QuotaExceededError') {
|
||||||
|
throw e;
|
||||||
|
}
|
||||||
|
this.reportWarning('QuotaExceededError.');
|
||||||
|
|
||||||
|
// Count how many bytes are in buffer to update buffering target,
|
||||||
|
// updating .have as well for when we need to delete segments
|
||||||
|
var bytesInBuffer = 0;
|
||||||
|
for (var i = 0; i < this.sidx.entries.length; i++) {
|
||||||
|
if (this.segmentInBuffer(i))
|
||||||
|
bytesInBuffer += this.sidx.entries[i].referencedSize;
|
||||||
|
else if (this.sidx.entries[i].have) {
|
||||||
|
this.sidx.entries[i].have = false;
|
||||||
|
this.sidx.entries[i].requested = false;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
bytesInBuffer = Math.floor(4/5*bytesInBuffer);
|
||||||
|
if (bytesInBuffer < this.bufferTarget) {
|
||||||
|
this.bufferTarget = bytesInBuffer;
|
||||||
|
this.reportDebug('New buffer target:', this.bufferTarget);
|
||||||
|
}
|
||||||
|
|
||||||
|
// Delete 10 segments (arbitrary) from buffer, making sure
|
||||||
|
// not to delete current one
|
||||||
|
var currentSegment = this.getSegmentIdx(this.video.currentTime);
|
||||||
|
var numDeleted = 0;
|
||||||
|
var i = 0;
|
||||||
|
const DELETION_TARGET = 10;
|
||||||
|
var toDelete = []; // See below for why we have to schedule it
|
||||||
|
this.reportDebug('Deleting segments from beginning of buffer.');
|
||||||
|
while (numDeleted < DELETION_TARGET && i < currentSegment) {
|
||||||
|
if (this.sidx.entries[i].have) {
|
||||||
|
toDelete.push(i)
|
||||||
|
numDeleted++;
|
||||||
|
}
|
||||||
|
i++;
|
||||||
|
}
|
||||||
|
if (numDeleted < DELETION_TARGET)
|
||||||
|
this.reportDebug('Deleting segments from end of buffer.');
|
||||||
|
|
||||||
|
i = this.sidx.entries.length - 1;
|
||||||
|
while (numDeleted < DELETION_TARGET && i > currentSegment) {
|
||||||
|
if (this.sidx.entries[i].have) {
|
||||||
|
toDelete.push(i)
|
||||||
|
numDeleted++;
|
||||||
|
}
|
||||||
|
i--;
|
||||||
|
}
|
||||||
|
|
||||||
|
// When calling .remove, the sourceBuffer will go into updating=true
|
||||||
|
// state, and remove cannot be called until it is done. So we have
|
||||||
|
// to delete on the updateend event for subsequent ones.
|
||||||
|
var removeFinishedEvent;
|
||||||
|
var deletedStuff = (toDelete.length !== 0)
|
||||||
|
var deleteSegment = () => {
|
||||||
|
if (toDelete.length === 0) {
|
||||||
|
removeFinishedEvent.remove();
|
||||||
|
// If QuotaExceeded happened for current segment, retry the
|
||||||
|
// append
|
||||||
|
// Rescheduling will take care of updating=true problem.
|
||||||
|
// Also check that we found segments to delete, to avoid
|
||||||
|
// infinite looping if we can't delete anything
|
||||||
|
if (segmentIdx === currentSegment && deletedStuff) {
|
||||||
|
this.reportDebug('Retrying appendSegment for', segmentIdx);
|
||||||
|
this.appendSegment(segmentIdx, chunk);
|
||||||
|
} else {
|
||||||
|
this.reportDebug('Not retrying segment', segmentIdx);
|
||||||
|
this.sidx.entries[segmentIdx].requested = false;
|
||||||
|
}
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
let idx = toDelete.shift();
|
||||||
|
let entry = this.sidx.entries[idx];
|
||||||
|
let start = entry.tickStart/this.sidx.timeScale;
|
||||||
|
let end = (entry.tickEnd+1)/this.sidx.timeScale;
|
||||||
|
this.reportDebug('Deleting segment', idx);
|
||||||
|
this.sourceBuffer.remove(start, end);
|
||||||
|
entry.have = false;
|
||||||
|
entry.requested = false;
|
||||||
|
}
|
||||||
|
removeFinishedEvent = addEvent(this.sourceBuffer, 'updateend',
|
||||||
|
deleteSegment);
|
||||||
|
if (!this.sourceBuffer.updating)
|
||||||
|
deleteSegment();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
Stream.prototype.getSegmentIdx = function(videoTime) {
|
||||||
|
// get an estimate
|
||||||
|
var currentTick = videoTime * this.sidx.timeScale;
|
||||||
|
var firstSegmentDuration = this.sidx.entries[0].subSegmentDuration;
|
||||||
|
var index = 1 + Math.floor(currentTick / firstSegmentDuration);
|
||||||
|
var index = clamp(index, 0, this.sidx.entries.length - 1);
|
||||||
|
|
||||||
|
var increment = 1;
|
||||||
|
if (currentTick < this.sidx.entries[index].tickStart){
|
||||||
|
increment = -1;
|
||||||
|
}
|
||||||
|
|
||||||
|
// go up or down to find correct index
|
||||||
|
while (index >= 0 && index < this.sidx.entries.length) {
|
||||||
|
var entry = this.sidx.entries[index];
|
||||||
|
if (entry.tickStart <= currentTick && (entry.tickEnd+1) > currentTick){
|
||||||
|
return index;
|
||||||
|
}
|
||||||
|
index = index + increment;
|
||||||
|
}
|
||||||
|
this.reportError('Could not find segment index for time', videoTime);
|
||||||
|
return 0;
|
||||||
|
}
|
||||||
|
Stream.prototype.checkBuffer = async function() {
|
||||||
|
if (this.avMerge.seeking) {
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
// Find the first unbuffered segment, i
|
||||||
|
var currentSegmentIdx = this.getSegmentIdx(this.video.currentTime);
|
||||||
|
var bufferedBytesAhead = 0;
|
||||||
|
var i;
|
||||||
|
for (i = currentSegmentIdx; i < this.sidx.entries.length; i++) {
|
||||||
|
var entry = this.sidx.entries[i];
|
||||||
|
// check if we had it before, but it was deleted by the browser
|
||||||
|
if (entry.have && !this.segmentInBuffer(i)) {
|
||||||
|
this.reportDebug('segment', i, 'deleted by browser');
|
||||||
|
entry.have = false;
|
||||||
|
entry.requested = false;
|
||||||
|
}
|
||||||
|
if (!entry.have) {
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
bufferedBytesAhead += entry.referencedSize;
|
||||||
|
if (bufferedBytesAhead > this.bufferTarget) {
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if (i < this.sidx.entries.length && !this.sidx.entries[i].requested) {
|
||||||
|
this.fetchSegment(i);
|
||||||
|
// We have all the segments until the end
|
||||||
|
// Signal the end of stream
|
||||||
|
} else if (i == this.sidx.entries.length) {
|
||||||
|
if (this.streamType == 'audio')
|
||||||
|
this.avMerge.audioEndOfStream();
|
||||||
|
else
|
||||||
|
this.avMerge.videoEndOfStream();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
Stream.prototype.segmentInBuffer = function(segmentIdx) {
|
||||||
|
var entry = this.sidx.entries[segmentIdx];
|
||||||
|
// allow for 0.01 second error
|
||||||
|
var timeStart = entry.tickStart/this.sidx.timeScale + 0.01;
|
||||||
|
|
||||||
|
/* Some of YouTube's mp4 fragments are malformed, with half-frame
|
||||||
|
playback gaps. In this video at 240p (timeScale = 90000 ticks/second)
|
||||||
|
https://www.youtube.com/watch?v=ZhOQCwJvwlo
|
||||||
|
segment 4 (starting at 0) is claimed in the sidx table to have
|
||||||
|
a duration of 388500 ticks, but closer examination of the file using
|
||||||
|
Bento4 mp4dump shows that the segment has 129 frames at 3000 ticks
|
||||||
|
per frame, which gives an actual duration of 38700 (1500 less than
|
||||||
|
claimed). The file is 30 fps, so this error is exactly half a frame.
|
||||||
|
|
||||||
|
Note that the base_media_decode_time exactly matches the tickStart,
|
||||||
|
so the media decoder is being given a time gap of half a frame.
|
||||||
|
|
||||||
|
The practical result of this is that sourceBuffer.buffered reports
|
||||||
|
a timeRange.end that is less than expected for that segment, resulting in
|
||||||
|
a false determination that the browser has deleted a segment.
|
||||||
|
|
||||||
|
Segment 5 has the opposite issue, where it has a 1500 tick surplus of video
|
||||||
|
data compared to the sidx length. Segments 6 and 7 also have this
|
||||||
|
deficit-surplus pattern.
|
||||||
|
|
||||||
|
This might have something to do with the fact that the video also
|
||||||
|
has 60 fps formats. In order to allow for adaptive streaming and seamless
|
||||||
|
quality switching, YouTube likely encodes their formats to line up nicely.
|
||||||
|
Either there is a bug in their encoder, or this is intentional. Allow for
|
||||||
|
up to 1 frame-time of error to work around this issue. */
|
||||||
|
if (this.streamType == 'video')
|
||||||
|
var endError = 1/(this.avMerge.videoSource.fps || 30);
|
||||||
|
else
|
||||||
|
var endError = 0.01
|
||||||
|
var timeEnd = (entry.tickEnd+1)/this.sidx.timeScale - endError;
|
||||||
|
|
||||||
|
var timeRanges = this.sourceBuffer.buffered;
|
||||||
|
for (var i=0; i < timeRanges.length; i++) {
|
||||||
|
if (timeRanges.start(i) <= timeStart && timeEnd <= timeRanges.end(i)) {
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
Stream.prototype.fetchSegment = function(segmentIdx) {
|
||||||
|
entry = this.sidx.entries[segmentIdx];
|
||||||
|
entry.requested = true;
|
||||||
|
this.reportDebug(
|
||||||
|
'Fetching segment', segmentIdx, ', bytes',
|
||||||
|
entry.start, entry.end, ', seconds',
|
||||||
|
entry.tickStart/this.sidx.timeScale,
|
||||||
|
(entry.tickEnd+1)/this.sidx.timeScale
|
||||||
|
)
|
||||||
|
fetchRange(
|
||||||
|
this.url,
|
||||||
|
entry.start,
|
||||||
|
entry.end,
|
||||||
|
String(this.streamType) + ' segment ' + String(segmentIdx),
|
||||||
|
).then(this.appendSegment.bind(this, segmentIdx));
|
||||||
|
}
|
||||||
|
Stream.prototype.fetchSegmentIfNeeded = function(segmentIdx) {
|
||||||
|
if (segmentIdx < 0 || segmentIdx >= this.sidx.entries.length){
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
entry = this.sidx.entries[segmentIdx];
|
||||||
|
// check if we had it before, but it was deleted by the browser
|
||||||
|
if (entry.have && !this.segmentInBuffer(segmentIdx)) {
|
||||||
|
this.reportDebug('segment', segmentIdx, 'deleted by browser');
|
||||||
|
entry.have = false;
|
||||||
|
entry.requested = false;
|
||||||
|
}
|
||||||
|
if (entry.requested) {
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
|
||||||
|
this.fetchSegment(segmentIdx);
|
||||||
|
}
|
||||||
|
Stream.prototype.handleSeek = function() {
|
||||||
|
var segmentIdx = this.getSegmentIdx(this.video.currentTime);
|
||||||
|
this.fetchSegmentIfNeeded(segmentIdx);
|
||||||
|
}
|
||||||
|
Stream.prototype.reportDebug = function(...args) {
|
||||||
|
reportDebug(String(this.streamType) + ':', ...args);
|
||||||
|
}
|
||||||
|
Stream.prototype.reportWarning = function(...args) {
|
||||||
|
reportWarning(String(this.streamType) + ':', ...args);
|
||||||
|
}
|
||||||
|
Stream.prototype.reportError = function(...args) {
|
||||||
|
reportError(String(this.streamType) + ':', ...args);
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
// Utility functions
|
||||||
|
|
||||||
|
// https://gomakethings.com/promise-based-xhr/
|
||||||
|
// https://stackoverflow.com/a/30008115
|
||||||
|
// http://lofi.limo/blog/retry-xmlhttprequest-carefully
|
||||||
|
function fetchRange(url, start, end, debugInfo) {
|
||||||
|
return new Promise((resolve, reject) => {
|
||||||
|
var retryCount = 0;
|
||||||
|
var xhr = new XMLHttpRequest();
|
||||||
|
function onFailure(err, message, maxRetries=5){
|
||||||
|
message = debugInfo + ': ' + message + ' - Err: ' + String(err);
|
||||||
|
retryCount++;
|
||||||
|
if (retryCount > maxRetries || xhr.status == 403){
|
||||||
|
reportError('fetchRange error while fetching ' + message);
|
||||||
|
reject(message);
|
||||||
|
return;
|
||||||
|
} else {
|
||||||
|
reportWarning('Failed to fetch ' + message
|
||||||
|
+ '. Attempting retry '
|
||||||
|
+ String(retryCount) +'/' + String(maxRetries));
|
||||||
|
}
|
||||||
|
|
||||||
|
// Retry in 1 second, doubled for each next retry
|
||||||
|
setTimeout(function(){
|
||||||
|
xhr.open('get',url);
|
||||||
|
xhr.send();
|
||||||
|
}, 1000*Math.pow(2,(retryCount-1)));
|
||||||
|
}
|
||||||
|
xhr.open('get', url);
|
||||||
|
xhr.timeout = 15000;
|
||||||
|
xhr.responseType = 'arraybuffer';
|
||||||
|
xhr.setRequestHeader('Range', 'bytes=' + start + '-' + end);
|
||||||
|
xhr.onload = function (e) {
|
||||||
|
if (xhr.status >= 200 && xhr.status < 300) {
|
||||||
|
resolve(xhr.response);
|
||||||
|
} else {
|
||||||
|
onFailure(e,
|
||||||
|
'Status '
|
||||||
|
+ String(xhr.status) + ' ' + String(xhr.statusText)
|
||||||
|
);
|
||||||
|
}
|
||||||
|
};
|
||||||
|
xhr.onerror = function (event) {
|
||||||
|
onFailure(e, 'Network error');
|
||||||
|
};
|
||||||
|
xhr.ontimeout = function (event){
|
||||||
|
xhr.timeout += 5000;
|
||||||
|
onFailure(null, 'Timeout (15s)', maxRetries=5);
|
||||||
|
};
|
||||||
|
xhr.send();
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
function debounce(func, wait, immediate) {
|
||||||
|
var timeout;
|
||||||
|
return function() {
|
||||||
|
var context = this;
|
||||||
|
var args = arguments;
|
||||||
|
var later = function() {
|
||||||
|
timeout = null;
|
||||||
|
if (!immediate) func.apply(context, args);
|
||||||
|
};
|
||||||
|
var callNow = immediate && !timeout;
|
||||||
|
clearTimeout(timeout);
|
||||||
|
timeout = setTimeout(later, wait);
|
||||||
|
if (callNow) func.apply(context, args);
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
function clamp(number, min, max) {
|
||||||
|
return Math.max(min, Math.min(number, max));
|
||||||
|
}
|
||||||
|
|
||||||
|
// allow to remove an event listener without having a function reference
|
||||||
|
function RegisteredEvent(obj, eventName, func) {
|
||||||
|
this.obj = obj;
|
||||||
|
this.eventName = eventName;
|
||||||
|
this.func = func;
|
||||||
|
obj.addEventListener(eventName, func);
|
||||||
|
}
|
||||||
|
RegisteredEvent.prototype.remove = function() {
|
||||||
|
this.obj.removeEventListener(this.eventName, this.func);
|
||||||
|
}
|
||||||
|
function addEvent(obj, eventName, func) {
|
||||||
|
return new RegisteredEvent(obj, eventName, func);
|
||||||
|
}
|
||||||
|
|
||||||
|
function reportWarning(...args){
|
||||||
|
console.warn(...args);
|
||||||
|
}
|
||||||
|
function reportError(...args){
|
||||||
|
console.error(...args);
|
||||||
|
}
|
||||||
|
function reportDebug(...args){
|
||||||
|
console.debug(...args);
|
||||||
|
}
|
||||||
|
|
||||||
|
function byteArrayToIntegerLittleEndian(unsignedByteArray){
|
||||||
|
var result = 0;
|
||||||
|
for (byte of unsignedByteArray){
|
||||||
|
result = result*256;
|
||||||
|
result += byte
|
||||||
|
}
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
function byteArrayToFloat(byteArray) {
|
||||||
|
var view = new DataView(byteArray.buffer);
|
||||||
|
if (byteArray.length == 4)
|
||||||
|
return view.getFloat32(byteArray.byteOffset);
|
||||||
|
else
|
||||||
|
return view.getFloat64(byteArray.byteOffset);
|
||||||
|
}
|
||||||
|
function ByteParser(data){
|
||||||
|
this.curIndex = 0;
|
||||||
|
this.data = new Uint8Array(data);
|
||||||
|
}
|
||||||
|
ByteParser.prototype.readInteger = function(nBytes){
|
||||||
|
var result = byteArrayToIntegerLittleEndian(
|
||||||
|
this.data.slice(this.curIndex, this.curIndex + nBytes)
|
||||||
|
);
|
||||||
|
this.curIndex += nBytes;
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
ByteParser.prototype.readBufferBytes = function(nBytes){
|
||||||
|
var result = this.data.slice(this.curIndex, this.curIndex + nBytes);
|
||||||
|
this.curIndex += nBytes;
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
|
||||||
|
// BEGIN iso-bmff-parser-stream/lib/box/sidx.js (modified)
|
||||||
|
// https://github.com/necccc/iso-bmff-parser-stream/blob/master/lib/box/sidx.js
|
||||||
|
/* The MIT License (MIT)
|
||||||
|
|
||||||
|
Copyright (c) 2014 Szabolcs Szabolcsi-Toth
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.*/
|
||||||
|
function sidx_parse (data, offset) {
|
||||||
|
var bp = new ByteParser(data),
|
||||||
|
version = bp.readInteger(1),
|
||||||
|
flags = bp.readInteger(3),
|
||||||
|
referenceId = bp.readInteger(4),
|
||||||
|
timeScale = bp.readInteger(4),
|
||||||
|
earliestPresentationTime = bp.readInteger(version === 0 ? 4 : 8),
|
||||||
|
firstOffset = bp.readInteger(4),
|
||||||
|
__reserved = bp.readInteger(2),
|
||||||
|
entryCount = bp.readInteger(2),
|
||||||
|
entries = [];
|
||||||
|
|
||||||
|
var totalBytesOffset = firstOffset + offset;
|
||||||
|
var totalTicks = 0;
|
||||||
|
for (var i = entryCount; i > 0; i=i-1 ) {
|
||||||
|
let referencedSize = bp.readInteger(4),
|
||||||
|
subSegmentDuration = bp.readInteger(4),
|
||||||
|
unused = bp.readBufferBytes(4)
|
||||||
|
entries.push({
|
||||||
|
referencedSize: referencedSize,
|
||||||
|
subSegmentDuration: subSegmentDuration,
|
||||||
|
unused: unused,
|
||||||
|
start: totalBytesOffset,
|
||||||
|
end: totalBytesOffset + referencedSize - 1, // inclusive
|
||||||
|
tickStart: totalTicks,
|
||||||
|
tickEnd: totalTicks + subSegmentDuration - 1,
|
||||||
|
requested: false,
|
||||||
|
have: false,
|
||||||
|
});
|
||||||
|
totalBytesOffset = totalBytesOffset + referencedSize;
|
||||||
|
totalTicks = totalTicks + subSegmentDuration;
|
||||||
|
}
|
||||||
|
|
||||||
|
return {
|
||||||
|
version: version,
|
||||||
|
flags: flags,
|
||||||
|
referenceId: referenceId,
|
||||||
|
timeScale: timeScale,
|
||||||
|
earliestPresentationTime: earliestPresentationTime,
|
||||||
|
firstOffset: firstOffset,
|
||||||
|
entries: entries
|
||||||
|
};
|
||||||
|
}
|
||||||
|
// END sidx.js
|
||||||
|
|
||||||
|
// BEGIN iso-bmff-parser-stream/lib/unbox.js (same license), modified
|
||||||
|
function unbox(buf) {
|
||||||
|
var bp = new ByteParser(buf),
|
||||||
|
bufferLength = buf.length,
|
||||||
|
length,
|
||||||
|
typeData,
|
||||||
|
boxData
|
||||||
|
|
||||||
|
length = bp.readInteger(4); // length of entire box,
|
||||||
|
typeData = bp.readInteger(4);
|
||||||
|
|
||||||
|
if (bufferLength - length < 0) {
|
||||||
|
reportWarning('Warning: sidx table is cut off');
|
||||||
|
return {
|
||||||
|
currentLength: bufferLength,
|
||||||
|
length: length,
|
||||||
|
type: typeData,
|
||||||
|
data: bp.readBufferBytes(bufferLength)
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
boxData = bp.readBufferBytes(length - 8);
|
||||||
|
|
||||||
|
return {
|
||||||
|
length: length,
|
||||||
|
type: typeData,
|
||||||
|
data: boxData
|
||||||
|
};
|
||||||
|
}
|
||||||
|
// END unbox.js
|
||||||
|
|
||||||
|
|
||||||
|
function extractWebmInitializationInfo(initializationSegment) {
|
||||||
|
var result = {
|
||||||
|
timeScale: null,
|
||||||
|
cuesOffset: null,
|
||||||
|
duration: null,
|
||||||
|
};
|
||||||
|
(new EbmlDecoder()).readTags(initializationSegment, (tagType, tag) => {
|
||||||
|
if (tag.name == 'TimecodeScale')
|
||||||
|
result.timeScale = byteArrayToIntegerLittleEndian(tag.data);
|
||||||
|
else if (tag.name == 'Duration')
|
||||||
|
// Integer represented as a float (why??); units of TimecodeScale
|
||||||
|
result.duration = byteArrayToFloat(tag.data);
|
||||||
|
// https://lists.matroska.org/pipermail/matroska-devel/2013-July/004549.html
|
||||||
|
// "CueClusterPosition in turn is relative to the segment's data start
|
||||||
|
// position" (the data start is the position after the bytes
|
||||||
|
// used to represent the tag ID and entry size)
|
||||||
|
else if (tagType == 'start' && tag.name == 'Segment')
|
||||||
|
result.cuesOffset = tag.dataStart;
|
||||||
|
});
|
||||||
|
if (result.timeScale === null) {
|
||||||
|
result.timeScale = 1000000;
|
||||||
|
}
|
||||||
|
|
||||||
|
// webm timecodeScale is the number of nanoseconds in a tick
|
||||||
|
// Convert it to number of ticks per second to match mp4 convention
|
||||||
|
result.timeScale = 10**9/result.timeScale;
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
function parseWebmCues(indexSegment, initInfo) {
|
||||||
|
var entries = [];
|
||||||
|
var currentEntry = {};
|
||||||
|
var cuesOffset = initInfo.cuesOffset;
|
||||||
|
(new EbmlDecoder()).readTags(indexSegment, (tagType, tag) => {
|
||||||
|
if (tag.name == 'CueTime') {
|
||||||
|
const tickStart = byteArrayToIntegerLittleEndian(tag.data);
|
||||||
|
currentEntry.tickStart = tickStart;
|
||||||
|
if (entries.length !== 0)
|
||||||
|
entries[entries.length - 1].tickEnd = tickStart - 1;
|
||||||
|
} else if (tag.name == 'CueClusterPosition') {
|
||||||
|
const byteStart = byteArrayToIntegerLittleEndian(tag.data);
|
||||||
|
currentEntry.start = cuesOffset + byteStart;
|
||||||
|
if (entries.length !== 0)
|
||||||
|
entries[entries.length - 1].end = cuesOffset + byteStart - 1;
|
||||||
|
} else if (tagType == 'end' && tag.name == 'CuePoint') {
|
||||||
|
entries.push(currentEntry);
|
||||||
|
currentEntry = {};
|
||||||
|
}
|
||||||
|
});
|
||||||
|
if (initInfo.duration)
|
||||||
|
entries[entries.length - 1].tickEnd = initInfo.duration - 1;
|
||||||
|
return entries;
|
||||||
|
}
|
||||||
|
|
||||||
|
// BEGIN node-ebml (modified) for parsing WEBM cues table
|
||||||
|
// https://github.com/node-ebml/node-ebml
|
||||||
|
|
||||||
|
/* Copyright (c) 2013-2018 Mark Schmale and contributors
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy of
|
||||||
|
this software and associated documentation files (the "Software"), to deal in
|
||||||
|
the Software without restriction, including without limitation the rights to
|
||||||
|
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
||||||
|
of the Software, and to permit persons to whom the Software is furnished to do
|
||||||
|
so, subject to the following conditions:
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.*/
|
||||||
|
|
||||||
|
const schema = new Map([
|
||||||
|
[0x18538067, ['Segment', 'm']],
|
||||||
|
[0x1c53bb6b, ['Cues', 'm']],
|
||||||
|
[0xbb, ['CuePoint', 'm']],
|
||||||
|
[0xb3, ['CueTime', 'u']],
|
||||||
|
[0xb7, ['CueTrackPositions', 'm']],
|
||||||
|
[0xf7, ['CueTrack', 'u']],
|
||||||
|
[0xf1, ['CueClusterPosition', 'u']],
|
||||||
|
[0x1549a966, ['Info', 'm']],
|
||||||
|
[0x2ad7b1, ['TimecodeScale', 'u']],
|
||||||
|
[0x4489, ['Duration', 'f']],
|
||||||
|
]);
|
||||||
|
|
||||||
|
|
||||||
|
function EbmlDecoder() {
|
||||||
|
this.buffer = null;
|
||||||
|
this.emit = null;
|
||||||
|
this.tagStack = [];
|
||||||
|
this.cursor = 0;
|
||||||
|
}
|
||||||
|
EbmlDecoder.prototype.readTags = function(chunk, onParsedTag) {
|
||||||
|
this.buffer = new Uint8Array(chunk);
|
||||||
|
this.emit = onParsedTag;
|
||||||
|
|
||||||
|
while (this.cursor < this.buffer.length) {
|
||||||
|
if (!this.readTag() || !this.readSize() || !this.readContent()) {
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
EbmlDecoder.prototype.getSchemaInfo = function(tag) {
|
||||||
|
if (Number.isInteger(tag) && schema.has(tag)) {
|
||||||
|
var name, type;
|
||||||
|
[name, type] = schema.get(tag);
|
||||||
|
return {name, type};
|
||||||
|
}
|
||||||
|
return {
|
||||||
|
type: null,
|
||||||
|
name: 'unknown',
|
||||||
|
};
|
||||||
|
}
|
||||||
|
EbmlDecoder.prototype.readTag = function() {
|
||||||
|
if (this.cursor >= this.buffer.length) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
|
const tag = readVint(this.buffer, this.cursor);
|
||||||
|
if (tag == null) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
|
const tagObj = {
|
||||||
|
tag: tag.value,
|
||||||
|
...this.getSchemaInfo(tag.valueWithLeading1),
|
||||||
|
start: this.cursor,
|
||||||
|
end: this.cursor + tag.length, // exclusive; also overwritten below
|
||||||
|
};
|
||||||
|
this.tagStack.push(tagObj);
|
||||||
|
|
||||||
|
this.cursor += tag.length;
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
EbmlDecoder.prototype.readSize = function() {
|
||||||
|
const tagObj = this.tagStack[this.tagStack.length - 1];
|
||||||
|
|
||||||
|
if (this.cursor >= this.buffer.length) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
|
const size = readVint(this.buffer, this.cursor);
|
||||||
|
if (size == null) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
|
tagObj.dataSize = size.value;
|
||||||
|
|
||||||
|
// unknown size
|
||||||
|
if (size.value === -1) {
|
||||||
|
tagObj.end = -1;
|
||||||
|
} else {
|
||||||
|
tagObj.end += size.value + size.length;
|
||||||
|
}
|
||||||
|
|
||||||
|
this.cursor += size.length;
|
||||||
|
tagObj.dataStart = this.cursor;
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
EbmlDecoder.prototype.readContent = function() {
|
||||||
|
const { type, dataSize, ...rest } = this.tagStack[
|
||||||
|
this.tagStack.length - 1
|
||||||
|
];
|
||||||
|
|
||||||
|
if (type === 'm') {
|
||||||
|
this.emit('start', { type, dataSize, ...rest });
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
|
||||||
|
if (this.buffer.length < this.cursor + dataSize) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
|
const data = this.buffer.subarray(this.cursor, this.cursor + dataSize);
|
||||||
|
this.cursor += dataSize;
|
||||||
|
|
||||||
|
this.tagStack.pop(); // remove the object from the stack
|
||||||
|
|
||||||
|
this.emit('tag', { type, dataSize, data, ...rest });
|
||||||
|
|
||||||
|
while (this.tagStack.length > 0) {
|
||||||
|
const topEle = this.tagStack[this.tagStack.length - 1];
|
||||||
|
if (this.cursor < topEle.end) {
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
this.emit('end', topEle);
|
||||||
|
this.tagStack.pop();
|
||||||
|
}
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
// user234683 notes: The matroska variable integer format is as follows:
|
||||||
|
// The first byte is where the length of the integer in bytes is determined.
|
||||||
|
// The number of bytes for the integer is equal to the number of leading
|
||||||
|
// zeroes in that first byte PLUS 1. Then there is a single 1 bit separator,
|
||||||
|
// and the rest of the bits in the first byte and the rest of the bits in
|
||||||
|
// the subsequent bytes are the value of the number. Note the 1-bit separator
|
||||||
|
// is not part of the value, but by convention IS included in the value for the
|
||||||
|
// EBML Tag IDs in the schema table above
|
||||||
|
// The byte-length includes the first byte. So one could also say the number
|
||||||
|
// of leading zeros is the number of subsequent bytes to include.
|
||||||
|
function readVint(buffer, start = 0) {
|
||||||
|
const length = 8 - Math.floor(Math.log2(buffer[start]));
|
||||||
|
|
||||||
|
if (start + length > buffer.length) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
let value = buffer[start] & ((1 << (8 - length)) - 1);
|
||||||
|
let valueWithLeading1 = buffer[start] & ((1 << (8 - length + 1)) - 1);
|
||||||
|
for (let i = 1; i < length; i += 1) {
|
||||||
|
// user234683 notes: Bails out with -1 (unknown) if the value would
|
||||||
|
// exceed 53 bits, which is the limit since JavaScript stores all
|
||||||
|
// numbers as floating points. See
|
||||||
|
// https://github.com/node-ebml/node-ebml/issues/49
|
||||||
|
if (i === 7) {
|
||||||
|
if (value >= 2 ** 8 && buffer[start + 7] > 0) {
|
||||||
|
return { length, value: -1, valueWithLeading1: -1 };
|
||||||
|
}
|
||||||
|
}
|
||||||
|
value *= 2 ** 8;
|
||||||
|
value += buffer[start + i];
|
||||||
|
valueWithLeading1 *= 2 ** 8;
|
||||||
|
valueWithLeading1 += buffer[start + i];
|
||||||
|
}
|
||||||
|
|
||||||
|
return { length, value, valueWithLeading1 };
|
||||||
|
}
|
||||||
|
// END node-ebml
|
||||||
20
youtube/static/js/comments.js
Normal file
20
youtube/static/js/comments.js
Normal file
@@ -0,0 +1,20 @@
|
|||||||
|
function onClickReplies(e) {
|
||||||
|
var details = e.target.parentElement;
|
||||||
|
// e.preventDefault();
|
||||||
|
console.log("loading replies ..");
|
||||||
|
doXhr(details.getAttribute("src") + "&slim=1", (html) => {
|
||||||
|
var div = details.querySelector(".comment_page");
|
||||||
|
div.innerHTML = html;
|
||||||
|
});
|
||||||
|
details.removeEventListener('click', onClickReplies);
|
||||||
|
}
|
||||||
|
|
||||||
|
window.addEventListener('DOMContentLoaded', function() {
|
||||||
|
QA("details.replies").forEach(details => {
|
||||||
|
details.addEventListener('click', onClickReplies);
|
||||||
|
details.addEventListener('auxclick', (e) => {
|
||||||
|
if (e.target.parentElement !== details) return;
|
||||||
|
if (e.button == 1) window.open(details.getAttribute("src"));
|
||||||
|
});
|
||||||
|
});
|
||||||
|
});
|
||||||
113
youtube/static/js/common.js
Normal file
113
youtube/static/js/common.js
Normal file
@@ -0,0 +1,113 @@
|
|||||||
|
Q = document.querySelector.bind(document);
|
||||||
|
QA = document.querySelectorAll.bind(document);
|
||||||
|
function text(msg) { return document.createTextNode(msg); }
|
||||||
|
function clearNode(node) { while (node.firstChild) node.removeChild(node.firstChild); }
|
||||||
|
function toTimestamp(seconds) {
|
||||||
|
var seconds = Math.floor(seconds);
|
||||||
|
|
||||||
|
var minutes = Math.floor(seconds/60);
|
||||||
|
var seconds = seconds % 60;
|
||||||
|
|
||||||
|
var hours = Math.floor(minutes/60);
|
||||||
|
var minutes = minutes % 60;
|
||||||
|
|
||||||
|
if (hours) {
|
||||||
|
return `0${hours}:`.slice(-3) + `0${minutes}:`.slice(-3) + `0${seconds}`.slice(-2);
|
||||||
|
}
|
||||||
|
return `0${minutes}:`.slice(-3) + `0${seconds}`.slice(-2);
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
var cur_track_idx = 0;
|
||||||
|
function getActiveTranscriptTrackIdx() {
|
||||||
|
let textTracks = Q("video").textTracks;
|
||||||
|
if (!textTracks.length) return;
|
||||||
|
for (let i=0; i < textTracks.length; i++) {
|
||||||
|
if (textTracks[i].mode == "showing") {
|
||||||
|
cur_track_idx = i;
|
||||||
|
return cur_track_idx;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return cur_track_idx;
|
||||||
|
}
|
||||||
|
function getActiveTranscriptTrack() { return Q("video").textTracks[getActiveTranscriptTrackIdx()]; }
|
||||||
|
|
||||||
|
function getDefaultTranscriptTrackIdx() {
|
||||||
|
let textTracks = Q("video").textTracks;
|
||||||
|
return textTracks.length - 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
function doXhr(url, callback=null) {
|
||||||
|
var xhr = new XMLHttpRequest();
|
||||||
|
xhr.open("GET", url);
|
||||||
|
xhr.onload = (e) => {
|
||||||
|
callback(e.currentTarget.response);
|
||||||
|
}
|
||||||
|
xhr.send();
|
||||||
|
return xhr;
|
||||||
|
}
|
||||||
|
|
||||||
|
// https://stackoverflow.com/a/30810322
|
||||||
|
function copyTextToClipboard(text) {
|
||||||
|
var textArea = document.createElement("textarea");
|
||||||
|
|
||||||
|
//
|
||||||
|
// *** This styling is an extra step which is likely not required. ***
|
||||||
|
//
|
||||||
|
// Why is it here? To ensure:
|
||||||
|
// 1. the element is able to have focus and selection.
|
||||||
|
// 2. if element was to flash render it has minimal visual impact.
|
||||||
|
// 3. less flakyness with selection and copying which **might** occur if
|
||||||
|
// the textarea element is not visible.
|
||||||
|
//
|
||||||
|
// The likelihood is the element won't even render, not even a
|
||||||
|
// flash, so some of these are just precautions. However in
|
||||||
|
// Internet Explorer the element is visible whilst the popup
|
||||||
|
// box asking the user for permission for the web page to
|
||||||
|
// copy to the clipboard.
|
||||||
|
//
|
||||||
|
|
||||||
|
// Place in top-left corner of screen regardless of scroll position.
|
||||||
|
textArea.style.position = 'fixed';
|
||||||
|
textArea.style.top = 0;
|
||||||
|
textArea.style.left = 0;
|
||||||
|
|
||||||
|
// Ensure it has a small width and height. Setting to 1px / 1em
|
||||||
|
// doesn't work as this gives a negative w/h on some browsers.
|
||||||
|
textArea.style.width = '2em';
|
||||||
|
textArea.style.height = '2em';
|
||||||
|
|
||||||
|
// We don't need padding, reducing the size if it does flash render.
|
||||||
|
textArea.style.padding = 0;
|
||||||
|
|
||||||
|
// Clean up any borders.
|
||||||
|
textArea.style.border = 'none';
|
||||||
|
textArea.style.outline = 'none';
|
||||||
|
textArea.style.boxShadow = 'none';
|
||||||
|
|
||||||
|
// Avoid flash of white box if rendered for any reason.
|
||||||
|
textArea.style.background = 'transparent';
|
||||||
|
|
||||||
|
|
||||||
|
textArea.value = text;
|
||||||
|
|
||||||
|
let parent_el = video.parentElement;
|
||||||
|
parent_el.appendChild(textArea);
|
||||||
|
textArea.focus();
|
||||||
|
textArea.select();
|
||||||
|
|
||||||
|
try {
|
||||||
|
var successful = document.execCommand('copy');
|
||||||
|
var msg = successful ? 'successful' : 'unsuccessful';
|
||||||
|
console.log('Copying text command was ' + msg);
|
||||||
|
} catch (err) {
|
||||||
|
console.log('Oops, unable to copy');
|
||||||
|
}
|
||||||
|
|
||||||
|
parent_el.removeChild(textArea);
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
window.addEventListener('DOMContentLoaded', function() {
|
||||||
|
cur_track_idx = getDefaultTranscriptTrackIdx();
|
||||||
|
});
|
||||||
56
youtube/static/js/hotkeys.js
Normal file
56
youtube/static/js/hotkeys.js
Normal file
@@ -0,0 +1,56 @@
|
|||||||
|
function onKeyDown(e) {
|
||||||
|
if (['INPUT', 'TEXTAREA'].includes(document.activeElement.tagName)) return false;
|
||||||
|
|
||||||
|
// console.log(e);
|
||||||
|
let v = Q("video");
|
||||||
|
if (!e.isTrusted) return; // plyr CustomEvent
|
||||||
|
let c = e.key.toLowerCase();
|
||||||
|
if (e.ctrlKey) return;
|
||||||
|
else if (c == "k") {
|
||||||
|
v.paused ? v.play() : v.pause();
|
||||||
|
}
|
||||||
|
else if (c == "arrowleft") {
|
||||||
|
e.preventDefault();
|
||||||
|
v.currentTime = v.currentTime - 5;
|
||||||
|
}
|
||||||
|
else if (c == "arrowright") {
|
||||||
|
e.preventDefault();
|
||||||
|
v.currentTime = v.currentTime + 5;
|
||||||
|
}
|
||||||
|
else if (c == "j") {
|
||||||
|
e.preventDefault();
|
||||||
|
v.currentTime = v.currentTime - 10;
|
||||||
|
}
|
||||||
|
else if (c == "l") {
|
||||||
|
e.preventDefault();
|
||||||
|
v.currentTime = v.currentTime + 10;
|
||||||
|
}
|
||||||
|
else if (c == "f") {
|
||||||
|
e.preventDefault();
|
||||||
|
if (data.settings.video_player == 1)
|
||||||
|
player.fullscreen.toggle()
|
||||||
|
else {
|
||||||
|
if (document.fullscreen) document.exitFullscreen();
|
||||||
|
else v.requestFullscreen();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
else if (c == "c") {
|
||||||
|
e.preventDefault();
|
||||||
|
if (data.settings.video_player == 1)
|
||||||
|
player.toggleCaptions();
|
||||||
|
else {
|
||||||
|
let tt = getActiveTranscriptTrack();
|
||||||
|
if (tt == null) return;
|
||||||
|
if (tt.mode == "showing") tt.mode = "disabled";
|
||||||
|
else tt.mode = "showing";
|
||||||
|
}
|
||||||
|
}
|
||||||
|
else if (c == "t") {
|
||||||
|
let ts = Math.floor(Q("video").currentTime);
|
||||||
|
copyTextToClipboard(`https://youtu.be/${data.video_id}?t=${ts}`);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
window.addEventListener('DOMContentLoaded', function() {
|
||||||
|
document.addEventListener('keydown', onKeyDown);
|
||||||
|
});
|
||||||
145
youtube/static/js/plyr-start.js
Normal file
145
youtube/static/js/plyr-start.js
Normal file
@@ -0,0 +1,145 @@
|
|||||||
|
var captionsActive;
|
||||||
|
if(data.settings.subtitles_mode == 2)
|
||||||
|
captionsActive = true;
|
||||||
|
else if(data.settings.subtitles_mode == 1 && data.has_manual_captions)
|
||||||
|
captionsActive = true;
|
||||||
|
else
|
||||||
|
captionsActive = false;
|
||||||
|
|
||||||
|
var qualityOptions = [];
|
||||||
|
var qualityDefault;
|
||||||
|
for (var src of data['uni_sources']) {
|
||||||
|
qualityOptions.push(src.quality_string)
|
||||||
|
}
|
||||||
|
for (var src of data['pair_sources']) {
|
||||||
|
qualityOptions.push(src.quality_string)
|
||||||
|
}
|
||||||
|
if (data['using_pair_sources'])
|
||||||
|
qualityDefault = data['pair_sources'][data['pair_idx']].quality_string;
|
||||||
|
else if (data['uni_sources'].length != 0)
|
||||||
|
qualityDefault = data['uni_sources'][data['uni_idx']].quality_string;
|
||||||
|
else
|
||||||
|
qualityDefault = 'None';
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
// Fix plyr refusing to work with qualities that are strings
|
||||||
|
Object.defineProperty(Plyr.prototype, 'quality', {
|
||||||
|
set: function(input) {
|
||||||
|
const config = this.config.quality;
|
||||||
|
const options = this.options.quality;
|
||||||
|
|
||||||
|
if (!options.length) {
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
|
||||||
|
// removing this line:
|
||||||
|
//let quality = [!is.empty(input) && Number(input), this.storage.get('quality'), config.selected, config.default].find(is.number);
|
||||||
|
// replacing with:
|
||||||
|
quality = input;
|
||||||
|
let updateStorage = true;
|
||||||
|
|
||||||
|
if (!options.includes(quality)) {
|
||||||
|
// Plyr sets quality to null at startup, resulting in the erroneous
|
||||||
|
// calling of this setter function with input = null, and the
|
||||||
|
// commented out code below would set the quality to something
|
||||||
|
// unrelated at startup. Comment out and just return.
|
||||||
|
return;
|
||||||
|
/*const value = closest(options, quality);
|
||||||
|
this.debug.warn(`Unsupported quality option: ${quality}, using ${value} instead`);
|
||||||
|
quality = value; // Don't update storage if quality is not supported
|
||||||
|
|
||||||
|
updateStorage = false;*/
|
||||||
|
} // Update config
|
||||||
|
|
||||||
|
|
||||||
|
config.selected = quality; // Set quality
|
||||||
|
|
||||||
|
this.media.quality = quality; // Save to storage
|
||||||
|
|
||||||
|
if (updateStorage) {
|
||||||
|
this.storage.set({
|
||||||
|
quality
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
const playerOptions = {
|
||||||
|
disableContextMenu: false,
|
||||||
|
captions: {
|
||||||
|
active: captionsActive,
|
||||||
|
language: data.settings.subtitles_language,
|
||||||
|
},
|
||||||
|
controls: [
|
||||||
|
'play-large',
|
||||||
|
'play',
|
||||||
|
'progress',
|
||||||
|
'current-time',
|
||||||
|
'duration',
|
||||||
|
'mute',
|
||||||
|
'volume',
|
||||||
|
'captions',
|
||||||
|
'settings',
|
||||||
|
'fullscreen',
|
||||||
|
],
|
||||||
|
iconUrl: "/youtube.com/static/modules/plyr/plyr.svg",
|
||||||
|
blankVideo: "/youtube.com/static/modules/plyr/blank.webm",
|
||||||
|
debug: false,
|
||||||
|
storage: {enabled: false},
|
||||||
|
// disable plyr hotkeys in favor of hotkeys.js
|
||||||
|
keyboard: {
|
||||||
|
focused: false,
|
||||||
|
global: false,
|
||||||
|
},
|
||||||
|
quality: {
|
||||||
|
default: qualityDefault,
|
||||||
|
options: qualityOptions,
|
||||||
|
forced: true,
|
||||||
|
onChange: function(quality) {
|
||||||
|
if (quality == 'None')
|
||||||
|
return;
|
||||||
|
if (quality.includes('(integrated)')) {
|
||||||
|
for (var i=0; i < data['uni_sources'].length; i++) {
|
||||||
|
if (data['uni_sources'][i].quality_string == quality) {
|
||||||
|
changeQuality({'type': 'uni', 'index': i});
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
for (var i=0; i < data['pair_sources'].length; i++) {
|
||||||
|
if (data['pair_sources'][i].quality_string == quality) {
|
||||||
|
changeQuality({'type': 'pair', 'index': i});
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
},
|
||||||
|
previewThumbnails: {
|
||||||
|
enabled: storyboard_url != null,
|
||||||
|
src: [storyboard_url],
|
||||||
|
},
|
||||||
|
settings: ['captions', 'quality', 'speed', 'loop'],
|
||||||
|
}
|
||||||
|
|
||||||
|
// if the value set by user is -1, the volume option is omitted, as it only accepts value b/w 0 and 1
|
||||||
|
// https://github.com/sampotts/plyr#options
|
||||||
|
if (data.settings.default_volume !== -1) {
|
||||||
|
playerOptions.volume = data.settings.default_volume / 100;
|
||||||
|
}
|
||||||
|
|
||||||
|
const player = new Plyr(document.querySelector('video'), playerOptions);
|
||||||
|
|
||||||
|
// disable double click to fullscreen
|
||||||
|
// https://github.com/sampotts/plyr/issues/1370#issuecomment-528966795
|
||||||
|
player.eventListeners.forEach(function(eventListener) {
|
||||||
|
if(eventListener.type === 'dblclick') {
|
||||||
|
eventListener.element.removeEventListener(eventListener.type, eventListener.callback, eventListener.options);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
// Add .started property, true after the playback has been started
|
||||||
|
// Needed so controls won't be hidden before playback has started
|
||||||
|
player.started = false;
|
||||||
|
player.once('playing', function(){this.started = true});
|
||||||
40
youtube/static/js/sponsorblock.js
Normal file
40
youtube/static/js/sponsorblock.js
Normal file
@@ -0,0 +1,40 @@
|
|||||||
|
"use strict";
|
||||||
|
|
||||||
|
// from: https://git.gir.st/subscriptionfeed.git/blob/59a590d:/app/youtube/templates/watch.html.j2#l28
|
||||||
|
|
||||||
|
var sha256=function a(b){function c(a,b){return a>>>b|a<<32-b}for(var d,e,f=Math.pow,g=f(2,32),h="length",i="",j=[],k=8*b[h],l=a.h=a.h||[],m=a.k=a.k||[],n=m[h],o={},p=2;64>n;p++)if(!o[p]){for(d=0;313>d;d+=p)o[d]=p;l[n]=f(p,.5)*g|0,m[n++]=f(p,1/3)*g|0}for(b+="\x80";b[h]%64-56;)b+="\x00";for(d=0;d<b[h];d++){if(e=b.charCodeAt(d),e>>8)return;j[d>>2]|=e<<(3-d)%4*8}for(j[j[h]]=k/g|0,j[j[h]]=k,e=0;e<j[h];){var q=j.slice(e,e+=16),r=l;for(l=l.slice(0,8),d=0;64>d;d++){var s=q[d-15],t=q[d-2],u=l[0],v=l[4],w=l[7]+(c(v,6)^c(v,11)^c(v,25))+(v&l[5]^~v&l[6])+m[d]+(q[d]=16>d?q[d]:q[d-16]+(c(s,7)^c(s,18)^s>>>3)+q[d-7]+(c(t,17)^c(t,19)^t>>>10)|0),x=(c(u,2)^c(u,13)^c(u,22))+(u&l[1]^u&l[2]^l[1]&l[2]);l=[w+x|0].concat(l),l[4]=l[4]+w|0}for(d=0;8>d;d++)l[d]=l[d]+r[d]|0}for(d=0;8>d;d++)for(e=3;e+1;e--){var y=l[d]>>8*e&255;i+=(16>y?0:"")+y.toString(16)}return i}; /*https://geraintluff.github.io/sha256/sha256.min.js (public domain)*/
|
||||||
|
|
||||||
|
window.addEventListener("load", load_sponsorblock);
|
||||||
|
document.addEventListener('DOMContentLoaded', ()=>{
|
||||||
|
const check = document.querySelector("#skip_sponsors");
|
||||||
|
check.addEventListener("change", () => {if (check.checked) load_sponsorblock()});
|
||||||
|
});
|
||||||
|
function load_sponsorblock(){
|
||||||
|
const info_elem = Q('#skip_n');
|
||||||
|
if (info_elem.innerText.length) return; // already fetched
|
||||||
|
const hash = sha256(data.video_id).substr(0,4);
|
||||||
|
const video_obj = Q("video");
|
||||||
|
let url = `/https://sponsor.ajay.app/api/skipSegments/${hash}`;
|
||||||
|
fetch(url)
|
||||||
|
.then(response => response.json())
|
||||||
|
.then(r => {
|
||||||
|
for (const video of r) {
|
||||||
|
if (video.videoID != data.video_id) continue;
|
||||||
|
info_elem.innerText = `(${video.segments.length} segments)`;
|
||||||
|
const cat_n = video.segments.map(e=>e.category).sort()
|
||||||
|
.reduce((acc,e) => (acc[e]=(acc[e]||0)+1, acc), {});
|
||||||
|
info_elem.title = Object.entries(cat_n).map(e=>e.join(': ')).join(', ');
|
||||||
|
for (const segment of video.segments) {
|
||||||
|
const [start, stop] = segment.segment;
|
||||||
|
if (segment.category != "sponsor") continue;
|
||||||
|
video_obj.addEventListener("timeupdate", function() {
|
||||||
|
if (Q("#skip_sponsors").checked &&
|
||||||
|
this.currentTime >= start &&
|
||||||
|
this.currentTime < stop-1) {
|
||||||
|
this.currentTime = stop;
|
||||||
|
}
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
});
|
||||||
|
}
|
||||||
151
youtube/static/js/transcript-table.js
Normal file
151
youtube/static/js/transcript-table.js
Normal file
@@ -0,0 +1,151 @@
|
|||||||
|
var details_tt, select_tt, table_tt;
|
||||||
|
|
||||||
|
function renderCues() {
|
||||||
|
var selectedTrack = Q("video").textTracks[select_tt.selectedIndex];
|
||||||
|
let cuesList = [...selectedTrack.cues];
|
||||||
|
var is_automatic = cuesList[0].text.startsWith(" \n");
|
||||||
|
|
||||||
|
// Firefox ignores cues starting with a blank line containing a space
|
||||||
|
// Automatic captions contain such a blank line in the first cue
|
||||||
|
let ff_bug = false;
|
||||||
|
if (!cuesList[0].text.length) { ff_bug = true; is_automatic = true };
|
||||||
|
let rows;
|
||||||
|
|
||||||
|
function forEachCue(callback) {
|
||||||
|
for (let i=0; i < cuesList.length; i++) {
|
||||||
|
let txt, startTime = selectedTrack.cues[i].startTime;
|
||||||
|
if (is_automatic) {
|
||||||
|
// Automatic captions repeat content. The new segment is displayed
|
||||||
|
// on the bottom row; the old one is displayed on the top row.
|
||||||
|
// So grab the bottom row only. Skip every other cue because the bottom
|
||||||
|
// row is empty.
|
||||||
|
if (i % 2) continue;
|
||||||
|
if (ff_bug && !selectedTrack.cues[i].text.length) {
|
||||||
|
txt = selectedTrack.cues[i+1].text;
|
||||||
|
} else {
|
||||||
|
txt = selectedTrack.cues[i].text.split('\n')[1].replace(/<[\d:.]*?><c>(.*?)<\/c>/g, "$1");
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
txt = selectedTrack.cues[i].text;
|
||||||
|
}
|
||||||
|
callback(startTime, txt);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
function createTimestampLink(startTime, txt, title=null) {
|
||||||
|
a = document.createElement("a");
|
||||||
|
a.appendChild(text(txt));
|
||||||
|
a.href = "javascript:;"; // TODO: replace this with ?t parameter
|
||||||
|
if (title) a.title = title;
|
||||||
|
a.addEventListener("click", (e) => {
|
||||||
|
Q("video").currentTime = startTime;
|
||||||
|
})
|
||||||
|
return a;
|
||||||
|
}
|
||||||
|
|
||||||
|
clearNode(table_tt);
|
||||||
|
console.log("render cues..", selectedTrack.cues.length);
|
||||||
|
if (Q("input#transcript-use-table").checked) {
|
||||||
|
forEachCue((startTime, txt) => {
|
||||||
|
let tr, td, a;
|
||||||
|
tr = document.createElement("tr");
|
||||||
|
|
||||||
|
td = document.createElement("td")
|
||||||
|
td.appendChild(createTimestampLink(startTime, toTimestamp(startTime)));
|
||||||
|
tr.appendChild(td);
|
||||||
|
|
||||||
|
td = document.createElement("td")
|
||||||
|
td.appendChild(text(txt));
|
||||||
|
tr.appendChild(td);
|
||||||
|
|
||||||
|
table_tt.appendChild(tr);
|
||||||
|
});
|
||||||
|
rows = table_tt.rows;
|
||||||
|
}
|
||||||
|
else {
|
||||||
|
forEachCue((startTime, txt) => {
|
||||||
|
span = document.createElement("span");
|
||||||
|
var idx = txt.indexOf(" ", 1);
|
||||||
|
var [firstWord, rest] = [txt.slice(0, idx), txt.slice(idx)];
|
||||||
|
|
||||||
|
span.appendChild(createTimestampLink(startTime, firstWord, toTimestamp(startTime)));
|
||||||
|
if (rest) span.appendChild(text(rest + " "));
|
||||||
|
table_tt.appendChild(span);
|
||||||
|
});
|
||||||
|
rows = table_tt.childNodes;
|
||||||
|
}
|
||||||
|
|
||||||
|
var lastActiveRow = null;
|
||||||
|
function colorCurRow(e) {
|
||||||
|
// console.log("cuechange:", e);
|
||||||
|
var activeCueIdx = cuesList.findIndex((c) => c == selectedTrack.activeCues[0]);
|
||||||
|
var activeRowIdx = is_automatic ? Math.floor(activeCueIdx / 2) : activeCueIdx;
|
||||||
|
|
||||||
|
if (lastActiveRow) lastActiveRow.style.backgroundColor = "";
|
||||||
|
if (activeRowIdx < 0) return;
|
||||||
|
var row = rows[activeRowIdx];
|
||||||
|
row.style.backgroundColor = "#0cc12e42";
|
||||||
|
lastActiveRow = row;
|
||||||
|
}
|
||||||
|
colorCurRow();
|
||||||
|
selectedTrack.addEventListener("cuechange", colorCurRow);
|
||||||
|
}
|
||||||
|
|
||||||
|
function loadCues() {
|
||||||
|
let textTracks = Q("video").textTracks;
|
||||||
|
let selectedTrack = textTracks[select_tt.selectedIndex];
|
||||||
|
|
||||||
|
// See https://developer.mozilla.org/en-US/docs/Web/API/TextTrack/mode
|
||||||
|
// This code will (I think) make sure that the selected track's cues
|
||||||
|
// are loaded even if the track subtitles aren't on (showing). Setting it
|
||||||
|
// to hidden will load them.
|
||||||
|
let selected_track_target_mode = "hidden";
|
||||||
|
|
||||||
|
for (let track of textTracks) {
|
||||||
|
// Want to avoid unshowing selected track if it's showing
|
||||||
|
if (track.mode === "showing") selected_track_target_mode = "showing";
|
||||||
|
|
||||||
|
if (track !== selectedTrack) track.mode = "disabled";
|
||||||
|
}
|
||||||
|
if (selectedTrack.mode == "disabled") {
|
||||||
|
selectedTrack.mode = selected_track_target_mode;
|
||||||
|
}
|
||||||
|
|
||||||
|
var intervalID = setInterval(() => {
|
||||||
|
if (selectedTrack.cues && selectedTrack.cues.length) {
|
||||||
|
clearInterval(intervalID);
|
||||||
|
renderCues();
|
||||||
|
}
|
||||||
|
}, 100);
|
||||||
|
}
|
||||||
|
|
||||||
|
window.addEventListener('DOMContentLoaded', function() {
|
||||||
|
let textTracks = Q("video").textTracks;
|
||||||
|
if (!textTracks.length) return;
|
||||||
|
|
||||||
|
details_tt = Q("details#transcript-details");
|
||||||
|
details_tt.addEventListener("toggle", () => {
|
||||||
|
if (details_tt.open) loadCues();
|
||||||
|
});
|
||||||
|
|
||||||
|
select_tt = Q("select#select-tt");
|
||||||
|
select_tt.selectedIndex = getDefaultTranscriptTrackIdx();
|
||||||
|
select_tt.addEventListener("change", loadCues);
|
||||||
|
|
||||||
|
table_tt = Q("table#transcript-table");
|
||||||
|
table_tt.appendChild(text("loading.."));
|
||||||
|
|
||||||
|
textTracks.addEventListener("change", (e) => {
|
||||||
|
// console.log(e);
|
||||||
|
var idx = getActiveTranscriptTrackIdx(); // sadly not provided by 'e'
|
||||||
|
if (textTracks[idx].mode == "showing") {
|
||||||
|
select_tt.selectedIndex = idx;
|
||||||
|
loadCues();
|
||||||
|
}
|
||||||
|
else if (details_tt.open && textTracks[idx].mode == "disabled") {
|
||||||
|
textTracks[idx].mode = "hidden"; // so we still receive 'oncuechange'
|
||||||
|
}
|
||||||
|
})
|
||||||
|
|
||||||
|
Q("input#transcript-use-table").addEventListener("change", renderCues);
|
||||||
|
});
|
||||||
214
youtube/static/js/watch.js
Normal file
214
youtube/static/js/watch.js
Normal file
@@ -0,0 +1,214 @@
|
|||||||
|
var video = document.querySelector('video');
|
||||||
|
|
||||||
|
function setVideoDimensions(height, width){
|
||||||
|
var body = document.querySelector('body');
|
||||||
|
body.style.setProperty('--video_height', String(height));
|
||||||
|
body.style.setProperty('--video_width', String(width));
|
||||||
|
if (height < 240)
|
||||||
|
body.style.setProperty('--plyr-control-spacing-num', '3');
|
||||||
|
else
|
||||||
|
body.style.setProperty('--plyr-control-spacing-num', '10');
|
||||||
|
var theaterWidth = Math.max(640, data['video_duration'] || 0, width);
|
||||||
|
body.style.setProperty('--theater_video_target_width', String(theaterWidth));
|
||||||
|
|
||||||
|
// This will set the correct media query
|
||||||
|
document.querySelector('#video-container').className = 'h' + height;
|
||||||
|
}
|
||||||
|
function changeQuality(selection) {
|
||||||
|
var currentVideoTime = video.currentTime;
|
||||||
|
var videoPaused = video.paused;
|
||||||
|
var videoSpeed = video.playbackRate;
|
||||||
|
var srcInfo;
|
||||||
|
if (avMerge)
|
||||||
|
avMerge.close();
|
||||||
|
if (selection.type == 'uni'){
|
||||||
|
srcInfo = data['uni_sources'][selection.index];
|
||||||
|
video.src = srcInfo.url;
|
||||||
|
} else {
|
||||||
|
srcInfo = data['pair_sources'][selection.index];
|
||||||
|
avMerge = new AVMerge(video, srcInfo, currentVideoTime);
|
||||||
|
}
|
||||||
|
setVideoDimensions(srcInfo.height, srcInfo.width);
|
||||||
|
video.currentTime = currentVideoTime;
|
||||||
|
if (!videoPaused){
|
||||||
|
video.play();
|
||||||
|
}
|
||||||
|
video.playbackRate = videoSpeed;
|
||||||
|
}
|
||||||
|
|
||||||
|
// Initialize av-merge
|
||||||
|
var avMerge;
|
||||||
|
if (data.using_pair_sources) {
|
||||||
|
var srcPair = data['pair_sources'][data['pair_idx']];
|
||||||
|
avMerge = new AVMerge(video, srcPair, 0);
|
||||||
|
}
|
||||||
|
|
||||||
|
// Quality selector
|
||||||
|
var qualitySelector = document.querySelector('#quality-select')
|
||||||
|
if (qualitySelector)
|
||||||
|
qualitySelector.addEventListener(
|
||||||
|
'change', function(e) {
|
||||||
|
changeQuality(JSON.parse(this.value))
|
||||||
|
}
|
||||||
|
);
|
||||||
|
|
||||||
|
// Set up video start time from &t parameter
|
||||||
|
if (data.time_start != 0 && video)
|
||||||
|
video.currentTime = data.time_start;
|
||||||
|
|
||||||
|
// External video speed control
|
||||||
|
var speedInput = document.querySelector('#speed-control');
|
||||||
|
speedInput.addEventListener('keyup', (event) => {
|
||||||
|
if (event.key === 'Enter') {
|
||||||
|
var speed = parseFloat(speedInput.value);
|
||||||
|
if(!isNaN(speed)){
|
||||||
|
video.playbackRate = speed;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
|
||||||
|
// Playlist lazy image loading
|
||||||
|
if (data.playlist && data.playlist['id'] !== null) {
|
||||||
|
// lazy load playlist images
|
||||||
|
// copied almost verbatim from
|
||||||
|
// https://css-tricks.com/tips-for-rolling-your-own-lazy-loading/
|
||||||
|
// IntersectionObserver isn't supported in pre-quantum
|
||||||
|
// firefox versions, but the alternative of making it
|
||||||
|
// manually is a performance drain, so oh well
|
||||||
|
var observer = new IntersectionObserver(lazyLoad, {
|
||||||
|
|
||||||
|
// where in relation to the edge of the viewport, we are observing
|
||||||
|
rootMargin: "100px",
|
||||||
|
|
||||||
|
// how much of the element needs to have intersected
|
||||||
|
// in order to fire our loading function
|
||||||
|
threshold: 1.0
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
function lazyLoad(elements) {
|
||||||
|
elements.forEach(item => {
|
||||||
|
if (item.intersectionRatio > 0) {
|
||||||
|
|
||||||
|
// set the src attribute to trigger a load
|
||||||
|
item.target.src = item.target.dataset.src;
|
||||||
|
|
||||||
|
// stop observing this element. Our work here is done!
|
||||||
|
observer.unobserve(item.target);
|
||||||
|
};
|
||||||
|
});
|
||||||
|
};
|
||||||
|
|
||||||
|
// Tell our observer to observe all img elements with a "lazy" class
|
||||||
|
var lazyImages = document.querySelectorAll('img.lazy');
|
||||||
|
lazyImages.forEach(img => {
|
||||||
|
observer.observe(img);
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
// Autoplay
|
||||||
|
if (data.settings.related_videos_mode !== 0 || data.playlist !== null) {
|
||||||
|
let playability_error = !!data.playability_error;
|
||||||
|
let isPlaylist = false;
|
||||||
|
if (data.playlist !== null && data.playlist['current_index'] !== null)
|
||||||
|
isPlaylist = true;
|
||||||
|
|
||||||
|
// read cookies on whether to autoplay
|
||||||
|
// https://developer.mozilla.org/en-US/docs/Web/API/Document/cookie
|
||||||
|
let cookieValue;
|
||||||
|
let playlist_id;
|
||||||
|
if (isPlaylist) {
|
||||||
|
// from https://stackoverflow.com/a/6969486
|
||||||
|
function escapeRegExp(string) {
|
||||||
|
// $& means the whole matched string
|
||||||
|
return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&');
|
||||||
|
}
|
||||||
|
playlist_id = data.playlist['id'];
|
||||||
|
playlist_id = escapeRegExp(playlist_id);
|
||||||
|
|
||||||
|
cookieValue = document.cookie.replace(new RegExp(
|
||||||
|
'(?:(?:^|.*;\\s*)autoplay_'
|
||||||
|
+ playlist_id + '\\s*\\=\\s*([^;]*).*$)|^.*$'
|
||||||
|
), '$1');
|
||||||
|
} else {
|
||||||
|
cookieValue = document.cookie.replace(new RegExp(
|
||||||
|
'(?:(?:^|.*;\\s*)autoplay\\s*\\=\\s*([^;]*).*$)|^.*$'
|
||||||
|
),'$1');
|
||||||
|
}
|
||||||
|
|
||||||
|
let autoplayEnabled = 0;
|
||||||
|
if(cookieValue.length === 0){
|
||||||
|
autoplayEnabled = 0;
|
||||||
|
} else {
|
||||||
|
autoplayEnabled = Number(cookieValue);
|
||||||
|
}
|
||||||
|
|
||||||
|
// check the checkbox if autoplay is on
|
||||||
|
let checkbox = document.querySelector('#autoplay-toggle');
|
||||||
|
if(autoplayEnabled){
|
||||||
|
checkbox.checked = true;
|
||||||
|
}
|
||||||
|
|
||||||
|
// listen for checkbox to turn autoplay on and off
|
||||||
|
let cookie = 'autoplay'
|
||||||
|
if (isPlaylist)
|
||||||
|
cookie += '_' + playlist_id;
|
||||||
|
|
||||||
|
checkbox.addEventListener( 'change', function() {
|
||||||
|
if(this.checked) {
|
||||||
|
autoplayEnabled = 1;
|
||||||
|
document.cookie = cookie + '=1; SameSite=Strict';
|
||||||
|
} else {
|
||||||
|
autoplayEnabled = 0;
|
||||||
|
document.cookie = cookie + '=0; SameSite=Strict';
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
if(!playability_error){
|
||||||
|
// play the video if autoplay is on
|
||||||
|
if(autoplayEnabled){
|
||||||
|
video.play();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// determine next video url
|
||||||
|
let nextVideoUrl;
|
||||||
|
if (isPlaylist) {
|
||||||
|
let currentIndex = data.playlist['current_index'];
|
||||||
|
if (data.playlist['current_index']+1 == data.playlist['items'].length)
|
||||||
|
nextVideoUrl = null;
|
||||||
|
else
|
||||||
|
nextVideoUrl = data.playlist['items'][data.playlist['current_index']+1]['url'];
|
||||||
|
|
||||||
|
// scroll playlist to proper position
|
||||||
|
// item height + gap == 100
|
||||||
|
let pl = document.querySelector('.playlist-videos');
|
||||||
|
pl.scrollTop = 100*currentIndex;
|
||||||
|
} else {
|
||||||
|
if (data.related.length === 0)
|
||||||
|
nextVideoUrl = null;
|
||||||
|
else
|
||||||
|
nextVideoUrl = data.related[0]['url'];
|
||||||
|
}
|
||||||
|
let nextVideoDelay = 1000;
|
||||||
|
|
||||||
|
// go to next video when video ends
|
||||||
|
// https://stackoverflow.com/a/2880950
|
||||||
|
if (nextVideoUrl) {
|
||||||
|
if(playability_error){
|
||||||
|
videoEnded();
|
||||||
|
} else {
|
||||||
|
video.addEventListener('ended', videoEnded, false);
|
||||||
|
}
|
||||||
|
function nextVideo(){
|
||||||
|
if(autoplayEnabled){
|
||||||
|
window.location.href = nextVideoUrl;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
function videoEnded(e) {
|
||||||
|
window.setTimeout(nextVideo, nextVideoDelay);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
21
youtube/static/light_theme.css
Normal file
21
youtube/static/light_theme.css
Normal file
@@ -0,0 +1,21 @@
|
|||||||
|
body{
|
||||||
|
--interface-color: #ffffff;
|
||||||
|
--text-color: #222222;
|
||||||
|
--background-color: #f8f8f8;
|
||||||
|
--video-background-color: #ffffff;
|
||||||
|
--link-color-rgb: 0, 0, 238;
|
||||||
|
--visited-link-color-rgb: 85, 26, 139;
|
||||||
|
}
|
||||||
|
|
||||||
|
.comment .permalink{
|
||||||
|
color: #000000;
|
||||||
|
}
|
||||||
|
|
||||||
|
.setting-item{
|
||||||
|
background-color: #f8f8f8;
|
||||||
|
}
|
||||||
|
|
||||||
|
.muted{
|
||||||
|
background-color: #888888;
|
||||||
|
}
|
||||||
|
|
||||||
BIN
youtube/static/modules/plyr/blank.webm
Normal file
BIN
youtube/static/modules/plyr/blank.webm
Normal file
Binary file not shown.
23
youtube/static/modules/plyr/build-instructions.md
Normal file
23
youtube/static/modules/plyr/build-instructions.md
Normal file
@@ -0,0 +1,23 @@
|
|||||||
|
# Build steps for Plyr (3.6.8)
|
||||||
|
|
||||||
|
Tested on Debian.
|
||||||
|
|
||||||
|
First install yarn (Javascript package manager). Instructions [here](https://classic.yarnpkg.com/en/docs/install/).
|
||||||
|
|
||||||
|
Clone the repo to a location of your choosing:
|
||||||
|
```
|
||||||
|
git clone https://github.com/sampotts/plyr.git
|
||||||
|
cd plyr
|
||||||
|
```
|
||||||
|
|
||||||
|
Install Plyr's dependencies:
|
||||||
|
```
|
||||||
|
yarn install
|
||||||
|
```
|
||||||
|
|
||||||
|
Build with gulp (which was hopefully installed by yarn):
|
||||||
|
```
|
||||||
|
gulp build
|
||||||
|
```
|
||||||
|
|
||||||
|
plyr.js and other files will be in the `dist` directory.
|
||||||
1
youtube/static/modules/plyr/plyr.css
Normal file
1
youtube/static/modules/plyr/plyr.css
Normal file
File diff suppressed because one or more lines are too long
8619
youtube/static/modules/plyr/plyr.js
Normal file
8619
youtube/static/modules/plyr/plyr.js
Normal file
File diff suppressed because it is too large
Load Diff
1
youtube/static/modules/plyr/plyr.svg
Normal file
1
youtube/static/modules/plyr/plyr.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 5.6 KiB |
59
youtube/static/plyr_fixes.css
Normal file
59
youtube/static/plyr_fixes.css
Normal file
@@ -0,0 +1,59 @@
|
|||||||
|
body{
|
||||||
|
--plyr-control-spacing: calc(var(--plyr-control-spacing-num)*1px);
|
||||||
|
--plyr-video-controls-background: rgba(0,0,0,0.8);
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Scale captions with video height, not page width. Scale down to a minimum
|
||||||
|
of 10px so it does not become unreadable, rather than scaling
|
||||||
|
exactly proportional to video height */
|
||||||
|
.plyr__captions {
|
||||||
|
font-size: calc(18px + 8px*(var(--video_height) - 720)/720) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
/* make buffered progress more visible */
|
||||||
|
.plyr--video .plyr__progress__buffer{
|
||||||
|
color: rgba(255,255,255,0.75) !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Avoid visual jumps and flashes as plyr loads */
|
||||||
|
.plyr audio, .plyr iframe, .plyr video{
|
||||||
|
width: 100% !important;
|
||||||
|
height: 100% !important;
|
||||||
|
}
|
||||||
|
.plyr__video-wrapper{
|
||||||
|
height: 100% !important;
|
||||||
|
width: 100% !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Prevent this div from blocking right-click menu for video
|
||||||
|
e.g. Firefox playback speed options */
|
||||||
|
.plyr__poster{
|
||||||
|
display: none !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Get rid of obnoxiously high padding on controls bar */
|
||||||
|
.plyr__controls{
|
||||||
|
padding-top: 4px !important;
|
||||||
|
padding-bottom: 4px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.plyr__captions{
|
||||||
|
pointer-events: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
/* For menus without a button above them - make them scroll if
|
||||||
|
they are too high for the player*/
|
||||||
|
.plyr div[role="menu"]{
|
||||||
|
overflow-y: scroll;
|
||||||
|
max-height: calc(var(--video_height)*1px - 10px - 40px);
|
||||||
|
}
|
||||||
|
|
||||||
|
/* For menus with a button above them */
|
||||||
|
.plyr button + div[role="menu"]{
|
||||||
|
overflow-y: scroll;
|
||||||
|
/* Subtract margin between controls and menu, and controls height,
|
||||||
|
and height of top menu button*/
|
||||||
|
max-height: calc(var(--video_height)*1px - 10px - 40px - 42px*var(--plyr-control-spacing-num)/10);
|
||||||
|
}
|
||||||
1091
youtube/subscriptions.py
Normal file
1091
youtube/subscriptions.py
Normal file
File diff suppressed because it is too large
Load Diff
212
youtube/templates/base.html
Normal file
212
youtube/templates/base.html
Normal file
@@ -0,0 +1,212 @@
|
|||||||
|
<!DOCTYPE html>
|
||||||
|
<html>
|
||||||
|
<head>
|
||||||
|
<meta charset="utf-8">
|
||||||
|
<meta name="viewport" content="width=device-width, initial-scale=1"/>
|
||||||
|
<title>{{ page_title }}</title>
|
||||||
|
<meta http-equiv="Content-Security-Policy" content="default-src 'self' 'unsafe-inline'; media-src 'self' blob: https://*.googlevideo.com;
|
||||||
|
{{ "img-src 'self' https://*.googleusercontent.com https://*.ggpht.com https://*.ytimg.com;" if not settings.proxy_images else "" }}">
|
||||||
|
<link href="/youtube.com/shared.css" type="text/css" rel="stylesheet">
|
||||||
|
<link href="{{ theme_path }}" type="text/css" rel="stylesheet">
|
||||||
|
<link href="/youtube.com/static/comments.css" type="text/css" rel="stylesheet">
|
||||||
|
<link href="/youtube.com/static/favicon.ico" type="image/x-icon" rel="icon">
|
||||||
|
<link title="Youtube local" href="/youtube.com/opensearch.xml" rel="search" type="application/opensearchdescription+xml">
|
||||||
|
<style type="text/css">
|
||||||
|
{% block style %}
|
||||||
|
{{ style }}
|
||||||
|
{% endblock %}
|
||||||
|
</style>
|
||||||
|
|
||||||
|
{% if js_data %}
|
||||||
|
<script>data = {{ js_data|tojson }}</script>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% block head %}
|
||||||
|
{% endblock %}
|
||||||
|
</head>
|
||||||
|
<body>
|
||||||
|
<header>
|
||||||
|
<form id="site-search" action="/youtube.com/results">
|
||||||
|
<a href="/youtube.com" id="home-link">Home</a>
|
||||||
|
<input type="search" name="search_query" class="search-box" value="{{ search_box_value }}"
|
||||||
|
{{ "autofocus" if (request.path in ("/", "/results") or error_message) else "" }} placeholder="Type to search...">
|
||||||
|
<button type="submit" value="Search" class="button search-button">Search</button>
|
||||||
|
<label for="filter-dropdown-toggle-cbox" class="filter-dropdown-toggle-button button">Filter</label>
|
||||||
|
<input id="filter-dropdown-toggle-cbox" type="checkbox" hidden>
|
||||||
|
<div class="filter-dropdown-content">
|
||||||
|
<h3>Sort by</h3>
|
||||||
|
<input type="radio" id="sort_relevance" name="sort" value="0">
|
||||||
|
<label for="sort_relevance">Relevance</label>
|
||||||
|
|
||||||
|
<input type="radio" id="sort_upload_date" name="sort" value="2">
|
||||||
|
<label for="sort_upload_date">Upload date</label>
|
||||||
|
|
||||||
|
<input type="radio" id="sort_view_count" name="sort" value="3">
|
||||||
|
<label for="sort_view_count">View count</label>
|
||||||
|
|
||||||
|
<input type="radio" id="sort_rating" name="sort" value="1">
|
||||||
|
<label for="sort_rating">Rating</label>
|
||||||
|
|
||||||
|
|
||||||
|
<h3>Upload date</h3>
|
||||||
|
<input type="radio" id="time_any" name="time" value="0">
|
||||||
|
<label for="time_any">Any</label>
|
||||||
|
|
||||||
|
<input type="radio" id="time_last_hour" name="time" value="1">
|
||||||
|
<label for="time_last_hour">Last hour</label>
|
||||||
|
|
||||||
|
<input type="radio" id="time_today" name="time" value="2">
|
||||||
|
<label for="time_today">Today</label>
|
||||||
|
|
||||||
|
<input type="radio" id="time_this_week" name="time" value="3">
|
||||||
|
<label for="time_this_week">This week</label>
|
||||||
|
|
||||||
|
<input type="radio" id="time_this_month" name="time" value="4">
|
||||||
|
<label for="time_this_month">This month</label>
|
||||||
|
|
||||||
|
<input type="radio" id="time_this_year" name="time" value="5">
|
||||||
|
<label for="time_this_year">This year</label>
|
||||||
|
|
||||||
|
<h3>Type</h3>
|
||||||
|
<input type="radio" id="type_any" name="type" value="0">
|
||||||
|
<label for="type_any">Any</label>
|
||||||
|
|
||||||
|
<input type="radio" id="type_video" name="type" value="1">
|
||||||
|
<label for="type_video">Video</label>
|
||||||
|
|
||||||
|
<input type="radio" id="type_channel" name="type" value="2">
|
||||||
|
<label for="type_channel">Channel</label>
|
||||||
|
|
||||||
|
<input type="radio" id="type_playlist" name="type" value="3">
|
||||||
|
<label for="type_playlist">Playlist</label>
|
||||||
|
|
||||||
|
<input type="radio" id="type_movie" name="type" value="4">
|
||||||
|
<label for="type_movie">Movie</label>
|
||||||
|
|
||||||
|
<input type="radio" id="type_show" name="type" value="5">
|
||||||
|
<label for="type_show">Show</label>
|
||||||
|
|
||||||
|
|
||||||
|
<h3>Duration</h3>
|
||||||
|
<input type="radio" id="duration_any" name="duration" value="0">
|
||||||
|
<label for="duration_any">Any</label>
|
||||||
|
|
||||||
|
<input type="radio" id="duration_short" name="duration" value="1">
|
||||||
|
<label for="duration_short">Short (< 4 minutes)</label>
|
||||||
|
|
||||||
|
<input type="radio" id="duration_long" name="duration" value="2">
|
||||||
|
<label for="duration_long">Long (> 20 minutes)</label>
|
||||||
|
|
||||||
|
</div>
|
||||||
|
{% if header_playlist_names is defined %}
|
||||||
|
<label for="playlist-form-toggle-cbox" class="playlist-form-toggle-button button">+Playlist</label>
|
||||||
|
{% endif %}
|
||||||
|
</form>
|
||||||
|
|
||||||
|
{% if header_playlist_names is defined %}
|
||||||
|
<input id="playlist-form-toggle-cbox" type="checkbox" hidden>
|
||||||
|
<form id="playlist-edit" action="/youtube.com/edit_playlist" method="post" target="_self">
|
||||||
|
<input name="playlist_name" id="playlist-name-selection" list="playlist-options" type="text" placeholder="Playlist name">
|
||||||
|
<datalist id="playlist-options">
|
||||||
|
{% for playlist_name in header_playlist_names %}
|
||||||
|
<option value="{{ playlist_name }}">{{ playlist_name }}</option>
|
||||||
|
{% endfor %}
|
||||||
|
</datalist>
|
||||||
|
<button type="submit" id="playlist-add-button" class="button" name="action" value="add">Add to playlist</button>
|
||||||
|
<button type="reset" id="item-selection-reset" class="button">Clear selection</button>
|
||||||
|
</form>
|
||||||
|
<script>
|
||||||
|
/* Takes control of the form if javascript is enabled, so that adding stuff to a playlist will not cause things to stop loading, and will display a status message. If javascript is disabled, the form will still work using regular HTML methods, but causes things on the page (such as the video) to stop loading. */
|
||||||
|
var playlistAddForm = document.getElementById('playlist-edit');
|
||||||
|
|
||||||
|
function setStyle(element, property, value){
|
||||||
|
element.style[property] = value;
|
||||||
|
}
|
||||||
|
function removeMessage(messageBox){
|
||||||
|
messageBox.parentNode.removeChild(messageBox);
|
||||||
|
}
|
||||||
|
|
||||||
|
function displayMessage(text, error=false){
|
||||||
|
let currentMessageBox = document.getElementById('message-box');
|
||||||
|
if(currentMessageBox !== null){
|
||||||
|
currentMessageBox.parentNode.removeChild(currentMessageBox);
|
||||||
|
}
|
||||||
|
let messageBox = document.createElement('div');
|
||||||
|
if(error){
|
||||||
|
messageBox.setAttribute('role', 'alert');
|
||||||
|
} else {
|
||||||
|
messageBox.setAttribute('role', 'status');
|
||||||
|
}
|
||||||
|
messageBox.setAttribute('id', 'message-box');
|
||||||
|
let textNode = document.createTextNode(text);
|
||||||
|
messageBox.appendChild(textNode);
|
||||||
|
document.querySelector('main').appendChild(messageBox);
|
||||||
|
let currentstyle = window.getComputedStyle(messageBox);
|
||||||
|
let removalDelay;
|
||||||
|
if(error){
|
||||||
|
removalDelay = 5000;
|
||||||
|
} else {
|
||||||
|
removalDelay = 1500;
|
||||||
|
}
|
||||||
|
window.setTimeout(setStyle, 20, messageBox, 'opacity', 1);
|
||||||
|
window.setTimeout(setStyle, removalDelay, messageBox, 'opacity', 0);
|
||||||
|
window.setTimeout(removeMessage, removalDelay+300, messageBox);
|
||||||
|
}
|
||||||
|
// https://developer.mozilla.org/en-US/docs/Learn/HTML/Forms/Sending_forms_through_JavaScript
|
||||||
|
function sendData(event){
|
||||||
|
var clicked_button = document.activeElement;
|
||||||
|
if(clicked_button === null || clicked_button.getAttribute('type') !== 'submit' || clicked_button.parentElement != event.target){
|
||||||
|
console.log('ERROR: clicked_button not valid');
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
if(clicked_button.getAttribute('value') !== 'add'){
|
||||||
|
return; // video(s) are being removed from playlist, just let it refresh the page
|
||||||
|
}
|
||||||
|
event.preventDefault();
|
||||||
|
var XHR = new XMLHttpRequest();
|
||||||
|
var FD = new FormData(playlistAddForm);
|
||||||
|
|
||||||
|
if(FD.getAll('video_info_list').length === 0){
|
||||||
|
displayMessage('Error: No videos selected', true);
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
|
||||||
|
if(FD.get('playlist_name') === ""){
|
||||||
|
displayMessage('Error: No playlist selected', true);
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
|
||||||
|
// https://stackoverflow.com/questions/48322876/formdata-doesnt-include-value-of-buttons
|
||||||
|
FD.append('action', 'add');
|
||||||
|
|
||||||
|
XHR.addEventListener('load', function(event){
|
||||||
|
if(event.target.status == 204){
|
||||||
|
displayMessage('Added videos to playlist "' + FD.get('playlist_name') + '"');
|
||||||
|
} else {
|
||||||
|
displayMessage('Error adding videos to playlist: ' + event.target.status.toString(), true);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
XHR.addEventListener('error', function(event){
|
||||||
|
if(event.target.status == 0){
|
||||||
|
displayMessage('XHR failed: Check that XHR requests are allowed', true);
|
||||||
|
} else {
|
||||||
|
displayMessage('XHR failed: Unknown error', true);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
XHR.open('POST', playlistAddForm.getAttribute('action'));
|
||||||
|
XHR.send(FD);
|
||||||
|
}
|
||||||
|
|
||||||
|
playlistAddForm.addEventListener('submit', sendData);
|
||||||
|
</script>
|
||||||
|
{% endif %}
|
||||||
|
</header>
|
||||||
|
<main>
|
||||||
|
{% block main %}
|
||||||
|
{{ main }}
|
||||||
|
{% endblock %}
|
||||||
|
</main>
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
215
youtube/templates/channel.html
Normal file
215
youtube/templates/channel.html
Normal file
@@ -0,0 +1,215 @@
|
|||||||
|
{% if current_tab == 'search' %}
|
||||||
|
{% set page_title = search_box_value + ' - Page ' + page_number|string %}
|
||||||
|
{% else %}
|
||||||
|
{% set page_title = channel_name|string + ' - Channel' %}
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% import "common_elements.html" as common_elements %}
|
||||||
|
{% block style %}
|
||||||
|
main{
|
||||||
|
padding-left: 0px;
|
||||||
|
padding-right: 0px;
|
||||||
|
}
|
||||||
|
.channel-metadata{
|
||||||
|
display: flex;
|
||||||
|
align-items: center;
|
||||||
|
}
|
||||||
|
.avatar{
|
||||||
|
height:200px;
|
||||||
|
width:200px;
|
||||||
|
}
|
||||||
|
.summary{
|
||||||
|
margin-left: 5px;
|
||||||
|
/* Prevent uninterupted words in description overflowing the page: https://daverupert.com/2017/09/breaking-the-grid/ */
|
||||||
|
min-width: 0px;
|
||||||
|
}
|
||||||
|
.short-description{
|
||||||
|
line-height: 1em;
|
||||||
|
max-height: 6em;
|
||||||
|
overflow: hidden;
|
||||||
|
}
|
||||||
|
|
||||||
|
.channel-tabs{
|
||||||
|
display: flex;
|
||||||
|
flex-wrap: wrap;
|
||||||
|
justify-content:start;
|
||||||
|
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 3px;
|
||||||
|
padding-left: 6px;
|
||||||
|
}
|
||||||
|
#links-metadata{
|
||||||
|
display: flex;
|
||||||
|
flex-wrap: wrap;
|
||||||
|
justify-content: start;
|
||||||
|
padding-bottom: 8px;
|
||||||
|
padding-left: 6px;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
#links-metadata > *{
|
||||||
|
margin-top: 8px;
|
||||||
|
margin-left: 10px;
|
||||||
|
}
|
||||||
|
#number-of-results{
|
||||||
|
font-weight:bold;
|
||||||
|
}
|
||||||
|
.content{
|
||||||
|
}
|
||||||
|
.search-content{
|
||||||
|
max-width: 800px;
|
||||||
|
margin-left: 10px;
|
||||||
|
}
|
||||||
|
.item-grid{
|
||||||
|
padding-left: 20px;
|
||||||
|
}
|
||||||
|
.item-list{
|
||||||
|
max-width:800px;
|
||||||
|
margin: auto;
|
||||||
|
}
|
||||||
|
.page-button-row{
|
||||||
|
margin-left: auto;
|
||||||
|
margin-right: auto;
|
||||||
|
}
|
||||||
|
.next-previous-button-row{
|
||||||
|
margin-left: auto;
|
||||||
|
margin-right: auto;
|
||||||
|
}
|
||||||
|
.tab{
|
||||||
|
padding: 5px 0px;
|
||||||
|
width: 200px;
|
||||||
|
}
|
||||||
|
.channel-info{
|
||||||
|
}
|
||||||
|
.channel-info ul{
|
||||||
|
padding-left: 40px;
|
||||||
|
}
|
||||||
|
.channel-info h3{
|
||||||
|
margin-left: 40px;
|
||||||
|
}
|
||||||
|
.channel-info .description{
|
||||||
|
white-space: pre-wrap;
|
||||||
|
min-width: 0;
|
||||||
|
margin-left: 40px;
|
||||||
|
}
|
||||||
|
.medium-item img{
|
||||||
|
max-width: 168px;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media (max-width:500px){
|
||||||
|
.channel-metadata{
|
||||||
|
flex-direction: column;
|
||||||
|
text-align: center;
|
||||||
|
margin-bottom: 30px;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<div class="channel-metadata">
|
||||||
|
<img class="avatar" src="{{ avatar }}" width="200px" height="200px">
|
||||||
|
<div class="summary">
|
||||||
|
<h2 class="title">{{ channel_name }}</h2>
|
||||||
|
<p class="short-description">{{ short_description }}</p>
|
||||||
|
<form method="POST" action="/youtube.com/subscriptions" class="subscribe-unsubscribe">
|
||||||
|
<input type="submit" value="{{ 'Unsubscribe' if subscribed else 'Subscribe' }}">
|
||||||
|
<input type="hidden" name="channel_id" value="{{ channel_id }}">
|
||||||
|
<input type="hidden" name="channel_name" value="{{ channel_name }}">
|
||||||
|
<input type="hidden" name="action" value="{{ 'unsubscribe' if subscribed else 'subscribe' }}">
|
||||||
|
</form>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
<nav class="channel-tabs">
|
||||||
|
{% for tab_name in ('Videos', 'Shorts', 'Streams', 'Playlists', 'About') %}
|
||||||
|
{% if tab_name.lower() == current_tab %}
|
||||||
|
<a class="tab page-button">{{ tab_name }}</a>
|
||||||
|
{% else %}
|
||||||
|
<a class="tab page-button" href="{{ channel_url + '/' + tab_name.lower() }}">{{ tab_name }}</a>
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
|
||||||
|
<form class="channel-search" action="{{ channel_url + '/search' }}">
|
||||||
|
<input type="search" name="query" class="search-box" value="{{ search_box_value }}">
|
||||||
|
<button type="submit" value="Search" class="search-button">Search</button>
|
||||||
|
</form>
|
||||||
|
</nav>
|
||||||
|
{% if current_tab == 'about' %}
|
||||||
|
<div class="channel-info">
|
||||||
|
<ul>
|
||||||
|
{% for (before_text, stat, after_text) in [
|
||||||
|
('Joined ', date_joined, ''),
|
||||||
|
('', approx_view_count, ' views'),
|
||||||
|
('', approx_subscriber_count, ' subscribers'),
|
||||||
|
('', approx_video_count, ' videos'),
|
||||||
|
('Country: ', country, ''),
|
||||||
|
('Canonical Url: ', canonical_url, ''),
|
||||||
|
] %}
|
||||||
|
{% if stat %}
|
||||||
|
<li>{{ before_text + stat|string + after_text }}</li>
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
</ul>
|
||||||
|
<hr>
|
||||||
|
<h3>Description</h3>
|
||||||
|
<div class="description">{{ common_elements.text_runs(description) }}</div>
|
||||||
|
<hr>
|
||||||
|
<ul>
|
||||||
|
{% for text, url in links%}
|
||||||
|
{% if url %}
|
||||||
|
<li><a href="{{ url }}">{{ text }}</a></li>
|
||||||
|
{% else %}
|
||||||
|
<li>{{ text }}</li>
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
</ul>
|
||||||
|
</div>
|
||||||
|
{% else %}
|
||||||
|
<div class="content {{ current_tab + '-content'}}">
|
||||||
|
<div id="links-metadata">
|
||||||
|
{% if current_tab in ('videos', 'shorts', 'streams') %}
|
||||||
|
{% set sorts = [('1', 'views'), ('2', 'oldest'), ('3', 'newest'), ('4', 'newest - no shorts'),] %}
|
||||||
|
<div id="number-of-results">{{ number_of_videos }} videos</div>
|
||||||
|
{% elif current_tab == 'playlists' %}
|
||||||
|
{% set sorts = [('2', 'oldest'), ('3', 'newest'), ('4', 'last video added')] %}
|
||||||
|
{% if items %}
|
||||||
|
<h2 class="page-number">Page {{ page_number }}</h2>
|
||||||
|
{% else %}
|
||||||
|
<h2 class="page-number">No items</h2>
|
||||||
|
{% endif %}
|
||||||
|
{% elif current_tab == 'search' %}
|
||||||
|
{% if items %}
|
||||||
|
<h2 class="page-number">Page {{ page_number }}</h2>
|
||||||
|
{% else %}
|
||||||
|
<h2 class="page-number">No results</h2>
|
||||||
|
{% endif %}
|
||||||
|
{% else %}
|
||||||
|
{% set sorts = [] %}
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% for sort_number, sort_name in sorts %}
|
||||||
|
{% if sort_number == current_sort.__str__() %}
|
||||||
|
<a class="sort-button">{{ 'Sorted by ' + sort_name }}</a>
|
||||||
|
{% else %}
|
||||||
|
<a class="sort-button" href="{{ channel_url + '/' + current_tab + '?sort=' + sort_number }}">{{ 'Sort by ' + sort_name }}</a>
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<nav class="{{ 'item-list' if current_tab == 'search' else 'item-grid' }}">
|
||||||
|
{% for item_info in items %}
|
||||||
|
{{ common_elements.item(item_info, include_author=false) }}
|
||||||
|
{% endfor %}
|
||||||
|
</nav>
|
||||||
|
|
||||||
|
{% if current_tab in ('videos', 'shorts', 'streams') %}
|
||||||
|
<nav class="page-button-row">
|
||||||
|
{{ common_elements.page_buttons(number_of_pages, channel_url + '/' + current_tab, parameters_dictionary, include_ends=(current_sort.__str__() in '34')) }}
|
||||||
|
</nav>
|
||||||
|
{% elif current_tab == 'playlists' or current_tab == 'search' %}
|
||||||
|
<nav class="next-previous-button-row">
|
||||||
|
{{ common_elements.next_previous_buttons(is_last_page, channel_url + '/' + current_tab, parameters_dictionary) }}
|
||||||
|
</nav>
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
{% endif %}
|
||||||
|
{% endblock main %}
|
||||||
68
youtube/templates/comments.html
Normal file
68
youtube/templates/comments.html
Normal file
@@ -0,0 +1,68 @@
|
|||||||
|
{% import "common_elements.html" as common_elements %}
|
||||||
|
|
||||||
|
{% macro render_comment(comment, include_avatar, timestamp_links=False) %}
|
||||||
|
<div class="comment-container">
|
||||||
|
<div class="comment">
|
||||||
|
<a class="author-avatar" href="{{ comment['author_url'] }}" title="{{ comment['author'] }}">
|
||||||
|
{% if include_avatar %}
|
||||||
|
<img class="author-avatar-img" src="{{ comment['author_avatar'] }}">
|
||||||
|
{% endif %}
|
||||||
|
</a>
|
||||||
|
<address class="author-name">
|
||||||
|
<a class="author" href="{{ comment['author_url'] }}" title="{{ comment['author'] }}">{{ comment['author'] }}</a>
|
||||||
|
</address>
|
||||||
|
<a class="permalink" href="{{ comment['permalink'] }}" title="permalink">
|
||||||
|
<time datetime="">{{ comment['time_published'] }}</time>
|
||||||
|
</a>
|
||||||
|
{% if timestamp_links %}
|
||||||
|
<span class="text">{{ common_elements.text_runs(comment['text'])|timestamps|safe }}</span>
|
||||||
|
{% else %}
|
||||||
|
<span class="text">{{ common_elements.text_runs(comment['text']) }}</span>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
<span class="likes">{{ comment['likes_text'] if comment['approx_like_count'] else ''}}</span>
|
||||||
|
<div class="bottom-row">
|
||||||
|
{% if comment['reply_count'] %}
|
||||||
|
{% if settings.use_comments_js and comment['replies_url'] %}
|
||||||
|
<details class="replies" src="{{ comment['replies_url'] }}">
|
||||||
|
<summary>{{ comment['view_replies_text'] }}</summary>
|
||||||
|
<a href="{{ comment['replies_url'] }}" class="replies-open-new-tab" target="_blank">Open in new tab</a>
|
||||||
|
<div class="comment_page">loading..</div>
|
||||||
|
</details>
|
||||||
|
{% elif comment['replies_url'] %}
|
||||||
|
<a href="{{ comment['replies_url'] }}" class="replies">{{ comment['view_replies_text'] }}</a>
|
||||||
|
{% else %}
|
||||||
|
<a class="replies">{{ comment['view_replies_text'] }} (error constructing url)</a>
|
||||||
|
{% endif %}
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
</div>
|
||||||
|
{% endmacro %}
|
||||||
|
|
||||||
|
{% macro video_comments(comments_info) %}
|
||||||
|
<div class="comment-links">
|
||||||
|
{% for link_text, link_url in comments_info['comment_links'] %}
|
||||||
|
<a class="sort-button" href="{{ link_url }}">{{ link_text }}</a>
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
{% if comments_info['error'] %}
|
||||||
|
<div class="comments">
|
||||||
|
<div class="code-box"><code>{{ comments_info['error'] }}</code></div>
|
||||||
|
</div>
|
||||||
|
{% else %}
|
||||||
|
<div class="comments">
|
||||||
|
{% for comment in comments_info['comments'] %}
|
||||||
|
{{ render_comment(comment, comments_info['include_avatars'], True) }}
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
{% if 'more_comments_url' is in comments_info %}
|
||||||
|
<a class="page-button more-comments" href="{{ comments_info['more_comments_url'] }}">More comments</a>
|
||||||
|
{% endif %}
|
||||||
|
{% endif %}
|
||||||
|
{% endmacro %}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
55
youtube/templates/comments_page.html
Normal file
55
youtube/templates/comments_page.html
Normal file
@@ -0,0 +1,55 @@
|
|||||||
|
{% set page_title = ('Replies' if comments_info['is_replies'] else 'Comments page ' + comments_info['page_number']|string) %}
|
||||||
|
{% import "comments.html" as comments with context %}
|
||||||
|
|
||||||
|
{% if not slim %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
|
||||||
|
{% block style %}
|
||||||
|
.comments-area{
|
||||||
|
margin: auto;
|
||||||
|
max-width:640px;
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<section class="comments-area">
|
||||||
|
{% if not comments_info['is_replies'] %}
|
||||||
|
<section class="video-metadata">
|
||||||
|
<a class="video-metadata-thumbnail-box" href="{{ comments_info['video_url'] }}" title="{{ comments_info['video_title'] }}">
|
||||||
|
<img class="video-metadata-thumbnail-img" src="{{ comments_info['video_thumbnail'] }}" height="180px" width="320px">
|
||||||
|
</a>
|
||||||
|
<a class="title" href="{{ comments_info['video_url'] }}" title="{{ comments_info['video_title'] }}">{{ comments_info['video_title'] }}</a>
|
||||||
|
|
||||||
|
<h2>Comments page {{ comments_info['page_number'] }}</h2>
|
||||||
|
<span>Sorted by {{ comments_info['sort_text'] }}</span>
|
||||||
|
</section>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
|
||||||
|
{% if not comments_info['is_replies'] %}
|
||||||
|
<div class="comment-links">
|
||||||
|
{% for link_text, link_url in comments_info['comment_links'] %}
|
||||||
|
<a class="sort-button" href="{{ link_url }}">{{ link_text }}</a>
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
<div class="comments">
|
||||||
|
{% for comment in comments_info['comments'] %}
|
||||||
|
{{ comments.render_comment(comment, comments_info['include_avatars'], slim) }}
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
{% if 'more_comments_url' is in comments_info %}
|
||||||
|
<a class="page-button more-comments" href="{{ comments_info['more_comments_url'] }}">More comments</a>
|
||||||
|
{% endif %}
|
||||||
|
</section>
|
||||||
|
|
||||||
|
{% if settings.use_comments_js %}
|
||||||
|
<script src="/youtube.com/static/js/common.js"></script>
|
||||||
|
<script src="/youtube.com/static/js/comments.js"></script>
|
||||||
|
{% endif %}
|
||||||
|
{% endblock main %}
|
||||||
|
|
||||||
|
|
||||||
135
youtube/templates/common_elements.html
Normal file
135
youtube/templates/common_elements.html
Normal file
@@ -0,0 +1,135 @@
|
|||||||
|
{% macro text_runs(runs) %}
|
||||||
|
{%- if runs[0] is mapping -%}
|
||||||
|
{%- for text_run in runs -%}
|
||||||
|
{%- if text_run.get("bold", false) -%}
|
||||||
|
<b>{{ text_run["text"] }}</b>
|
||||||
|
{%- elif text_run.get('italics', false) -%}
|
||||||
|
<i>{{ text_run["text"] }}</i>
|
||||||
|
{%- else -%}
|
||||||
|
{{ text_run["text"] }}
|
||||||
|
{%- endif -%}
|
||||||
|
{%- endfor -%}
|
||||||
|
{%- elif runs -%}
|
||||||
|
{{ runs }}
|
||||||
|
{%- endif -%}
|
||||||
|
{% endmacro %}
|
||||||
|
|
||||||
|
{% macro item(info, description=false, horizontal=true, include_author=true, include_badges=true, lazy_load=false) %}
|
||||||
|
<div class="item-box {{ info['type'] + '-item-box' }} {{'horizontal-item-box' if horizontal else 'vertical-item-box'}} {{'has-description' if description else 'no-description'}}">
|
||||||
|
{% if info['error'] %}
|
||||||
|
{{ info['error'] }}
|
||||||
|
{% else %}
|
||||||
|
<div class="item {{ info['type'] + '-item' }}">
|
||||||
|
<a class="thumbnail-box" href="{{ info['url'] }}" title="{{ info['title'] }}">
|
||||||
|
{% if lazy_load %}
|
||||||
|
<img class="thumbnail-img lazy" data-src="{{ info['thumbnail'] }}">
|
||||||
|
{% else %}
|
||||||
|
<img class="thumbnail-img" src="{{ info['thumbnail'] }}">
|
||||||
|
{% endif %}
|
||||||
|
{% if info['type'] != 'channel' %}
|
||||||
|
<div class="thumbnail-info">
|
||||||
|
<span>{{ (info['video_count']|commatize + ' videos') if info['type'] == 'playlist' else info['duration'] }}</span>
|
||||||
|
</div>
|
||||||
|
{% endif %}
|
||||||
|
</a>
|
||||||
|
<div class="item-metadata">
|
||||||
|
<div class="title"><a class="title" href="{{ info['url'] }}" title="{{ info['title'] }}">{{ info['title'] }}</a></div>
|
||||||
|
|
||||||
|
{% if include_author %}
|
||||||
|
{% if info.get('author_url') %}
|
||||||
|
<address title="{{ info['author'] }}">By <a href="{{ info['author_url'] }}">{{ info['author'] }}</a></address>
|
||||||
|
{% else %}
|
||||||
|
<address title="{{ info['author'] }}"><b>{{ info['author'] }}</b></address>
|
||||||
|
{% endif %}
|
||||||
|
{% endif %}
|
||||||
|
<ul class="stats {{'horizontal-stats' if horizontal else 'vertical-stats'}}">
|
||||||
|
{% if info['type'] == 'channel' %}
|
||||||
|
<li><span>{{ info['approx_subscriber_count'] }} subscribers</span></li>
|
||||||
|
<li><span>{{ info['video_count']|commatize }} videos</span></li>
|
||||||
|
{% else %}
|
||||||
|
{% if info.get('approx_view_count') %}
|
||||||
|
<li><span class="views">{{ info['approx_view_count'] }} views</span></li>
|
||||||
|
{% endif %}
|
||||||
|
{% if info.get('time_published') %}
|
||||||
|
<li><time>{{ info['time_published'] }}</time></li>
|
||||||
|
{% endif %}
|
||||||
|
{% endif %}
|
||||||
|
</ul>
|
||||||
|
|
||||||
|
{% if description %}
|
||||||
|
<span class="description">{{ text_runs(info.get('description', '')) }}</span>
|
||||||
|
{% endif %}
|
||||||
|
{% if include_badges %}
|
||||||
|
<span class="badges">{{ info['badges']|join(' | ') }}</span>
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
{% if info['type'] == 'video' %}
|
||||||
|
<input class="item-checkbox" type="checkbox" name="video_info_list" value="{{ info['video_info'] }}" form="playlist-edit">
|
||||||
|
{% endif %}
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
|
||||||
|
{% endmacro %}
|
||||||
|
|
||||||
|
{% macro page_buttons(estimated_pages, url, parameters_dictionary, include_ends=false) %}
|
||||||
|
{% set current_page = parameters_dictionary.get('page', 1)|int %}
|
||||||
|
{% set parameters_dictionary = parameters_dictionary.to_dict() %}
|
||||||
|
{% if current_page is le(5) %}
|
||||||
|
{% set page_start = 1 %}
|
||||||
|
{% set page_end = [9, estimated_pages]|min %}
|
||||||
|
{% else %}
|
||||||
|
{% set page_start = current_page - 4 %}
|
||||||
|
{% set page_end = [current_page + 4, estimated_pages]|min %}
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% if include_ends and page_start is gt(1) %}
|
||||||
|
{% set _ = parameters_dictionary.__setitem__('page', 1) %}
|
||||||
|
<a class="page-button first-page-button" href="{{ url + '?' + parameters_dictionary|urlencode }}">{{ 1 }}</a>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% for page in range(page_start, page_end+1) %}
|
||||||
|
{% if page == current_page %}
|
||||||
|
<div class="page-button">{{ page }}</div>
|
||||||
|
{% else %}
|
||||||
|
{# https://stackoverflow.com/questions/36886650/how-to-add-a-new-entry-into-a-dictionary-object-while-using-jinja2 #}
|
||||||
|
{% set _ = parameters_dictionary.__setitem__('page', page) %}
|
||||||
|
<a class="page-button" href="{{ url + '?' + parameters_dictionary|urlencode }}">{{ page }}</a>
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
|
||||||
|
{% if include_ends and page_end is lt(estimated_pages) %}
|
||||||
|
{% set _ = parameters_dictionary.__setitem__('page', estimated_pages) %}
|
||||||
|
<a class="page-button last-page-button" href="{{ url + '?' + parameters_dictionary|urlencode }}">{{ estimated_pages }}</a>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% endmacro %}
|
||||||
|
|
||||||
|
{% macro next_previous_buttons(is_last_page, url, parameters_dictionary) %}
|
||||||
|
{% set current_page = parameters_dictionary.get('page', 1)|int %}
|
||||||
|
{% set parameters_dictionary = parameters_dictionary.to_dict() %}
|
||||||
|
|
||||||
|
{% if current_page != 1 %}
|
||||||
|
{% set _ = parameters_dictionary.__setitem__('page', current_page - 1) %}
|
||||||
|
<a class="page-button previous-page" href="{{ url + '?' + parameters_dictionary|urlencode }}">Previous page</a>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% if not is_last_page %}
|
||||||
|
{% set _ = parameters_dictionary.__setitem__('page', current_page + 1) %}
|
||||||
|
<a class="page-button next-page" href="{{ url + '?' + parameters_dictionary|urlencode }}">Next page</a>
|
||||||
|
{% endif %}
|
||||||
|
{% endmacro %}
|
||||||
|
|
||||||
|
{% macro next_previous_ctoken_buttons(prev_ctoken, next_ctoken, url, parameters_dictionary) %}
|
||||||
|
{% set parameters_dictionary = parameters_dictionary.to_dict() %}
|
||||||
|
|
||||||
|
{% if prev_ctoken %}
|
||||||
|
{% set _ = parameters_dictionary.__setitem__('ctoken', prev_ctoken) %}
|
||||||
|
<a class="page-button previous-page" href="{{ url + '?' + parameters_dictionary|urlencode }}">Previous page</a>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% if next_ctoken %}
|
||||||
|
{% set _ = parameters_dictionary.__setitem__('ctoken', next_ctoken) %}
|
||||||
|
<a class="page-button next-page" href="{{ url + '?' + parameters_dictionary|urlencode }}">Next page</a>
|
||||||
|
{% endif %}
|
||||||
|
{% endmacro %}
|
||||||
117
youtube/templates/embed.html
Normal file
117
youtube/templates/embed.html
Normal file
@@ -0,0 +1,117 @@
|
|||||||
|
<!DOCTYPE html>
|
||||||
|
<html>
|
||||||
|
<head>
|
||||||
|
<meta charset="utf-8">
|
||||||
|
<title>{{ title }}</title>
|
||||||
|
<meta http-equiv="Content-Security-Policy" content="default-src 'self' 'unsafe-inline'; media-src 'self' https://*.googlevideo.com;
|
||||||
|
{{ "img-src 'self' https://*.googleusercontent.com https://*.ggpht.com https://*.ytimg.com;" if not settings.proxy_images else "" }}">
|
||||||
|
<!--<link href="{{ theme_path }}" type="text/css" rel="stylesheet">-->
|
||||||
|
|
||||||
|
<style>
|
||||||
|
* {
|
||||||
|
box-sizing: border-box;
|
||||||
|
}
|
||||||
|
html {
|
||||||
|
font-family: {{ font_family|safe }};
|
||||||
|
}
|
||||||
|
html, body, div, ol, h2{
|
||||||
|
margin: 0px;
|
||||||
|
padding: 0px;
|
||||||
|
}
|
||||||
|
a:link {
|
||||||
|
color: #22aaff;
|
||||||
|
}
|
||||||
|
a:visited {
|
||||||
|
color: #7755ff;
|
||||||
|
}
|
||||||
|
body{
|
||||||
|
background-color: black;
|
||||||
|
color: white;
|
||||||
|
max-height: 100vh;
|
||||||
|
overflow-y: hidden;
|
||||||
|
}
|
||||||
|
.text-height{
|
||||||
|
font-size: 0.75rem;
|
||||||
|
overflow-y: hidden;
|
||||||
|
height: 1rem;
|
||||||
|
}
|
||||||
|
a.video-link{
|
||||||
|
color: white;
|
||||||
|
}
|
||||||
|
h2 {
|
||||||
|
font-weight: normal;
|
||||||
|
margin-left: 5px;
|
||||||
|
}
|
||||||
|
ol.video-info-list{
|
||||||
|
padding: 0px;
|
||||||
|
list-style: none;
|
||||||
|
display: flex;
|
||||||
|
flex-direction: row;
|
||||||
|
}
|
||||||
|
ol.video-info-list li{
|
||||||
|
margin-left: 20px;
|
||||||
|
font-size: 0.75rem;
|
||||||
|
max-width: 75%;
|
||||||
|
}
|
||||||
|
address{
|
||||||
|
font-style: normal;
|
||||||
|
}
|
||||||
|
.video-info-list span{
|
||||||
|
height: 1rem;
|
||||||
|
overflow-y: hidden;
|
||||||
|
display: inline-block;
|
||||||
|
}
|
||||||
|
body > video, body > .plyr{
|
||||||
|
max-height: calc(100vh - 2rem);
|
||||||
|
width: 100%;
|
||||||
|
height: 56.25vw; /* 360/640 == 720/1280 */
|
||||||
|
}
|
||||||
|
</style>
|
||||||
|
|
||||||
|
{% if js_data %}
|
||||||
|
<script>data = {{ js_data|tojson }}</script>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% if settings.video_player == 1 %}
|
||||||
|
<!-- plyr -->
|
||||||
|
<script>var storyboard_url = {{ storyboard_url | tojson }}</script>
|
||||||
|
<link href="/youtube.com/static/modules/plyr/plyr.css" rel="stylesheet"/>
|
||||||
|
<link href="/youtube.com/static/plyr_fixes.css" rel="stylesheet"/>
|
||||||
|
<!--/ plyr -->
|
||||||
|
{% endif %}
|
||||||
|
</head>
|
||||||
|
|
||||||
|
<body>
|
||||||
|
<a class="video-link text-height" href="{{ video_url }}" title="{{ title }}" target="_blank" rel="noopener noreferrer"><h2 class="text-height">{{ title }}</h2></a>
|
||||||
|
<div class="video-info-bar text-height">
|
||||||
|
<ol class="video-info-list text-height">
|
||||||
|
<li class="text-height"><time class="text-height"><span class="text-height">{{ time_published }}</span></time></li>
|
||||||
|
<li class="text-height"><address class="text-height"><span class="text-height">Uploaded by <a class="text-height" href="{{ uploader_channel_url }}" title="{{ uploader }}" target="_blank" rel="noopener noreferrer">{{ uploader }}</a></span></address></li>
|
||||||
|
</ol>
|
||||||
|
</div>
|
||||||
|
<video controls autofocus class="video" height="{{ video_height }}px">
|
||||||
|
{% if uni_sources %}
|
||||||
|
<source src="{{ uni_sources[uni_idx]['url'] }}" type="{{ uni_sources[uni_idx]['type'] }}" data-res="{{ uni_sources[uni_idx]['quality'] }}">
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% for source in subtitle_sources %}
|
||||||
|
{% if source['on'] %}
|
||||||
|
<track label="{{ source['label'] }}" src="{{ source['url'] }}" kind="subtitles" srclang="{{ source['srclang'] }}" default>
|
||||||
|
{% else %}
|
||||||
|
<track label="{{ source['label'] }}" src="{{ source['url'] }}" kind="subtitles" srclang="{{ source['srclang'] }}">
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
</video>
|
||||||
|
{% if settings.video_player == 1 %}
|
||||||
|
<!-- plyr -->
|
||||||
|
<script src="/youtube.com/static/modules/plyr/plyr.js"></script>
|
||||||
|
<script src="/youtube.com/static/js/plyr-start.js"></script>
|
||||||
|
<!-- /plyr -->
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% if settings.use_video_hotkeys %}
|
||||||
|
<script src="/youtube.com/static/js/common.js"></script>
|
||||||
|
<script src="/youtube.com/static/js/hotkeys.js"></script>
|
||||||
|
{% endif %}
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
19
youtube/templates/error.html
Normal file
19
youtube/templates/error.html
Normal file
@@ -0,0 +1,19 @@
|
|||||||
|
{% set page_title = 'Error' %}
|
||||||
|
|
||||||
|
{% if not slim %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
{% if traceback %}
|
||||||
|
<div id="error-box">
|
||||||
|
<h1>500 Uncaught exception:</h1>
|
||||||
|
<div class="code-box"><code>{{ traceback }}</code></div>
|
||||||
|
<p>Please report this issue at <a href="https://github.com/user234683/youtube-local/issues" target="_blank">https://github.com/user234683/youtube-local/issues</a></p>
|
||||||
|
<p>Remember to include the traceback in your issue and redact any information in it you do not want to share</p>
|
||||||
|
</div>
|
||||||
|
{% else %}
|
||||||
|
<div id="error-message">{{ error_message }}</div>
|
||||||
|
{% endif %}
|
||||||
|
{% endblock %}
|
||||||
|
|
||||||
82
youtube/templates/home.html
Normal file
82
youtube/templates/home.html
Normal file
@@ -0,0 +1,82 @@
|
|||||||
|
{% set page_title = title %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% block style %}
|
||||||
|
ul {
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 20px;
|
||||||
|
width: 400px;
|
||||||
|
max-width: 100%;
|
||||||
|
margin: auto;
|
||||||
|
margin-top: 20px;
|
||||||
|
}
|
||||||
|
li {
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
.recommended {
|
||||||
|
max-width: 1200px;
|
||||||
|
margin: 40px auto;
|
||||||
|
display: flex;
|
||||||
|
flex-wrap: wrap;
|
||||||
|
gap: 24px;
|
||||||
|
justify-content: center;
|
||||||
|
}
|
||||||
|
.video-card {
|
||||||
|
background: var(--interface-color);
|
||||||
|
border-radius: 8px;
|
||||||
|
box-shadow: 0 2px 8px rgba(0,0,0,0.08);
|
||||||
|
width: 320px;
|
||||||
|
overflow: hidden;
|
||||||
|
text-align: left;
|
||||||
|
transition: box-shadow 0.2s;
|
||||||
|
}
|
||||||
|
.video-card:hover {
|
||||||
|
box-shadow: 0 4px 16px rgba(0,0,0,0.16);
|
||||||
|
}
|
||||||
|
.video-thumb {
|
||||||
|
width: 100%;
|
||||||
|
height: 180px;
|
||||||
|
object-fit: cover;
|
||||||
|
display: block;
|
||||||
|
}
|
||||||
|
.video-info {
|
||||||
|
padding: 12px 16px;
|
||||||
|
}
|
||||||
|
.video-title {
|
||||||
|
font-size: 1.1em;
|
||||||
|
font-weight: bold;
|
||||||
|
margin-bottom: 6px;
|
||||||
|
color: var(--text-color);
|
||||||
|
text-decoration: none;
|
||||||
|
}
|
||||||
|
.video-meta {
|
||||||
|
color: #888;
|
||||||
|
font-size: 0.95em;
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
{% block main %}
|
||||||
|
<ul>
|
||||||
|
<li><a href="/youtube.com/playlists">Local playlists</a></li>
|
||||||
|
<li><a href="/youtube.com/subscriptions">Subscriptions</a></li>
|
||||||
|
<li><a href="/youtube.com/subscription_manager">Subscription Manager</a></li>
|
||||||
|
<li><a href="/youtube.com/settings">Settings</a></li>
|
||||||
|
</ul>
|
||||||
|
{% if recommended_videos %}
|
||||||
|
<h2 style="text-align:center;margin-top:40px;">Recommended Videos</h2>
|
||||||
|
<div class="recommended">
|
||||||
|
{% for video in recommended_videos %}
|
||||||
|
<div class="video-card">
|
||||||
|
<a href="/watch?v={{ video.videoId }}">
|
||||||
|
<img class="video-thumb" src="{{ video.thumbnail.thumbnails[-1].url }}" alt="Thumbnail">
|
||||||
|
</a>
|
||||||
|
<div class="video-info">
|
||||||
|
<a class="video-title" href="/watch?v={{ video.videoId }}">{{ video.title.runs[0].text }}</a>
|
||||||
|
<div class="video-meta">
|
||||||
|
{{ video.ownerText.runs[0].text }}<br>
|
||||||
|
{{ video.viewCountText.simpleText if video.viewCountText else '' }}
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
{% endif %}
|
||||||
|
{% endblock main %}
|
||||||
73
youtube/templates/local_playlist.html
Normal file
73
youtube/templates/local_playlist.html
Normal file
@@ -0,0 +1,73 @@
|
|||||||
|
{% set page_title = playlist_name + ' - Local playlist' %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% import "common_elements.html" as common_elements %}
|
||||||
|
{% block style %}
|
||||||
|
main > *{
|
||||||
|
width: 800px;
|
||||||
|
max-width: 100%;
|
||||||
|
margin: auto;
|
||||||
|
}
|
||||||
|
|
||||||
|
.playlist-metadata{
|
||||||
|
display: flex;
|
||||||
|
flex-direction: row;
|
||||||
|
flex-wrap: wrap;
|
||||||
|
justify-content: space-between;
|
||||||
|
|
||||||
|
|
||||||
|
margin: 15px auto;
|
||||||
|
padding: 7px;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
}
|
||||||
|
.playlist-title{
|
||||||
|
}
|
||||||
|
#export-options{
|
||||||
|
justify-self: end;
|
||||||
|
}
|
||||||
|
|
||||||
|
#video-remove-container{
|
||||||
|
display: flex;
|
||||||
|
justify-content: space-between;
|
||||||
|
margin: 0px auto 15px auto;
|
||||||
|
}
|
||||||
|
#playlist-remove-button{
|
||||||
|
white-space: nowrap;
|
||||||
|
}
|
||||||
|
|
||||||
|
#results{
|
||||||
|
display: grid;
|
||||||
|
grid-auto-rows: 0fr;
|
||||||
|
grid-row-gap: 10px;
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<div class="playlist-metadata">
|
||||||
|
<h2 class="playlist-title">{{ playlist_name }}</h2>
|
||||||
|
|
||||||
|
<div id="export-options">
|
||||||
|
<form id="playlist-export" method="post">
|
||||||
|
<select id="export-type" name="export_format">
|
||||||
|
<option value="json">JSON</option>
|
||||||
|
<option value="ids">Video id list (txt)</option>
|
||||||
|
<option value="urls">Video url list (txt)</option>
|
||||||
|
</select>
|
||||||
|
<button type="submit" id="playlist-export-button" name="action" value="export">Export</button>
|
||||||
|
</form>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
<form id="playlist-remove" action="/youtube.com/edit_playlist" method="post" target="_self"></form>
|
||||||
|
<div id="video-remove-container">
|
||||||
|
<button type="submit" name="action" value="remove_playlist" form="playlist-remove" formaction="" onclick="return confirm('You are about to permanently delete {{ playlist_name }}\n\nOnce a playlist is permanently deleted, it cannot be recovered.');">Remove playlist</button>
|
||||||
|
<input type="hidden" name="playlist_page" value="{{ playlist_name }}" form="playlist-edit">
|
||||||
|
<button type="submit" id="playlist-remove-button" name="action" value="remove" form="playlist-edit" formaction="">Remove from playlist</button>
|
||||||
|
</div>
|
||||||
|
<div id="results">
|
||||||
|
{% for video_info in videos %}
|
||||||
|
{{ common_elements.item(video_info) }}
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
<nav class="page-button-row">
|
||||||
|
{{ common_elements.page_buttons(num_pages, '/https://www.youtube.com/playlists/' + playlist_name, parameters_dictionary) }}
|
||||||
|
</nav>
|
||||||
|
{% endblock main %}
|
||||||
34
youtube/templates/local_playlists_list.html
Normal file
34
youtube/templates/local_playlists_list.html
Normal file
@@ -0,0 +1,34 @@
|
|||||||
|
{% set page_title = 'Local playlists' %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
|
||||||
|
{% block style %}
|
||||||
|
main{
|
||||||
|
display: flex;
|
||||||
|
justify-content: center;
|
||||||
|
}
|
||||||
|
ul{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
margin-top: 20px;
|
||||||
|
padding: 20px;
|
||||||
|
width: 400px;
|
||||||
|
max-width: 100%;
|
||||||
|
align-self: start;
|
||||||
|
}
|
||||||
|
li{
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<ul>
|
||||||
|
{% for playlist_name, playlist_url in playlists %}
|
||||||
|
<li><a href="{{ playlist_url }}">{{ playlist_name }}</a></li>
|
||||||
|
{% endfor %}
|
||||||
|
</ul>
|
||||||
|
{% endblock main %}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
86
youtube/templates/playlist.html
Normal file
86
youtube/templates/playlist.html
Normal file
@@ -0,0 +1,86 @@
|
|||||||
|
{% set page_title = title|string + ' - Page ' + parameters_dictionary.get('page', '1') %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% import "common_elements.html" as common_elements %}
|
||||||
|
{% block style %}
|
||||||
|
main > * {
|
||||||
|
max-width: 800px;
|
||||||
|
margin:auto;
|
||||||
|
}
|
||||||
|
|
||||||
|
.playlist-metadata{
|
||||||
|
display:grid;
|
||||||
|
grid-template-columns: 0fr 1fr;
|
||||||
|
grid-template-areas:
|
||||||
|
"thumbnail title"
|
||||||
|
"thumbnail author"
|
||||||
|
"thumbnail stats"
|
||||||
|
"thumbnail description";
|
||||||
|
}
|
||||||
|
.playlist-thumbnail{
|
||||||
|
grid-area: thumbnail;
|
||||||
|
width:250px;
|
||||||
|
margin-right: 10px;
|
||||||
|
}
|
||||||
|
.playlist-title{ grid-area: title }
|
||||||
|
.playlist-author{ grid-area: author }
|
||||||
|
.playlist-stats{ grid-area: stats }
|
||||||
|
.playlist-description{
|
||||||
|
grid-area: description;
|
||||||
|
min-width:0px;
|
||||||
|
white-space: pre-line;
|
||||||
|
}
|
||||||
|
|
||||||
|
#results{
|
||||||
|
margin-top:10px;
|
||||||
|
|
||||||
|
display: grid;
|
||||||
|
grid-auto-rows: 0fr;
|
||||||
|
grid-row-gap: 10px;
|
||||||
|
|
||||||
|
}
|
||||||
|
.thumbnail-box{ /* overides rule in shared.css */
|
||||||
|
height: 90px !important;
|
||||||
|
width: 120px !important;
|
||||||
|
}
|
||||||
|
@media (max-width:600px){
|
||||||
|
.playlist-metadata{
|
||||||
|
grid-template-columns: 1fr;
|
||||||
|
grid-template-areas:
|
||||||
|
"thumbnail"
|
||||||
|
"title"
|
||||||
|
"author"
|
||||||
|
"stats"
|
||||||
|
"description";
|
||||||
|
justify-items: center;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<div class="playlist-metadata">
|
||||||
|
<img class="playlist-thumbnail" src="{{ thumbnail }}">
|
||||||
|
<h2 class="playlist-title">{{ title }}</h2>
|
||||||
|
<a class="playlist-author" href="{{ author_url }}">{{ author }}</a>
|
||||||
|
<div class="playlist-stats">
|
||||||
|
<div>{{ video_count|commatize }} videos</div>
|
||||||
|
<div>{{ view_count|commatize }} views</div>
|
||||||
|
<div>Last updated {{ time_published }}</div>
|
||||||
|
</div>
|
||||||
|
<div class="playlist-description">{{ common_elements.text_runs(description) }}</div>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<div id="results">
|
||||||
|
{% for info in video_list %}
|
||||||
|
{{ common_elements.item(info) }}
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
<nav class="page-button-row">
|
||||||
|
{{ common_elements.page_buttons(num_pages, '/https://www.youtube.com/playlist', parameters_dictionary) }}
|
||||||
|
</nav>
|
||||||
|
{% endblock main %}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
46
youtube/templates/search.html
Normal file
46
youtube/templates/search.html
Normal file
@@ -0,0 +1,46 @@
|
|||||||
|
{% set search_box_value = query %}
|
||||||
|
{% set page_title = query + ' - Search' %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% import "common_elements.html" as common_elements %}
|
||||||
|
{% block style %}
|
||||||
|
main > * {
|
||||||
|
max-width: 800px;
|
||||||
|
margin: auto;
|
||||||
|
}
|
||||||
|
#result-info{
|
||||||
|
margin-top: 10px;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
padding-left: 10px;
|
||||||
|
padding-right: 10px;
|
||||||
|
}
|
||||||
|
#number-of-results{
|
||||||
|
font-weight:bold;
|
||||||
|
}
|
||||||
|
.item-list{
|
||||||
|
padding-left: 10px;
|
||||||
|
padding-right: 10px;
|
||||||
|
}
|
||||||
|
.badge{
|
||||||
|
background-color:#cccccc;
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<div id="result-info">
|
||||||
|
<div id="number-of-results">Approximately {{ '{:,}'.format(estimated_results) }} results ({{ '{:,}'.format(estimated_pages) }} pages)</div>
|
||||||
|
{% if corrections['type'] == 'showing_results_for' %}
|
||||||
|
<div>Showing results for <a>{{ common_elements.text_runs(corrections['corrected_query_text']) }}</a></div>
|
||||||
|
<div>Search instead for <a href="{{ corrections['original_query_url'] }}">{{ corrections['original_query_text'] }}</a></div>
|
||||||
|
{% elif corrections['type'] == 'did_you_mean' %}
|
||||||
|
<div>Did you mean <a href="{{ corrections['corrected_query_url'] }}">{{ common_elements.text_runs(corrections['corrected_query_text']) }}</a></div>
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
<div class="item-list">
|
||||||
|
{% for info in results %}
|
||||||
|
{{ common_elements.item(info, description=true) }}
|
||||||
|
{% endfor %}
|
||||||
|
</div>
|
||||||
|
<nav class="page-button-row">
|
||||||
|
{{ common_elements.page_buttons(estimated_pages, '/https://www.youtube.com/results', parameters_dictionary) }}
|
||||||
|
</nav>
|
||||||
|
{% endblock main %}
|
||||||
80
youtube/templates/settings.html
Normal file
80
youtube/templates/settings.html
Normal file
@@ -0,0 +1,80 @@
|
|||||||
|
{% set page_title = 'Settings' %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% import "common_elements.html" as common_elements %}
|
||||||
|
{% block style %}
|
||||||
|
.settings-form {
|
||||||
|
margin: auto;
|
||||||
|
max-width: 600px;
|
||||||
|
margin-top:10px;
|
||||||
|
padding: 10px;
|
||||||
|
display: block;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
}
|
||||||
|
.settings-list{
|
||||||
|
list-style: none;
|
||||||
|
padding: 0px;
|
||||||
|
}
|
||||||
|
.setting-item{
|
||||||
|
margin-bottom: 10px;
|
||||||
|
padding: 5px;
|
||||||
|
}
|
||||||
|
.setting-item label{
|
||||||
|
display: inline-block;
|
||||||
|
width: 250px;
|
||||||
|
}
|
||||||
|
@media (max-width:650px){
|
||||||
|
h2{
|
||||||
|
text-align: center;
|
||||||
|
}
|
||||||
|
.setting-item{
|
||||||
|
}
|
||||||
|
.setting-item label{
|
||||||
|
display: block; /* make the setting input wrap */
|
||||||
|
margin-bottom: 5px;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<form method="POST" class="settings-form">
|
||||||
|
{% for categ in categories %}
|
||||||
|
<h2>{{ categ|capitalize }}</h2>
|
||||||
|
<ul class="settings-list">
|
||||||
|
{% for setting_name, setting_info, value in settings_by_category[categ] %}
|
||||||
|
{% if not setting_info.get('hidden', false) %}
|
||||||
|
<li class="setting-item">
|
||||||
|
{% if 'label' is in(setting_info) %}
|
||||||
|
<label for="{{ 'setting_' + setting_name }}">{{ setting_info['label'] }}</label>
|
||||||
|
{% else %}
|
||||||
|
<label for="{{ 'setting_' + setting_name }}">{{ setting_name.replace('_', ' ')|capitalize }}</label>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% if setting_info['type'].__name__ == 'bool' %}
|
||||||
|
<input type="checkbox" id="{{ 'setting_' + setting_name }}" name="{{ setting_name }}" {{ 'checked' if value else '' }}>
|
||||||
|
{% elif setting_info['type'].__name__ == 'int' %}
|
||||||
|
{% if 'options' is in(setting_info) %}
|
||||||
|
<select id="{{ 'setting_' + setting_name }}" name="{{ setting_name }}">
|
||||||
|
{% for option in setting_info['options'] %}
|
||||||
|
<option value="{{ option[0] }}" {{ 'selected' if option[0] == value else '' }}>{{ option[1] }}</option>
|
||||||
|
{% endfor %}
|
||||||
|
</select>
|
||||||
|
{% elif 'max' in setting_info and 'min' in setting_info %}
|
||||||
|
<input type="number" id="{{ 'setting_' + setting_name }}" name="{{ setting_name }}" value="{{ value }}" min="{{ setting_info['min'] }}" max="{{ setting_info['max'] }}">
|
||||||
|
{% else %}
|
||||||
|
<input type="number" id="{{ 'setting_' + setting_name }}" name="{{ setting_name }}" value="{{ value }}" step="1">
|
||||||
|
{% endif %}
|
||||||
|
{% elif setting_info['type'].__name__ == 'float' %}
|
||||||
|
|
||||||
|
{% elif setting_info['type'].__name__ == 'str' %}
|
||||||
|
<input type="text" id="{{ 'setting_' + setting_name }}" name="{{ setting_name }}" value="{{ value }}">
|
||||||
|
{% else %}
|
||||||
|
<span>Error: Unknown setting type: setting_info['type'].__name__</span>
|
||||||
|
{% endif %}
|
||||||
|
</li>
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
</ul>
|
||||||
|
{% endfor %}
|
||||||
|
<input type="submit" value="Save settings">
|
||||||
|
</form>
|
||||||
|
{% endblock main %}
|
||||||
495
youtube/templates/shared.css
Normal file
495
youtube/templates/shared.css
Normal file
@@ -0,0 +1,495 @@
|
|||||||
|
* {
|
||||||
|
box-sizing: border-box;
|
||||||
|
}
|
||||||
|
|
||||||
|
h1, h2, h3, h4, h5, h6, div, button{
|
||||||
|
margin:0;
|
||||||
|
padding:0;
|
||||||
|
}
|
||||||
|
|
||||||
|
address{
|
||||||
|
font-style:normal;
|
||||||
|
}
|
||||||
|
|
||||||
|
html{
|
||||||
|
font-family: {{ font_family }};
|
||||||
|
--interface-border-color: var(--text-color);
|
||||||
|
}
|
||||||
|
|
||||||
|
body{
|
||||||
|
margin:0;
|
||||||
|
padding: 0;
|
||||||
|
color:var(--text-color);
|
||||||
|
|
||||||
|
|
||||||
|
background-color:var(--background-color);
|
||||||
|
|
||||||
|
min-height:100vh;
|
||||||
|
display: flex;
|
||||||
|
flex-direction: column;
|
||||||
|
}
|
||||||
|
|
||||||
|
header{
|
||||||
|
background-color:#333333;
|
||||||
|
min-height: 50px;
|
||||||
|
padding: 0px 5px;
|
||||||
|
|
||||||
|
display: flex;
|
||||||
|
justify-content: center;
|
||||||
|
}
|
||||||
|
#site-search{
|
||||||
|
max-width: 670px;
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: auto 1fr auto auto auto;
|
||||||
|
grid-template-rows: 50px 0fr;
|
||||||
|
grid-template-areas: "home search-bar search-button filter-button playlist"
|
||||||
|
". . . dropdown .";
|
||||||
|
grid-column-gap: 10px;
|
||||||
|
align-items: center;
|
||||||
|
flex-grow: 1;
|
||||||
|
position: relative;
|
||||||
|
}
|
||||||
|
#home-link{
|
||||||
|
align-self: center;
|
||||||
|
color: #ffffff;
|
||||||
|
grid-area: home;
|
||||||
|
}
|
||||||
|
#site-search .search-box{
|
||||||
|
align-self:center;
|
||||||
|
height:25px;
|
||||||
|
border:0;
|
||||||
|
grid-area: search-bar;
|
||||||
|
flex-grow: 1;
|
||||||
|
}
|
||||||
|
#site-search .search-button{
|
||||||
|
align-self:center;
|
||||||
|
height:25px;
|
||||||
|
grid-area: search-button;
|
||||||
|
}
|
||||||
|
|
||||||
|
#site-search .filter-dropdown-toggle-button{
|
||||||
|
align-self:center;
|
||||||
|
height:25px;
|
||||||
|
grid-area: filter-button;
|
||||||
|
}
|
||||||
|
#site-search .playlist-form-toggle-button{
|
||||||
|
height:25px;
|
||||||
|
grid-area: playlist;
|
||||||
|
display: none;
|
||||||
|
}
|
||||||
|
#site-search .filter-dropdown-content{
|
||||||
|
position: absolute;
|
||||||
|
grid-area: dropdown;
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: auto auto;
|
||||||
|
white-space: nowrap;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 0px 10px 10px 10px;
|
||||||
|
border-width: 0px 1px 1px 1px;
|
||||||
|
border-style: solid;
|
||||||
|
border-color: var(--interface-border-color);
|
||||||
|
top: 0px;
|
||||||
|
z-index:1;
|
||||||
|
}
|
||||||
|
#filter-dropdown-toggle-cbox:not(:checked) + .filter-dropdown-content{
|
||||||
|
display: none;
|
||||||
|
}
|
||||||
|
#site-search .filter-dropdown-content h3{
|
||||||
|
grid-column:1 / span 2;
|
||||||
|
}
|
||||||
|
|
||||||
|
#playlist-edit{
|
||||||
|
align-self: center;
|
||||||
|
}
|
||||||
|
#local-playlists{
|
||||||
|
margin-right:5px;
|
||||||
|
color: #ffffff;
|
||||||
|
}
|
||||||
|
#playlist-name-selection{
|
||||||
|
height:25px;
|
||||||
|
border: 0px;
|
||||||
|
}
|
||||||
|
#playlist-add-button{
|
||||||
|
height:25px;
|
||||||
|
}
|
||||||
|
#item-selection-reset{
|
||||||
|
height:25px;
|
||||||
|
}
|
||||||
|
|
||||||
|
main{
|
||||||
|
flex-grow: 1;
|
||||||
|
padding-left: 5px;
|
||||||
|
padding-right: 5px;
|
||||||
|
padding-bottom: 20px;
|
||||||
|
}
|
||||||
|
#message-box{
|
||||||
|
position: fixed;
|
||||||
|
top: 50%;
|
||||||
|
left: 50%;
|
||||||
|
transform: translate(-50%, -50%);
|
||||||
|
border-style: outset;
|
||||||
|
padding: 20px;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
opacity: 0;
|
||||||
|
transition-property: opacity;
|
||||||
|
transition-duration: 0.3s;
|
||||||
|
}
|
||||||
|
|
||||||
|
.button{
|
||||||
|
text-align: center;
|
||||||
|
white-space: nowrap;
|
||||||
|
padding-left: 10px;
|
||||||
|
padding-right: 10px;
|
||||||
|
background-color: #f0f0f0;
|
||||||
|
color: black;
|
||||||
|
border: 1px solid #919191;
|
||||||
|
border-radius: 5px;
|
||||||
|
display: inline-flex;
|
||||||
|
justify-content: center;
|
||||||
|
align-items: center; /* center text */
|
||||||
|
font-size: 0.85rem;
|
||||||
|
-webkit-touch-callout: none;
|
||||||
|
-webkit-user-select: none;
|
||||||
|
-khtml-user-select: none;
|
||||||
|
-moz-user-select: none;
|
||||||
|
-ms-user-select: none;
|
||||||
|
user-select: none;
|
||||||
|
}
|
||||||
|
.button:hover{
|
||||||
|
background-color: #DCDCDC
|
||||||
|
}
|
||||||
|
.button:active{
|
||||||
|
background: #e9e9e9;
|
||||||
|
position: relative;
|
||||||
|
top: 1px;
|
||||||
|
text-shadow: none;
|
||||||
|
box-shadow: 0 1px 1px rgba(0, 0, 0, .3) inset;
|
||||||
|
}
|
||||||
|
|
||||||
|
.item-list{
|
||||||
|
display: grid;
|
||||||
|
grid-row-gap: 10px;
|
||||||
|
justify-content: center;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
.item-grid{
|
||||||
|
display: flex;
|
||||||
|
flex-wrap: wrap;
|
||||||
|
}
|
||||||
|
.item-grid > .playlist-item-box{
|
||||||
|
margin-right: 10px;
|
||||||
|
}
|
||||||
|
.item-grid > * {
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
.item-grid .horizontal-item-box .item{
|
||||||
|
width:370px;
|
||||||
|
}
|
||||||
|
.item-grid .vertical-item-box .item{
|
||||||
|
}
|
||||||
|
|
||||||
|
.item-box{
|
||||||
|
display: inline-flex;
|
||||||
|
flex-direction: row;
|
||||||
|
/* prevent overflow due to long titles with no spaces:
|
||||||
|
https://stackoverflow.com/a/43312314 */
|
||||||
|
min-width: 0;
|
||||||
|
}
|
||||||
|
.vertical-item-box{
|
||||||
|
}
|
||||||
|
.horizontal-item-box{
|
||||||
|
}
|
||||||
|
.item{
|
||||||
|
background-color:var(--interface-color);
|
||||||
|
text-decoration:none;
|
||||||
|
font-size: 0.8125rem;
|
||||||
|
color: #767676;
|
||||||
|
}
|
||||||
|
|
||||||
|
.horizontal-item-box .item {
|
||||||
|
flex-grow: 1;
|
||||||
|
display: grid;
|
||||||
|
align-content: start;
|
||||||
|
grid-template-columns: auto 1fr;
|
||||||
|
/* prevent overflow due to long titles with no spaces:
|
||||||
|
https://stackoverflow.com/a/43312314 */
|
||||||
|
min-width: 0;
|
||||||
|
}
|
||||||
|
.vertical-item-box .item{
|
||||||
|
width: 168px;
|
||||||
|
}
|
||||||
|
.thumbnail-box{
|
||||||
|
font-size: 0px; /* prevent newlines and blank space from creating gaps */
|
||||||
|
position: relative;
|
||||||
|
display: block;
|
||||||
|
}
|
||||||
|
.horizontal-item-box .thumbnail-box{
|
||||||
|
margin-right: 4px;
|
||||||
|
}
|
||||||
|
.no-description .thumbnail-box{
|
||||||
|
width: 168px;
|
||||||
|
height:94px;
|
||||||
|
}
|
||||||
|
.has-description .thumbnail-box{
|
||||||
|
width: 246px;
|
||||||
|
height:138px;
|
||||||
|
}
|
||||||
|
.video-item .thumbnail-info{
|
||||||
|
position: absolute;
|
||||||
|
bottom: 2px;
|
||||||
|
right: 2px;
|
||||||
|
opacity: .8;
|
||||||
|
color: #ffffff;
|
||||||
|
font-size: 0.8125rem;
|
||||||
|
background-color: #000000;
|
||||||
|
}
|
||||||
|
.playlist-item .thumbnail-info{
|
||||||
|
position: absolute;
|
||||||
|
right: 0px;
|
||||||
|
bottom: 0px;
|
||||||
|
height: 100%;
|
||||||
|
width: 50%;
|
||||||
|
text-align:center;
|
||||||
|
white-space: pre-line;
|
||||||
|
opacity: .8;
|
||||||
|
color: #cfcfcf;
|
||||||
|
font-size: 0.8125rem;
|
||||||
|
background-color: #000000;
|
||||||
|
}
|
||||||
|
.playlist-item .thumbnail-info span{ /* trick to vertically center the text */
|
||||||
|
position: absolute;
|
||||||
|
top: 50%;
|
||||||
|
transform: translate(-50%, -50%);
|
||||||
|
}
|
||||||
|
.thumbnail-img{ /* center it */
|
||||||
|
margin: auto;
|
||||||
|
display: block;
|
||||||
|
max-height: 100%;
|
||||||
|
max-width: 100%;
|
||||||
|
}
|
||||||
|
.horizontal-item-box .thumbnail-img{
|
||||||
|
height: 100%;
|
||||||
|
}
|
||||||
|
.item-metadata{
|
||||||
|
overflow: hidden;
|
||||||
|
}
|
||||||
|
.item .title{
|
||||||
|
min-width: 0;
|
||||||
|
line-height:1.25em;
|
||||||
|
max-height:3.75em;
|
||||||
|
overflow-y: hidden;
|
||||||
|
overflow-wrap: break-word;
|
||||||
|
|
||||||
|
color: var(--text-color);
|
||||||
|
font-size: 1rem;
|
||||||
|
font-weight: 500;
|
||||||
|
text-decoration:initial;
|
||||||
|
}
|
||||||
|
|
||||||
|
.stats{
|
||||||
|
list-style: none;
|
||||||
|
padding: 0px;
|
||||||
|
margin: 0px;
|
||||||
|
}
|
||||||
|
.horizontal-stats{
|
||||||
|
max-height:2.4em;
|
||||||
|
overflow:hidden;
|
||||||
|
}
|
||||||
|
.horizontal-stats > li{
|
||||||
|
display: inline;
|
||||||
|
}
|
||||||
|
|
||||||
|
.horizontal-stats > li::after{
|
||||||
|
content: " | ";
|
||||||
|
}
|
||||||
|
.horizontal-stats > li:last-child::after{
|
||||||
|
content: "";
|
||||||
|
}
|
||||||
|
|
||||||
|
.vertical-stats{
|
||||||
|
display: flex;
|
||||||
|
flex-direction: column;
|
||||||
|
}
|
||||||
|
.stats address{
|
||||||
|
display: inline;
|
||||||
|
}
|
||||||
|
.vertical-stats li{
|
||||||
|
max-height: 1.3em;
|
||||||
|
overflow: hidden;
|
||||||
|
}
|
||||||
|
|
||||||
|
.item-checkbox{
|
||||||
|
justify-self:start;
|
||||||
|
align-self:center;
|
||||||
|
height:30px;
|
||||||
|
width:30px;
|
||||||
|
min-width:30px;
|
||||||
|
margin: 0px;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
.page-button-row{
|
||||||
|
margin-bottom: 10px;
|
||||||
|
display: flex;
|
||||||
|
flex-wrap: wrap;
|
||||||
|
justify-self:center;
|
||||||
|
justify-content: center;
|
||||||
|
}
|
||||||
|
.page-button-row .page-button{
|
||||||
|
margin-top: 10px;
|
||||||
|
width: 40px;
|
||||||
|
height: 40px;
|
||||||
|
}
|
||||||
|
.next-previous-button-row{
|
||||||
|
margin: 10px 0px;
|
||||||
|
display: flex;
|
||||||
|
justify-self:center;
|
||||||
|
justify-content: center;
|
||||||
|
height: 40px;
|
||||||
|
}
|
||||||
|
.page-button{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
border-style: outset;
|
||||||
|
border-width: 2px;
|
||||||
|
font-weight: bold;
|
||||||
|
text-align: center;
|
||||||
|
padding: 5px;
|
||||||
|
}
|
||||||
|
.next-page:nth-child(2){ /* only if there's also a previous page button */
|
||||||
|
margin-left: 10px;
|
||||||
|
}
|
||||||
|
.sort-button{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 2px;
|
||||||
|
justify-self: start;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* error page stuff */
|
||||||
|
h1{
|
||||||
|
font-size: 2rem;
|
||||||
|
font-weight: normal;
|
||||||
|
}
|
||||||
|
#error-box, #error-message{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
width: 80%;
|
||||||
|
margin: auto;
|
||||||
|
margin-top: 20px;
|
||||||
|
padding: 5px;
|
||||||
|
}
|
||||||
|
#error-message{
|
||||||
|
white-space: pre-wrap;
|
||||||
|
}
|
||||||
|
#error-box > div, #error-box > p, #error-box > h1{
|
||||||
|
white-space: pre-wrap;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
.code-box{
|
||||||
|
white-space: pre-wrap;
|
||||||
|
padding: 5px;
|
||||||
|
border-style:solid;
|
||||||
|
border-width:1px;
|
||||||
|
border-radius:5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media (max-width:950px){
|
||||||
|
#site-search{
|
||||||
|
grid-template-areas: "home search-bar search-button filter-button playlist"
|
||||||
|
". dropdown dropdown dropdown .";
|
||||||
|
}
|
||||||
|
#site-search .filter-dropdown-content{
|
||||||
|
justify-self: end;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
@media (max-width:920px){
|
||||||
|
header{
|
||||||
|
flex-direction:column;
|
||||||
|
}
|
||||||
|
#site-search{
|
||||||
|
margin-bottom: 5px;
|
||||||
|
width: 100%;
|
||||||
|
align-self: center;
|
||||||
|
}
|
||||||
|
#playlist-edit > *{
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
#playlist-form-toggle-cbox:not(:checked) + #playlist-edit{
|
||||||
|
display: none;
|
||||||
|
}
|
||||||
|
#site-search .playlist-form-toggle-button{
|
||||||
|
display: inline-flex;
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
|
/* convert big items (has-description) to vertical format. e.g. search results */
|
||||||
|
@media (max-width:600px){
|
||||||
|
.has-description.horizontal-item-box .item {
|
||||||
|
flex-grow: unset;
|
||||||
|
display: block;
|
||||||
|
width: 246px;
|
||||||
|
}
|
||||||
|
.has-description.horizontal-item-box .thumbnail-box{
|
||||||
|
margin-right: 0px;
|
||||||
|
}
|
||||||
|
.has-description.horizontal-item-box .thumbnail-img{
|
||||||
|
height: 100%;
|
||||||
|
}
|
||||||
|
|
||||||
|
.has-description .horizontal-stats{
|
||||||
|
max-height: unset;
|
||||||
|
overflow:hidden;
|
||||||
|
}
|
||||||
|
.has-description .horizontal-stats > li{
|
||||||
|
display: initial;
|
||||||
|
}
|
||||||
|
|
||||||
|
.has-description .horizontal-stats > li::after{
|
||||||
|
content: "";
|
||||||
|
}
|
||||||
|
|
||||||
|
.has-description .horizontal-stats{
|
||||||
|
display: flex;
|
||||||
|
flex-direction: column;
|
||||||
|
}
|
||||||
|
.has-description .horizontal-stats li{
|
||||||
|
max-height: 1.3em;
|
||||||
|
overflow: hidden;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
@media (max-width:500px){
|
||||||
|
#site-search{
|
||||||
|
grid-template-columns: 0fr auto auto auto;
|
||||||
|
grid-template-rows: 40px 40px 0fr;
|
||||||
|
grid-template-areas: "home search-bar search-bar search-bar"
|
||||||
|
". search-button filter-button playlist"
|
||||||
|
". dropdown dropdown dropdown";
|
||||||
|
}
|
||||||
|
#site-search .filter-dropdown-content{
|
||||||
|
justify-self: center;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
@media (max-width:400px) {
|
||||||
|
.horizontal-item-box.no-description .thumbnail-box{
|
||||||
|
width: 120px;
|
||||||
|
}
|
||||||
|
.horizontal-item-box.no-description .thumbnail-img{
|
||||||
|
object-fit: scale-down;
|
||||||
|
object-position: center;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
@media (max-width: 300px){
|
||||||
|
#site-search{
|
||||||
|
grid-template-columns: auto auto auto;
|
||||||
|
grid-template-areas: "home search-bar search-bar"
|
||||||
|
"search-button filter-button playlist"
|
||||||
|
"dropdown dropdown dropdown";
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
7
youtube/templates/status.html
Normal file
7
youtube/templates/status.html
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
{% set page_title = (title if (title is defined) else 'Status') %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
{{ message }}
|
||||||
|
{% endblock %}
|
||||||
|
|
||||||
160
youtube/templates/subscription_manager.html
Normal file
160
youtube/templates/subscription_manager.html
Normal file
@@ -0,0 +1,160 @@
|
|||||||
|
{% set page_title = 'Subscription Manager' %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% block style %}
|
||||||
|
.import-export{
|
||||||
|
display: flex;
|
||||||
|
flex-direction: row;
|
||||||
|
flex-wrap: wrap;
|
||||||
|
padding-top: 10px;
|
||||||
|
}
|
||||||
|
.subscriptions-import-export-form{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
display: flex;
|
||||||
|
flex-direction: column;
|
||||||
|
align-items: flex-start;
|
||||||
|
max-width: 600px;
|
||||||
|
padding:10px;
|
||||||
|
margin-left: 10px;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
.subscriptions-import-export-form h2{
|
||||||
|
font-size: 1.25rem;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.import-export-submit-button{
|
||||||
|
margin-top:15px;
|
||||||
|
align-self: flex-end;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
.subscriptions-export-links{
|
||||||
|
margin: 0px 0px 0px 20px;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
list-style: none;
|
||||||
|
max-width: 300px;
|
||||||
|
padding:10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.sub-list-controls{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding:15px;
|
||||||
|
padding-top: 0px;
|
||||||
|
padding-left: 5px;
|
||||||
|
}
|
||||||
|
.sub-list-controls > *{
|
||||||
|
margin-left: 10px;
|
||||||
|
margin-top: 15px;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
.tag-group-list{
|
||||||
|
list-style: none;
|
||||||
|
margin-left: 10px;
|
||||||
|
margin-right: 10px;
|
||||||
|
padding: 0px;
|
||||||
|
}
|
||||||
|
.tag-group{
|
||||||
|
border-style: solid;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.sub-list{
|
||||||
|
list-style: none;
|
||||||
|
padding:10px;
|
||||||
|
column-width: 300px;
|
||||||
|
column-gap: 40px;
|
||||||
|
}
|
||||||
|
.sub-list-item{
|
||||||
|
display:flex;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
break-inside:avoid;
|
||||||
|
}
|
||||||
|
.sub-list-item:not(.muted){
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
}
|
||||||
|
.tag-list{
|
||||||
|
margin-left:15px;
|
||||||
|
font-weight:bold;
|
||||||
|
}
|
||||||
|
.sub-list-item-name{
|
||||||
|
margin-left:15px;
|
||||||
|
}
|
||||||
|
.sub-list-checkbox{
|
||||||
|
height: 1.5em;
|
||||||
|
min-width: 1.5em; // need min-width otherwise browser doesn't respect the width and squishes the checkbox down when there's too many tags
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
|
||||||
|
{% macro subscription_list(sub_list) %}
|
||||||
|
{% for subscription in sub_list %}
|
||||||
|
<li class="sub-list-item {{ 'muted' if subscription['muted'] else '' }}">
|
||||||
|
<input class="sub-list-checkbox" name="channel_ids" value="{{ subscription['channel_id'] }}" form="subscription-manager-form" type="checkbox">
|
||||||
|
<a href="{{ subscription['channel_url'] }}" class="sub-list-item-name" title="{{ subscription['channel_name'] }}">{{ subscription['channel_name'] }}</a>
|
||||||
|
<span class="tag-list">{{ ', '.join(subscription['tags']) }}</span>
|
||||||
|
</li>
|
||||||
|
{% endfor %}
|
||||||
|
{% endmacro %}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<div class="import-export">
|
||||||
|
<form class="subscriptions-import-export-form" enctype="multipart/form-data" action="/youtube.com/import_subscriptions" method="POST">
|
||||||
|
<h2>Import subscriptions</h2>
|
||||||
|
<input type="file" id="subscriptions-import" accept="application/json, application/xml, text/x-opml, text/csv" name="subscriptions_file" required>
|
||||||
|
<input type="submit" value="Import" class="import-export-submit-button">
|
||||||
|
</form>
|
||||||
|
|
||||||
|
<form class="subscriptions-import-export-form" action="/youtube.com/export_subscriptions" method="POST">
|
||||||
|
<h2>Export subscriptions</h2>
|
||||||
|
<div>
|
||||||
|
<select id="export-type" name="export_format" title="Export format">
|
||||||
|
<option value="json_newpipe">JSON (NewPipe)</option>
|
||||||
|
<option value="json_google_takeout">JSON (Old Google Takeout Format)</option>
|
||||||
|
<option value="opml">OPML (RSS, no tags)</option>
|
||||||
|
</select>
|
||||||
|
<label for="include-muted">Include muted</label>
|
||||||
|
<input id="include-muted" type="checkbox" name="include_muted" checked>
|
||||||
|
</div>
|
||||||
|
<input type="submit" value="Export" class="import-export-submit-button">
|
||||||
|
</form>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<hr>
|
||||||
|
|
||||||
|
<form id="subscription-manager-form" class="sub-list-controls" method="POST">
|
||||||
|
{% if group_by_tags %}
|
||||||
|
<a class="sort-button" href="/https://www.youtube.com/subscription_manager?group_by_tags=0">Don't group</a>
|
||||||
|
{% else %}
|
||||||
|
<a class="sort-button" href="/https://www.youtube.com/subscription_manager?group_by_tags=1">Group by tags</a>
|
||||||
|
{% endif %}
|
||||||
|
<input type="text" name="tags" placeholder="Comma-separated tags">
|
||||||
|
<button type="submit" name="action" value="add_tags">Add tags</button>
|
||||||
|
<button type="submit" name="action" value="remove_tags">Remove tags</button>
|
||||||
|
<button type="submit" name="action" value="unsubscribe_verify">Unsubscribe</button>
|
||||||
|
<button type="submit" name="action" value="mute">Mute</button>
|
||||||
|
<button type="submit" name="action" value="unmute">Unmute</button>
|
||||||
|
<input type="reset" value="Clear Selection">
|
||||||
|
</form>
|
||||||
|
|
||||||
|
|
||||||
|
{% if group_by_tags %}
|
||||||
|
<ul class="tag-group-list">
|
||||||
|
{% for tag_name, sub_list in tag_groups %}
|
||||||
|
<li class="tag-group">
|
||||||
|
<h2 class="tag-group-name">{{ tag_name }}</h2>
|
||||||
|
<ol class="sub-list">
|
||||||
|
{{ subscription_list(sub_list) }}
|
||||||
|
</ol>
|
||||||
|
</li>
|
||||||
|
{% endfor %}
|
||||||
|
</ul>
|
||||||
|
{% else %}
|
||||||
|
<ol class="sub-list">
|
||||||
|
{{ subscription_list(sub_list) }}
|
||||||
|
</ol>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% endblock main %}
|
||||||
180
youtube/templates/subscriptions.html
Normal file
180
youtube/templates/subscriptions.html
Normal file
@@ -0,0 +1,180 @@
|
|||||||
|
{% if current_tag %}
|
||||||
|
{% set page_title = 'Subscriptions - ' + current_tag %}
|
||||||
|
{% else %}
|
||||||
|
{% set page_title = 'Subscriptions' %}
|
||||||
|
{% endif %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% import "common_elements.html" as common_elements %}
|
||||||
|
|
||||||
|
{% block style %}
|
||||||
|
main{
|
||||||
|
display:flex;
|
||||||
|
flex-direction: row;
|
||||||
|
padding-right:0px;
|
||||||
|
}
|
||||||
|
.video-section{
|
||||||
|
flex-grow: 1;
|
||||||
|
padding-left: 10px;
|
||||||
|
padding-top: 10px;
|
||||||
|
}
|
||||||
|
.current-tag{
|
||||||
|
margin-bottom:10px;
|
||||||
|
}
|
||||||
|
.video-section .page-button-row{
|
||||||
|
justify-content: center;
|
||||||
|
}
|
||||||
|
.subscriptions-sidebar-fixed-container{
|
||||||
|
display: none;
|
||||||
|
}
|
||||||
|
.subscriptions-sidebar{
|
||||||
|
width: 310px;
|
||||||
|
max-width: 100%;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
border-left: 1px solid;
|
||||||
|
border-left-color: var(--interface-border-color);
|
||||||
|
}
|
||||||
|
.sidebar-links{
|
||||||
|
display:flex;
|
||||||
|
justify-content: space-between;
|
||||||
|
padding-left:10px;
|
||||||
|
padding-right: 10px;
|
||||||
|
margin-top: 10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.sidebar-list{
|
||||||
|
list-style: none;
|
||||||
|
padding-left:10px;
|
||||||
|
padding-right: 10px;
|
||||||
|
}
|
||||||
|
.sidebar-list-item{
|
||||||
|
display:flex;
|
||||||
|
justify-content: space-between;
|
||||||
|
margin-bottom: 5px;
|
||||||
|
}
|
||||||
|
.sub-refresh-list .sidebar-item-name{
|
||||||
|
text-overflow: clip;
|
||||||
|
white-space: nowrap;
|
||||||
|
overflow: hidden;
|
||||||
|
max-width: 200px;
|
||||||
|
}
|
||||||
|
@media (max-width:750px){
|
||||||
|
main{
|
||||||
|
display: initial;
|
||||||
|
position: relative;
|
||||||
|
padding-bottom: 70px;
|
||||||
|
}
|
||||||
|
.subscriptions-sidebar{
|
||||||
|
position: absolute;
|
||||||
|
right: 0px;
|
||||||
|
top: 0px;
|
||||||
|
}
|
||||||
|
#subscriptions-sidebar-toggle-cbox:not(:checked) + .subscriptions-sidebar{
|
||||||
|
visibility: hidden;
|
||||||
|
}
|
||||||
|
.subscriptions-sidebar-fixed-container{
|
||||||
|
display: flex;
|
||||||
|
align-items: center;
|
||||||
|
position: fixed;
|
||||||
|
bottom: 0px;
|
||||||
|
right: 0px;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
height: 70px;
|
||||||
|
width: 310px;
|
||||||
|
max-width: 100%;
|
||||||
|
border-width: 1px 0px 0px 1px;
|
||||||
|
border-style: solid;
|
||||||
|
border-color: var(--interface-border-color);
|
||||||
|
}
|
||||||
|
.subscriptions-sidebar-toggle-button{
|
||||||
|
display: block;
|
||||||
|
visibility: visible;
|
||||||
|
height: 60px;
|
||||||
|
width: 60px;
|
||||||
|
opacity: 0.75;
|
||||||
|
margin-left: auto;
|
||||||
|
}
|
||||||
|
.subscriptions-sidebar-toggle-button .button{
|
||||||
|
width:100%;
|
||||||
|
height:100%;
|
||||||
|
white-space: pre-wrap;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<div class="video-section">
|
||||||
|
{% if current_tag %}
|
||||||
|
<h2 class="current-tag">{{ current_tag }}</h2>
|
||||||
|
{% endif %}
|
||||||
|
<nav class="item-grid">
|
||||||
|
{% for video_info in videos %}
|
||||||
|
{{ common_elements.item(video_info) }}
|
||||||
|
{% endfor %}
|
||||||
|
</nav>
|
||||||
|
|
||||||
|
<nav class="page-button-row">
|
||||||
|
{{ common_elements.page_buttons(num_pages, '/youtube.com/subscriptions', parameters_dictionary) }}
|
||||||
|
</nav>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<input id="subscriptions-sidebar-toggle-cbox" type="checkbox" hidden>
|
||||||
|
<div class="subscriptions-sidebar">
|
||||||
|
<div class="subscriptions-sidebar-fixed-container">
|
||||||
|
<div class="subscriptions-sidebar-toggle-button">
|
||||||
|
<label class="button" for="subscriptions-sidebar-toggle-cbox">Toggle
|
||||||
|
Sidebar</label>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
<div class="sidebar-links">
|
||||||
|
<a href="/youtube.com/subscription_manager" class="sub-manager-link">Subscription Manager</a>
|
||||||
|
<form method="POST" class="refresh-all">
|
||||||
|
<input type="submit" value="Check All">
|
||||||
|
<input type="hidden" name="action" value="refresh">
|
||||||
|
<input type="hidden" name="type" value="all">
|
||||||
|
</form>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<hr>
|
||||||
|
|
||||||
|
<ol class="sidebar-list tags">
|
||||||
|
{% if current_tag %}
|
||||||
|
<li class="sidebar-list-item">
|
||||||
|
<a href="/youtube.com/subscriptions" class="sidebar-item-name">Any tag</a>
|
||||||
|
</li>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% for tag in tags %}
|
||||||
|
<li class="sidebar-list-item">
|
||||||
|
{% if tag == current_tag %}
|
||||||
|
<span class="sidebar-item-name">{{ tag }}</span>
|
||||||
|
{% else %}
|
||||||
|
<a href="?tag={{ tag|urlencode }}" class="sidebar-item-name">{{ tag }}</a>
|
||||||
|
{% endif %}
|
||||||
|
<form method="POST" class="sidebar-item-refresh">
|
||||||
|
<input type="submit" value="Check">
|
||||||
|
<input type="hidden" name="action" value="refresh">
|
||||||
|
<input type="hidden" name="type" value="tag">
|
||||||
|
<input type="hidden" name="tag_name" value="{{ tag }}">
|
||||||
|
</form>
|
||||||
|
</li>
|
||||||
|
{% endfor %}
|
||||||
|
</ol>
|
||||||
|
|
||||||
|
<hr>
|
||||||
|
|
||||||
|
<ol class="sidebar-list sub-refresh-list">
|
||||||
|
{% for subscription in subscription_list %}
|
||||||
|
<li class="sidebar-list-item {{ 'muted' if subscription['muted'] else '' }}">
|
||||||
|
<a href="{{ subscription['channel_url'] }}" class="sidebar-item-name" title="{{ subscription['channel_name'] }}">{{ subscription['channel_name'] }}</a>
|
||||||
|
<form method="POST" class="sidebar-item-refresh">
|
||||||
|
<input type="submit" value="Check">
|
||||||
|
<input type="hidden" name="action" value="refresh">
|
||||||
|
<input type="hidden" name="type" value="channel">
|
||||||
|
<input type="hidden" name="channel_id" value="{{ subscription['channel_id'] }}">
|
||||||
|
</form>
|
||||||
|
</li>
|
||||||
|
{% endfor %}
|
||||||
|
</ol>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
{% endblock main %}
|
||||||
9
youtube/templates/subscriptions.xml
Normal file
9
youtube/templates/subscriptions.xml
Normal file
@@ -0,0 +1,9 @@
|
|||||||
|
<opml version="1.1">
|
||||||
|
<body>
|
||||||
|
<outline text="YouTube Subscriptions" title="YouTube Subscriptions">
|
||||||
|
{% for sub in sub_list %}
|
||||||
|
<outline text="{{sub['channel_name']}}" title="{{sub['channel_name']}}" type="rss" xmlUrl="https://www.youtube.com/feeds/videos.xml?channel_id={{sub['channel_id']}}" />
|
||||||
|
{%- endfor %}
|
||||||
|
</outline>
|
||||||
|
</body>
|
||||||
|
</opml>
|
||||||
19
youtube/templates/unsubscribe_verify.html
Normal file
19
youtube/templates/unsubscribe_verify.html
Normal file
@@ -0,0 +1,19 @@
|
|||||||
|
{% set page_title = 'Unsubscribe?' %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
<span>Are you sure you want to unsubscribe from these channels?</span>
|
||||||
|
<form class="subscriptions-import-form" action="/youtube.com/subscription_manager" method="POST">
|
||||||
|
{% for channel_id, channel_name in unsubscribe_list %}
|
||||||
|
<input type="hidden" name="channel_ids" value="{{ channel_id }}">
|
||||||
|
{% endfor %}
|
||||||
|
|
||||||
|
<input type="hidden" name="action" value="unsubscribe">
|
||||||
|
<input type="submit" value="Yes, unsubscribe">
|
||||||
|
</form>
|
||||||
|
<ul>
|
||||||
|
{% for channel_id, channel_name in unsubscribe_list %}
|
||||||
|
<li><a href="{{ '/https://www.youtube.com/channel/' + channel_id }}" title="{{ channel_name }}">{{ channel_name }}</a></li>
|
||||||
|
{% endfor %}
|
||||||
|
</ul>
|
||||||
|
{% endblock main %}
|
||||||
694
youtube/templates/watch.html
Normal file
694
youtube/templates/watch.html
Normal file
@@ -0,0 +1,694 @@
|
|||||||
|
{% set page_title = title %}
|
||||||
|
{% extends "base.html" %}
|
||||||
|
{% import "common_elements.html" as common_elements %}
|
||||||
|
{% import "comments.html" as comments with context %}
|
||||||
|
{% block style %}
|
||||||
|
body {
|
||||||
|
--theater_video_target_width: {{ theater_video_target_width }};
|
||||||
|
--video_height: {{ video_height }};
|
||||||
|
--video_width: {{ video_width }};
|
||||||
|
--plyr-control-spacing-num: {{ '3' if video_height < 240 else '10' }};
|
||||||
|
--screen-width: calc(100vw - 25px);
|
||||||
|
}
|
||||||
|
details > summary{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
border-style: outset;
|
||||||
|
border-width: 2px;
|
||||||
|
font-weight: bold;
|
||||||
|
padding: 4px;
|
||||||
|
}
|
||||||
|
details > summary:hover{
|
||||||
|
text-decoration: underline;
|
||||||
|
}
|
||||||
|
|
||||||
|
.playability-error{
|
||||||
|
height: 360px;
|
||||||
|
max-width: 640px;
|
||||||
|
grid-column: 2;
|
||||||
|
background-color: var(--video-background-color);
|
||||||
|
text-align:center;
|
||||||
|
}
|
||||||
|
.playability-error span{
|
||||||
|
position: relative;
|
||||||
|
top: 50%;
|
||||||
|
transform: translate(-50%, -50%);
|
||||||
|
white-space: pre-wrap;
|
||||||
|
}
|
||||||
|
|
||||||
|
.live-url-choices{
|
||||||
|
min-height: 360px;
|
||||||
|
max-width: 640px;
|
||||||
|
grid-column: 2;
|
||||||
|
background-color: var(--video-background-color);
|
||||||
|
padding: 25px 0px 0px 25px;
|
||||||
|
}
|
||||||
|
.live-url-choices ol{
|
||||||
|
list-style: none;
|
||||||
|
padding:0px;
|
||||||
|
margin:0px;
|
||||||
|
margin-top: 15px;
|
||||||
|
}
|
||||||
|
.live-url-choices input{
|
||||||
|
max-width: 400px;
|
||||||
|
width: 100%;
|
||||||
|
}
|
||||||
|
.url-choice-label{
|
||||||
|
display: inline-block;
|
||||||
|
width: 150px;
|
||||||
|
}
|
||||||
|
|
||||||
|
{% if settings.theater_mode %}
|
||||||
|
#video-container{
|
||||||
|
grid-column: 1 / span 5;
|
||||||
|
justify-self: center;
|
||||||
|
max-width: 100%;
|
||||||
|
max-height: calc(var(--screen-width)*var(--video_height)/var(--video_width));
|
||||||
|
height: calc(var(--video_height)*1px);
|
||||||
|
width: calc(var(--theater_video_target_width)*1px);
|
||||||
|
margin-bottom: 10px;
|
||||||
|
--plyr-video-background: rgba(0, 0, 0, 0);
|
||||||
|
}
|
||||||
|
|
||||||
|
/*
|
||||||
|
Really just want this as another max-height variable in
|
||||||
|
#video-container, but have to use media queries instead because min
|
||||||
|
is only supported by newer browsers:
|
||||||
|
https://stackoverflow.com/questions/30568424/min-max-width-height-with-multiple-values
|
||||||
|
|
||||||
|
Because CSS is extra special, we cannot change
|
||||||
|
this max-height value using javascript when the video resolution
|
||||||
|
is changed, so we use this technique:
|
||||||
|
https://stackoverflow.com/a/39610272
|
||||||
|
*/
|
||||||
|
|
||||||
|
{% set heights = [] %}
|
||||||
|
|
||||||
|
{% for src in uni_sources+pair_sources %}
|
||||||
|
{% if src['height'] not in heights %}
|
||||||
|
{% do heights.append(src['height']) %}
|
||||||
|
@media(max-height:{{ src['height'] + 50 }}px){
|
||||||
|
#video-container.h{{ src['height'] }}{
|
||||||
|
height: calc(100vh - 50px); /* 50px is height of header */
|
||||||
|
}
|
||||||
|
}
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
|
||||||
|
video{
|
||||||
|
background-color: var(--video-background-color);
|
||||||
|
}
|
||||||
|
#video-container > video, #video-container > .plyr{
|
||||||
|
width: 100%;
|
||||||
|
height: 100%;
|
||||||
|
}
|
||||||
|
.side-videos{
|
||||||
|
grid-row: 2 /span 3;
|
||||||
|
max-width: 400px;
|
||||||
|
}
|
||||||
|
.video-info{
|
||||||
|
max-width: 640px;
|
||||||
|
}
|
||||||
|
{% else %}
|
||||||
|
#video-container{
|
||||||
|
grid-column: 2;
|
||||||
|
}
|
||||||
|
#video-container, video{
|
||||||
|
height: calc(640px*var(--video_height)/var(--video_width)) !important;
|
||||||
|
width: 640px !important;
|
||||||
|
}
|
||||||
|
.plyr {
|
||||||
|
height: 100%;
|
||||||
|
width: 100%;
|
||||||
|
}
|
||||||
|
.side-videos{
|
||||||
|
grid-row: 1 /span 4;
|
||||||
|
}
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
main{
|
||||||
|
display:grid;
|
||||||
|
/* minmax(0, 1fr) needed instead of 1fr for Chrome: https://stackoverflow.com/a/43312314 */
|
||||||
|
grid-template-columns: minmax(0, 1fr) 640px 40px 400px minmax(0, 1fr);
|
||||||
|
grid-template-rows: auto auto auto auto;
|
||||||
|
align-content: start;
|
||||||
|
padding-left: 0px;
|
||||||
|
padding-right: 0px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.video-info{
|
||||||
|
grid-column: 2;
|
||||||
|
grid-row: 2;
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: 1fr 1fr;
|
||||||
|
align-content: start;
|
||||||
|
grid-template-areas:
|
||||||
|
"v-title v-title"
|
||||||
|
"v-labels v-labels"
|
||||||
|
"v-uploader v-views"
|
||||||
|
"v-date v-likes-dislikes"
|
||||||
|
"external-player-controls v-checkbox"
|
||||||
|
"v-direct-link v-direct-link"
|
||||||
|
"v-download v-download"
|
||||||
|
"v-description v-description"
|
||||||
|
"v-music-list v-music-list"
|
||||||
|
"v-more-info v-more-info";
|
||||||
|
}
|
||||||
|
.video-info > .title{
|
||||||
|
grid-area: v-title;
|
||||||
|
min-width: 0;
|
||||||
|
}
|
||||||
|
.video-info > .labels{
|
||||||
|
grid-area: v-labels;
|
||||||
|
justify-self:start;
|
||||||
|
list-style: none;
|
||||||
|
padding: 0px;
|
||||||
|
margin: 5px 0px;
|
||||||
|
}
|
||||||
|
.video-info > .labels:empty{
|
||||||
|
margin: 0px;
|
||||||
|
}
|
||||||
|
.labels > li{
|
||||||
|
display: inline;
|
||||||
|
margin-right:5px;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 2px 5px;
|
||||||
|
border-style: solid;
|
||||||
|
border-width: 1px;
|
||||||
|
}
|
||||||
|
.video-info > address{
|
||||||
|
grid-area: v-uploader;
|
||||||
|
justify-self: start;
|
||||||
|
}
|
||||||
|
.video-info > .views{
|
||||||
|
grid-area: v-views;
|
||||||
|
justify-self:end;
|
||||||
|
}
|
||||||
|
.video-info > time{
|
||||||
|
grid-area: v-date;
|
||||||
|
justify-self:start;
|
||||||
|
}
|
||||||
|
.video-info > .likes-dislikes{
|
||||||
|
grid-area: v-likes-dislikes;
|
||||||
|
justify-self:end;
|
||||||
|
}
|
||||||
|
.video-info > .external-player-controls{
|
||||||
|
grid-area: external-player-controls;
|
||||||
|
justify-self: start;
|
||||||
|
margin-bottom: 8px;
|
||||||
|
}
|
||||||
|
#speed-control{
|
||||||
|
width: 65px;
|
||||||
|
text-align: center;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
color: var(--text-color);
|
||||||
|
}
|
||||||
|
.video-info > .checkbox{
|
||||||
|
grid-area: v-checkbox;
|
||||||
|
justify-self:end;
|
||||||
|
align-self: start;
|
||||||
|
height: 25px;
|
||||||
|
width: 25px;
|
||||||
|
}
|
||||||
|
.video-info > .direct-link{
|
||||||
|
grid-area: v-direct-link;
|
||||||
|
margin-bottom: 8px;
|
||||||
|
}
|
||||||
|
.video-info > .download-dropdown{
|
||||||
|
grid-area: v-download;
|
||||||
|
}
|
||||||
|
.video-info > .description{
|
||||||
|
background-color:var(--interface-color);
|
||||||
|
margin-top:8px;
|
||||||
|
white-space: pre-wrap;
|
||||||
|
min-width: 0;
|
||||||
|
word-wrap: break-word;
|
||||||
|
grid-area: v-description;
|
||||||
|
padding: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.music-list{
|
||||||
|
grid-area: v-music-list;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding-bottom: 7px;
|
||||||
|
}
|
||||||
|
.music-list table,th,td{
|
||||||
|
border: 1px solid;
|
||||||
|
}
|
||||||
|
.music-list th,td{
|
||||||
|
padding-left:4px;
|
||||||
|
padding-right:5px;
|
||||||
|
}
|
||||||
|
.music-list caption{
|
||||||
|
text-align:left;
|
||||||
|
font-weight:bold;
|
||||||
|
margin-bottom:5px;
|
||||||
|
}
|
||||||
|
.more-info{
|
||||||
|
grid-area: v-more-info;
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
}
|
||||||
|
.more-info > summary{
|
||||||
|
font-weight: normal;
|
||||||
|
border-width: 1px 0px;
|
||||||
|
border-style: solid;
|
||||||
|
}
|
||||||
|
.more-info-content{
|
||||||
|
padding: 5px;
|
||||||
|
}
|
||||||
|
.more-info-content p{
|
||||||
|
margin: 8px 0px;
|
||||||
|
}
|
||||||
|
.comments-area-outer{
|
||||||
|
grid-column: 2;
|
||||||
|
grid-row: 3;
|
||||||
|
margin-top:10px;
|
||||||
|
}
|
||||||
|
.comments-disabled{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 5px;
|
||||||
|
font-weight: bold;
|
||||||
|
}
|
||||||
|
.comments-area-inner{
|
||||||
|
padding-top: 10px;
|
||||||
|
}
|
||||||
|
.comment{
|
||||||
|
max-width:640px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.side-videos{
|
||||||
|
list-style: none;
|
||||||
|
grid-column: 4;
|
||||||
|
max-width: 640px;
|
||||||
|
}
|
||||||
|
#transcript-details{
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
table#transcript-table {
|
||||||
|
border-collapse: collapse;
|
||||||
|
width: 100%;
|
||||||
|
}
|
||||||
|
table#transcript-table td, th {
|
||||||
|
border: 1px solid #dddddd;
|
||||||
|
}
|
||||||
|
div#transcript-div {
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 5px;
|
||||||
|
}
|
||||||
|
.playlist{
|
||||||
|
border-style: solid;
|
||||||
|
border-width: 2px;
|
||||||
|
border-color: lightgray;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
.playlist-header{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 3px;
|
||||||
|
border-bottom-style: solid;
|
||||||
|
border-bottom-width: 2px;
|
||||||
|
border-bottom-color: lightgray;
|
||||||
|
}
|
||||||
|
.playlist-header h3{
|
||||||
|
margin: 2px;
|
||||||
|
}
|
||||||
|
.playlist-metadata{
|
||||||
|
list-style: none;
|
||||||
|
padding: 0px;
|
||||||
|
margin: 0px;
|
||||||
|
}
|
||||||
|
.playlist-metadata li{
|
||||||
|
display: inline;
|
||||||
|
margin: 2px;
|
||||||
|
}
|
||||||
|
.playlist-videos{
|
||||||
|
height: 300px;
|
||||||
|
overflow-y: scroll;
|
||||||
|
display: grid;
|
||||||
|
grid-auto-rows: 90px;
|
||||||
|
grid-row-gap: 10px;
|
||||||
|
padding-top: 10px;
|
||||||
|
}
|
||||||
|
.autoplay-toggle-container{
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
.related-videos-inner{
|
||||||
|
padding-top: 10px;
|
||||||
|
display: grid;
|
||||||
|
grid-auto-rows: 90px;
|
||||||
|
grid-row-gap: 10px;
|
||||||
|
}
|
||||||
|
.thumbnail-box{ /* overides rule in shared.css */
|
||||||
|
height: 90px !important;
|
||||||
|
width: 120px !important;
|
||||||
|
}
|
||||||
|
|
||||||
|
.download-dropdown-content{
|
||||||
|
background-color: var(--interface-color);
|
||||||
|
padding: 10px;
|
||||||
|
list-style: none;
|
||||||
|
margin: 0px;
|
||||||
|
}
|
||||||
|
li.download-format{
|
||||||
|
margin-bottom: 7px;
|
||||||
|
}
|
||||||
|
.download-link{
|
||||||
|
display: block;
|
||||||
|
background-color: rgba(var(--link-color-rgb), 0.07);
|
||||||
|
}
|
||||||
|
.download-link:visited{
|
||||||
|
background-color: rgba(var(--visited-link-color-rgb), 0.07);
|
||||||
|
}
|
||||||
|
.format-attributes{
|
||||||
|
list-style: none;
|
||||||
|
padding: 0px;
|
||||||
|
margin: 0px;
|
||||||
|
display: flex;
|
||||||
|
flex-direction: row;
|
||||||
|
flex-wrap: wrap;
|
||||||
|
}
|
||||||
|
.format-attributes li{
|
||||||
|
white-space: nowrap;
|
||||||
|
max-height: 1.2em;
|
||||||
|
}
|
||||||
|
.format-ext{
|
||||||
|
width: 60px;
|
||||||
|
}
|
||||||
|
.format-video-quality{
|
||||||
|
width: 140px;
|
||||||
|
}
|
||||||
|
.format-audio-quality{
|
||||||
|
width: 120px;
|
||||||
|
}
|
||||||
|
.format-file-size{
|
||||||
|
width: 80px;
|
||||||
|
}
|
||||||
|
.format-codecs{
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Put related vids below videos when window is too small */
|
||||||
|
/* 1100px instead of 1080 because W3C is full of idiots who include scrollbar width */
|
||||||
|
@media (max-width:1100px){
|
||||||
|
main{
|
||||||
|
grid-template-columns: minmax(0, 1fr) 640px 0 minmax(0, 1fr);
|
||||||
|
}
|
||||||
|
.side-videos{
|
||||||
|
margin-top: 10px;
|
||||||
|
grid-column: 2;
|
||||||
|
grid-row: 3;
|
||||||
|
width: initial;
|
||||||
|
}
|
||||||
|
.comments-area-outer{
|
||||||
|
grid-row: 4;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
@media (max-width:660px){
|
||||||
|
main{
|
||||||
|
grid-template-columns: 5px minmax(0, 1fr) 0 5px;
|
||||||
|
}
|
||||||
|
.format-attributes{
|
||||||
|
display: grid;
|
||||||
|
grid-template-columns: repeat(auto-fill, 140px);
|
||||||
|
}
|
||||||
|
.format-codecs{
|
||||||
|
grid-column: auto / span 2;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
@media (max-width:500px){
|
||||||
|
.video-info{
|
||||||
|
grid-template-areas:
|
||||||
|
"v-title v-title"
|
||||||
|
"v-labels v-labels"
|
||||||
|
"v-uploader v-uploader"
|
||||||
|
"v-date v-date"
|
||||||
|
"v-views v-views"
|
||||||
|
"v-likes-dislikes v-likes-dislikes"
|
||||||
|
"external-player-controls v-checkbox"
|
||||||
|
"v-direct-link v-direct-link"
|
||||||
|
"v-download v-download"
|
||||||
|
"v-description v-description"
|
||||||
|
"v-music-list v-music-list"
|
||||||
|
"v-more-info v-more-info";
|
||||||
|
}
|
||||||
|
.video-info > .views{
|
||||||
|
justify-self: start;
|
||||||
|
}
|
||||||
|
.video-info > .likes-dislikes{
|
||||||
|
justify-self: start;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
{% endblock style %}
|
||||||
|
|
||||||
|
{% block head %}
|
||||||
|
{% if settings.video_player == 1 %}
|
||||||
|
<!-- plyr -->
|
||||||
|
<link href="/youtube.com/static/modules/plyr/plyr.css" rel="stylesheet"/>
|
||||||
|
<link href="/youtube.com/static/plyr_fixes.css" rel="stylesheet"/>
|
||||||
|
<!--/ plyr -->
|
||||||
|
{% endif %}
|
||||||
|
{% endblock head %}
|
||||||
|
|
||||||
|
{% block main %}
|
||||||
|
{% if playability_error %}
|
||||||
|
<div class="playability-error">
|
||||||
|
<span>{{ 'Error: ' + playability_error }}
|
||||||
|
{% if invidious_reload_button %}
|
||||||
|
<a href="{{ video_url }}&use_invidious=0"><br>
|
||||||
|
Reload without invidious (for usage of new identity button).</a>
|
||||||
|
{% endif %}
|
||||||
|
</span>
|
||||||
|
</div>
|
||||||
|
{% elif (uni_sources.__len__() == 0 or live) and hls_formats.__len__() != 0 %}
|
||||||
|
<div class="live-url-choices">
|
||||||
|
<span>Copy a url into your video player:</span>
|
||||||
|
<ol>
|
||||||
|
{% for fmt in hls_formats %}
|
||||||
|
<li class="url-choice"><div class="url-choice-label">{{ fmt['video_quality'] }}: </div><input class="url-choice-copy" value="{{ fmt['url'] }}" readonly onclick="this.select();"></li>
|
||||||
|
{% endfor %}
|
||||||
|
</ol>
|
||||||
|
</div>
|
||||||
|
{% else %}
|
||||||
|
<div id="video-container" class="h{{video_height}}"> <!--Do not add other classes here, classes changed by javascript-->
|
||||||
|
<video controls autofocus class="video" {{ 'autoplay' if settings.autoplay_videos }}>
|
||||||
|
{% if uni_sources %}
|
||||||
|
<source src="{{ uni_sources[uni_idx]['url'] }}" type="{{ uni_sources[uni_idx]['type'] }}" data-res="{{ uni_sources[uni_idx]['quality'] }}">
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% for source in subtitle_sources %}
|
||||||
|
{% if source['on'] %}
|
||||||
|
<track label="{{ source['label'] }}" src="{{ source['url'] }}" kind="subtitles" srclang="{{ source['srclang'] }}" default>
|
||||||
|
{% else %}
|
||||||
|
<track label="{{ source['label'] }}" src="{{ source['url'] }}" kind="subtitles" srclang="{{ source['srclang'] }}">
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
</video>
|
||||||
|
</div>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
<div class="video-info">
|
||||||
|
<h2 class="title">{{ title }}</h2>
|
||||||
|
<ul class="labels">
|
||||||
|
{%- if unlisted -%}
|
||||||
|
<li class="is-unlisted">Unlisted</li>
|
||||||
|
{%- endif -%}
|
||||||
|
{%- if age_restricted -%}
|
||||||
|
<li class="age-restricted">Age-restricted</li>
|
||||||
|
{%- endif -%}
|
||||||
|
{%- if limited_state -%}
|
||||||
|
<li>Limited state</li>
|
||||||
|
{%- endif -%}
|
||||||
|
{%- if live -%}
|
||||||
|
<li>Live</li>
|
||||||
|
{%- endif -%}
|
||||||
|
</ul>
|
||||||
|
<address>Uploaded by <a href="{{ uploader_channel_url }}">{{ uploader }}</a></address>
|
||||||
|
<span class="views">{{ view_count }} views</span>
|
||||||
|
|
||||||
|
|
||||||
|
<time datetime="$upload_date">Published on {{ time_published }}</time>
|
||||||
|
<span class="likes-dislikes">{{ like_count }} likes {{ dislike_count }} dislikes</span>
|
||||||
|
|
||||||
|
<div class="external-player-controls">
|
||||||
|
<input id="speed-control" type="text" title="Video speed" placeholder="Speed">
|
||||||
|
{% if settings.video_player == 0 %}
|
||||||
|
<select id="quality-select" autocomplete="off">
|
||||||
|
{% for src in uni_sources %}
|
||||||
|
<option value='{"type": "uni", "index": {{ loop.index0 }}}' {{ 'selected' if loop.index0 == uni_idx and not using_pair_sources else '' }} >{{ src['quality_string'] }}</option>
|
||||||
|
{% endfor %}
|
||||||
|
{% for src_pair in pair_sources %}
|
||||||
|
<option value='{"type": "pair", "index": {{ loop.index0}}}' {{ 'selected' if loop.index0 == pair_idx and using_pair_sources else '' }} >{{ src_pair['quality_string'] }}</option>
|
||||||
|
{% endfor %}
|
||||||
|
</select>
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
<input class="checkbox" name="video_info_list" value="{{ video_info }}" form="playlist-edit" type="checkbox">
|
||||||
|
|
||||||
|
<span class="direct-link"><a href="https://youtu.be/{{ video_id }}">Direct Link</a></span>
|
||||||
|
|
||||||
|
<details class="download-dropdown">
|
||||||
|
<summary class="download-dropdown-label">Download</summary>
|
||||||
|
<ul class="download-dropdown-content">
|
||||||
|
{% for format in download_formats %}
|
||||||
|
<li class="download-format">
|
||||||
|
<a class="download-link" href="{{ format['url'] }}">
|
||||||
|
<ol class="format-attributes">
|
||||||
|
<li class="format-ext">{{ format['ext'] }}</li>
|
||||||
|
<li class="format-video-quality">{{ format['video_quality'] }}</li>
|
||||||
|
<li class="format-audio-quality">{{ format['audio_quality'] }}</li>
|
||||||
|
<li class="format-file-size">{{ format['file_size'] }}</li>
|
||||||
|
<li class="format-codecs">{{ format['codecs'] }}</li>
|
||||||
|
</ol>
|
||||||
|
</a>
|
||||||
|
</li>
|
||||||
|
{% endfor %}
|
||||||
|
{% for download in other_downloads %}
|
||||||
|
<li class="download-format">
|
||||||
|
<a class="download-link" href="{{ download['url'] }}">
|
||||||
|
<ol class="format-attributes">
|
||||||
|
<li class="format-ext">{{ download['ext'] }}</li>
|
||||||
|
<li class="format-label">{{ download['label'] }}</li>
|
||||||
|
</ol>
|
||||||
|
</a>
|
||||||
|
</li>
|
||||||
|
{% endfor %}
|
||||||
|
</ul>
|
||||||
|
</details>
|
||||||
|
|
||||||
|
|
||||||
|
<span class="description">{{ common_elements.text_runs(description)|escape|urlize|timestamps|safe }}</span>
|
||||||
|
<div class="music-list">
|
||||||
|
{% if music_list.__len__() != 0 %}
|
||||||
|
<hr>
|
||||||
|
<table>
|
||||||
|
<caption>Music</caption>
|
||||||
|
<tr>
|
||||||
|
{% for attribute in music_attributes %}
|
||||||
|
<th>{{ attribute }}</th>
|
||||||
|
{% endfor %}
|
||||||
|
</tr>
|
||||||
|
{% for track in music_list %}
|
||||||
|
<tr>
|
||||||
|
{% for attribute in music_attributes %}
|
||||||
|
{% if attribute.lower() == 'title' and track['url'] is not none %}
|
||||||
|
<td><a href="{{ track['url'] }}">{{ track.get(attribute.lower(), '') }}</a></td>
|
||||||
|
{% else %}
|
||||||
|
<td>{{ track.get(attribute.lower(), '') }}</td>
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
</tr>
|
||||||
|
{% endfor %}
|
||||||
|
</table>
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
<details class="more-info">
|
||||||
|
<summary>More info</summary>
|
||||||
|
<div class="more-info-content">
|
||||||
|
<p>Tor exit node: {{ ip_address }}</p>
|
||||||
|
{% if invidious_used %}
|
||||||
|
<p>Used Invidious as fallback.</p>
|
||||||
|
{% endif %}
|
||||||
|
<p class="allowed-countries">Allowed countries: {{ allowed_countries|join(', ') }}</p>
|
||||||
|
|
||||||
|
{% if settings.use_sponsorblock_js %}
|
||||||
|
<ul class="more-actions">
|
||||||
|
<li><label><input type=checkbox id=skip_sponsors checked>skip sponsors</label> <span id=skip_n></span>
|
||||||
|
</ul>
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
</details>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<div class="side-videos">
|
||||||
|
{% if playlist %}
|
||||||
|
<div class="playlist">
|
||||||
|
<div class="playlist-header">
|
||||||
|
<a href="{{ playlist['url'] }}" title="{{ playlist['title'] }}"><h3>{{ playlist['title'] }}</h3></a>
|
||||||
|
<ul class="playlist-metadata">
|
||||||
|
<li>Autoplay: <input type="checkbox" id="autoplay-toggle"></li>
|
||||||
|
{% if playlist['current_index'] is none %}
|
||||||
|
<li>[Error!]/{{ playlist['video_count'] }}</li>
|
||||||
|
{% else %}
|
||||||
|
<li>{{ playlist['current_index']+1 }}/{{ playlist['video_count'] }}</li>
|
||||||
|
{% endif %}
|
||||||
|
<li><a href="{{ playlist['author_url'] }}" title="{{ playlist['author'] }}">{{ playlist['author'] }}</a></li>
|
||||||
|
</ul>
|
||||||
|
</div>
|
||||||
|
<nav class="playlist-videos">
|
||||||
|
{% for info in playlist['items'] %}
|
||||||
|
{# non-lazy load for 5 videos surrounding current video #}
|
||||||
|
{# for non-js browsers or old such that IntersectionObserver doesn't work #}
|
||||||
|
{# -10 is sentinel to not load anything if there's no current_index for some reason #}
|
||||||
|
{% if (playlist.get('current_index', -10) - loop.index0)|abs is lt(5) %}
|
||||||
|
{{ common_elements.item(info, include_badges=false, lazy_load=false) }}
|
||||||
|
{% else %}
|
||||||
|
{{ common_elements.item(info, include_badges=false, lazy_load=true) }}
|
||||||
|
{% endif %}
|
||||||
|
{% endfor %}
|
||||||
|
</nav>
|
||||||
|
</div>
|
||||||
|
{% elif settings.related_videos_mode != 0 %}
|
||||||
|
<div class="autoplay-toggle-container"><label for="autoplay-toggle">Autoplay: </label><input type="checkbox" id="autoplay-toggle"></div>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
|
||||||
|
{% if subtitle_sources %}
|
||||||
|
<details id="transcript-details">
|
||||||
|
<summary>Transcript</summary>
|
||||||
|
<div id="transcript-div">
|
||||||
|
<select id="select-tt">
|
||||||
|
{% for source in subtitle_sources %}
|
||||||
|
<option>{{ source['label'] }}</option>
|
||||||
|
{% endfor %}
|
||||||
|
</select>
|
||||||
|
<label for="transcript-use-table">Table view</label>
|
||||||
|
<input type="checkbox" id="transcript-use-table">
|
||||||
|
<table id="transcript-table"></table>
|
||||||
|
</div>
|
||||||
|
</details>
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
{% if settings.related_videos_mode != 0 %}
|
||||||
|
<details class="related-videos-outer" {{'open' if settings.related_videos_mode == 1 else ''}}>
|
||||||
|
<summary>Related Videos</summary>
|
||||||
|
<nav class="related-videos-inner">
|
||||||
|
{% for info in related %}
|
||||||
|
{{ common_elements.item(info, include_badges=false) }}
|
||||||
|
{% endfor %}
|
||||||
|
</nav>
|
||||||
|
</details>
|
||||||
|
{% endif %}
|
||||||
|
</div>
|
||||||
|
|
||||||
|
{% if settings.comments_mode != 0 %}
|
||||||
|
{% if comments_disabled %}
|
||||||
|
<div class="comments-area-outer comments-disabled">Comments disabled</div>
|
||||||
|
{% else %}
|
||||||
|
<details class="comments-area-outer" {{'open' if settings.comments_mode == 1 else ''}}>
|
||||||
|
<summary>{{ comment_count|commatize }} comment{{'s' if comment_count != '1' else ''}}</summary>
|
||||||
|
<section class="comments-area-inner comments-area">
|
||||||
|
{% if comments_info %}
|
||||||
|
{{ comments.video_comments(comments_info) }}
|
||||||
|
{% endif %}
|
||||||
|
</section>
|
||||||
|
</details>
|
||||||
|
{% endif %}
|
||||||
|
{% endif %}
|
||||||
|
|
||||||
|
<script src="/youtube.com/static/js/av-merge.js"></script>
|
||||||
|
<script src="/youtube.com/static/js/watch.js"></script>
|
||||||
|
{% if settings.video_player == 1 %}
|
||||||
|
<!-- plyr -->
|
||||||
|
<script>var storyboard_url = {{ storyboard_url | tojson }}</script>
|
||||||
|
<script src="/youtube.com/static/modules/plyr/plyr.js"></script>
|
||||||
|
<script src="/youtube.com/static/js/plyr-start.js"></script>
|
||||||
|
<!-- /plyr -->
|
||||||
|
{% endif %}
|
||||||
|
<script src="/youtube.com/static/js/common.js"></script>
|
||||||
|
<script src="/youtube.com/static/js/transcript-table.js"></script>
|
||||||
|
{% if settings.use_video_hotkeys %} <script src="/youtube.com/static/js/hotkeys.js"></script> {% endif %}
|
||||||
|
{% if settings.use_comments_js %} <script src="/youtube.com/static/js/comments.js"></script> {% endif %}
|
||||||
|
{% if settings.use_sponsorblock_js %} <script src="/youtube.com/static/js/sponsorblock.js"></script> {% endif %}
|
||||||
|
{% endblock main %}
|
||||||
837
youtube/util.py
Normal file
837
youtube/util.py
Normal file
@@ -0,0 +1,837 @@
|
|||||||
|
import settings
|
||||||
|
import socks, sockshandler
|
||||||
|
import gzip
|
||||||
|
try:
|
||||||
|
import brotli
|
||||||
|
have_brotli = True
|
||||||
|
except ImportError:
|
||||||
|
have_brotli = False
|
||||||
|
import urllib.parse
|
||||||
|
import re
|
||||||
|
import time
|
||||||
|
import os
|
||||||
|
import json
|
||||||
|
import gevent
|
||||||
|
import gevent.queue
|
||||||
|
import gevent.lock
|
||||||
|
import collections
|
||||||
|
import stem
|
||||||
|
import stem.control
|
||||||
|
import traceback
|
||||||
|
|
||||||
|
# The trouble with the requests library: It ships its own certificate bundle via certifi
|
||||||
|
# instead of using the system certificate store, meaning self-signed certificates
|
||||||
|
# configured by the user will not work. Some draconian networks block TLS unless a corporate
|
||||||
|
# certificate is installed on the system. Additionally, some users install a self signed cert
|
||||||
|
# in order to use programs to modify or monitor requests made by programs on the system.
|
||||||
|
|
||||||
|
# Finally, certificates expire and need to be updated, or are sometimes revoked. Sometimes
|
||||||
|
# certificate authorites go rogue and need to be untrusted. Since we are going through Tor exit nodes,
|
||||||
|
# this becomes all the more important. A rogue CA could issue a fake certificate for accounts.google.com, and a
|
||||||
|
# malicious exit node could use this to decrypt traffic when logging in and retrieve passwords. Examples:
|
||||||
|
# https://www.engadget.com/2015/10/29/google-warns-symantec-over-certificates/
|
||||||
|
# https://nakedsecurity.sophos.com/2013/12/09/serious-security-google-finds-fake-but-trusted-ssl-certificates-for-its-domains-made-in-france/
|
||||||
|
|
||||||
|
# In the requests documentation it says:
|
||||||
|
# "Before version 2.16, Requests bundled a set of root CAs that it trusted, sourced from the Mozilla trust store.
|
||||||
|
# The certificates were only updated once for each Requests version. When certifi was not installed,
|
||||||
|
# this led to extremely out-of-date certificate bundles when using significantly older versions of Requests.
|
||||||
|
# For the sake of security we recommend upgrading certifi frequently!"
|
||||||
|
# (http://docs.python-requests.org/en/master/user/advanced/#ca-certificates)
|
||||||
|
|
||||||
|
# Expecting users to remember to manually update certifi on Linux isn't reasonable in my view.
|
||||||
|
# On windows, this is even worse since I am distributing all dependencies. This program is not
|
||||||
|
# updated frequently, and using requests would lead to outdated certificates. Certificates
|
||||||
|
# should be updated with OS updates, instead of thousands of developers of different programs
|
||||||
|
# being expected to do this correctly 100% of the time.
|
||||||
|
|
||||||
|
# There is hope that this might be fixed eventually:
|
||||||
|
# https://github.com/kennethreitz/requests/issues/2966
|
||||||
|
|
||||||
|
# Until then, I will use a mix of urllib3 and urllib.
|
||||||
|
import urllib3
|
||||||
|
import urllib3.contrib.socks
|
||||||
|
|
||||||
|
URL_ORIGIN = "/https://www.youtube.com"
|
||||||
|
|
||||||
|
connection_pool = urllib3.PoolManager(cert_reqs = 'CERT_REQUIRED')
|
||||||
|
|
||||||
|
class TorManager:
|
||||||
|
MAX_TRIES = 3
|
||||||
|
# Remember the 7-sec wait times, so make cooldown be two of those
|
||||||
|
# (otherwise it will retry forever if 429s never end)
|
||||||
|
COOLDOWN_TIME = 14
|
||||||
|
def __init__(self):
|
||||||
|
self.old_tor_connection_pool = None
|
||||||
|
self.tor_connection_pool = urllib3.contrib.socks.SOCKSProxyManager(
|
||||||
|
'socks5h://127.0.0.1:' + str(settings.tor_port) + '/',
|
||||||
|
cert_reqs = 'CERT_REQUIRED')
|
||||||
|
self.tor_pool_refresh_time = time.monotonic()
|
||||||
|
settings.add_setting_changed_hook(
|
||||||
|
'tor_port',
|
||||||
|
lambda old_val, new_val: self.refresh_tor_connection_pool(),
|
||||||
|
)
|
||||||
|
|
||||||
|
self.new_identity_lock = gevent.lock.BoundedSemaphore(1)
|
||||||
|
self.last_new_identity_time = time.monotonic() - 20
|
||||||
|
self.try_num = 1
|
||||||
|
|
||||||
|
def refresh_tor_connection_pool(self):
|
||||||
|
self.tor_connection_pool.clear()
|
||||||
|
|
||||||
|
# Keep a reference for 5 min to avoid it getting garbage collected
|
||||||
|
# while sockets still in use
|
||||||
|
self.old_tor_connection_pool = self.tor_connection_pool
|
||||||
|
|
||||||
|
self.tor_connection_pool = urllib3.contrib.socks.SOCKSProxyManager(
|
||||||
|
'socks5h://127.0.0.1:' + str(settings.tor_port) + '/',
|
||||||
|
cert_reqs = 'CERT_REQUIRED')
|
||||||
|
self.tor_pool_refresh_time = time.monotonic()
|
||||||
|
|
||||||
|
def get_tor_connection_pool(self):
|
||||||
|
# Tor changes circuits after 10 minutes:
|
||||||
|
# https://tor.stackexchange.com/questions/262/for-how-long-does-a-circuit-stay-alive
|
||||||
|
current_time = time.monotonic()
|
||||||
|
|
||||||
|
# close pool after 5 minutes
|
||||||
|
if current_time - self.tor_pool_refresh_time > 300:
|
||||||
|
self.refresh_tor_connection_pool()
|
||||||
|
|
||||||
|
return self.tor_connection_pool
|
||||||
|
|
||||||
|
def new_identity(self, time_failed_request_started):
|
||||||
|
'''return error, or None if no error and the identity is fresh'''
|
||||||
|
|
||||||
|
# The overall pattern at maximum (always returning 429) will be
|
||||||
|
# R N (0) R N (6) R N (6) R | (12) R N (0) R N (6) ...
|
||||||
|
# where R is a request, N is a new identity, (x) is a wait time of
|
||||||
|
# x sec, and | is where we give up and display an error to the user.
|
||||||
|
|
||||||
|
print('new_identity: new_identity called')
|
||||||
|
# blocks if another greenlet currently has the lock
|
||||||
|
self.new_identity_lock.acquire()
|
||||||
|
print('new_identity: New identity lock acquired')
|
||||||
|
|
||||||
|
try:
|
||||||
|
# This was caused by a request that failed within a previous,
|
||||||
|
# stale identity
|
||||||
|
if time_failed_request_started <= self.last_new_identity_time:
|
||||||
|
print('new_identity: Cancelling; request was from stale identity')
|
||||||
|
return None
|
||||||
|
|
||||||
|
delta = time.monotonic() - self.last_new_identity_time
|
||||||
|
if delta < self.COOLDOWN_TIME and self.try_num == 1:
|
||||||
|
err = ('Retried with new circuit %d times (max) within last '
|
||||||
|
'%d seconds.' % (self.MAX_TRIES, self.COOLDOWN_TIME))
|
||||||
|
print('new_identity:', err)
|
||||||
|
return err
|
||||||
|
elif delta >= self.COOLDOWN_TIME:
|
||||||
|
self.try_num = 1
|
||||||
|
|
||||||
|
try:
|
||||||
|
port = settings.tor_control_port
|
||||||
|
with stem.control.Controller.from_port(port=port) as controller:
|
||||||
|
controller.authenticate('')
|
||||||
|
print('new_identity: Getting new identity')
|
||||||
|
controller.signal(stem.Signal.NEWNYM)
|
||||||
|
print('new_identity: NEWNYM signal sent')
|
||||||
|
self.last_new_identity_time = time.monotonic()
|
||||||
|
self.refresh_tor_connection_pool()
|
||||||
|
except stem.SocketError:
|
||||||
|
traceback.print_exc()
|
||||||
|
return 'Failed to connect to Tor control port.'
|
||||||
|
finally:
|
||||||
|
original_try_num = self.try_num
|
||||||
|
self.try_num += 1
|
||||||
|
if self.try_num > self.MAX_TRIES:
|
||||||
|
self.try_num = 1
|
||||||
|
|
||||||
|
# If we do the request right after second new identity it won't
|
||||||
|
# be a new IP, based on experiments.
|
||||||
|
# Not necessary after first new identity
|
||||||
|
if original_try_num > 1:
|
||||||
|
print('Sleeping for 7 seconds before retrying request')
|
||||||
|
time.sleep(7) # experimentally determined minimum
|
||||||
|
|
||||||
|
return None
|
||||||
|
finally:
|
||||||
|
self.new_identity_lock.release()
|
||||||
|
|
||||||
|
tor_manager = TorManager()
|
||||||
|
|
||||||
|
|
||||||
|
def get_pool(use_tor):
|
||||||
|
if not use_tor:
|
||||||
|
return connection_pool
|
||||||
|
return tor_manager.get_tor_connection_pool()
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPAsymmetricCookieProcessor(urllib.request.BaseHandler):
|
||||||
|
'''Separate cookiejars for receiving and sending'''
|
||||||
|
def __init__(self, cookiejar_send=None, cookiejar_receive=None):
|
||||||
|
import http.cookiejar
|
||||||
|
self.cookiejar_send = cookiejar_send
|
||||||
|
self.cookiejar_receive = cookiejar_receive
|
||||||
|
|
||||||
|
def http_request(self, request):
|
||||||
|
if self.cookiejar_send is not None:
|
||||||
|
self.cookiejar_send.add_cookie_header(request)
|
||||||
|
return request
|
||||||
|
|
||||||
|
def http_response(self, request, response):
|
||||||
|
if self.cookiejar_receive is not None:
|
||||||
|
self.cookiejar_receive.extract_cookies(response, request)
|
||||||
|
return response
|
||||||
|
|
||||||
|
https_request = http_request
|
||||||
|
https_response = http_response
|
||||||
|
|
||||||
|
class FetchError(Exception):
|
||||||
|
def __init__(self, code, reason='', ip=None, error_message=None):
|
||||||
|
if error_message:
|
||||||
|
string = code + ' ' + reason + ': ' + error_message
|
||||||
|
else:
|
||||||
|
string = 'HTTP error during request: ' + code + ' ' + reason
|
||||||
|
Exception.__init__(self, string)
|
||||||
|
self.code = code
|
||||||
|
self.reason = reason
|
||||||
|
self.ip = ip
|
||||||
|
self.error_message = error_message
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def decode_content(content, encoding_header):
|
||||||
|
encodings = encoding_header.replace(' ', '').split(',')
|
||||||
|
for encoding in reversed(encodings):
|
||||||
|
if encoding == 'identity':
|
||||||
|
continue
|
||||||
|
if encoding == 'br':
|
||||||
|
content = brotli.decompress(content)
|
||||||
|
elif encoding == 'gzip':
|
||||||
|
content = gzip.decompress(content)
|
||||||
|
return content
|
||||||
|
|
||||||
|
def fetch_url_response(url, headers=(), timeout=15, data=None,
|
||||||
|
cookiejar_send=None, cookiejar_receive=None,
|
||||||
|
use_tor=True, max_redirects=None):
|
||||||
|
'''
|
||||||
|
returns response, cleanup_function
|
||||||
|
When cookiejar_send is set to a CookieJar object,
|
||||||
|
those cookies will be sent in the request (but cookies in response will not be merged into it)
|
||||||
|
When cookiejar_receive is set to a CookieJar object,
|
||||||
|
cookies received in the response will be merged into the object (nothing will be sent from it)
|
||||||
|
When both are set to the same object, cookies will be sent from the object,
|
||||||
|
and response cookies will be merged into it.
|
||||||
|
'''
|
||||||
|
headers = dict(headers) # Note: Calling dict() on a dict will make a copy
|
||||||
|
if have_brotli:
|
||||||
|
headers['Accept-Encoding'] = 'gzip, br'
|
||||||
|
else:
|
||||||
|
headers['Accept-Encoding'] = 'gzip'
|
||||||
|
|
||||||
|
# prevent python version being leaked by urllib if User-Agent isn't provided
|
||||||
|
# (urllib will use ex. Python-urllib/3.6 otherwise)
|
||||||
|
if 'User-Agent' not in headers and 'user-agent' not in headers and 'User-agent' not in headers:
|
||||||
|
headers['User-Agent'] = 'Python-urllib'
|
||||||
|
|
||||||
|
method = "GET"
|
||||||
|
if data is not None:
|
||||||
|
method = "POST"
|
||||||
|
if isinstance(data, str):
|
||||||
|
data = data.encode('utf-8')
|
||||||
|
elif not isinstance(data, bytes):
|
||||||
|
data = urllib.parse.urlencode(data).encode('utf-8')
|
||||||
|
|
||||||
|
|
||||||
|
if cookiejar_send is not None or cookiejar_receive is not None: # Use urllib
|
||||||
|
req = urllib.request.Request(url, data=data, headers=headers)
|
||||||
|
|
||||||
|
cookie_processor = HTTPAsymmetricCookieProcessor(cookiejar_send=cookiejar_send, cookiejar_receive=cookiejar_receive)
|
||||||
|
|
||||||
|
if use_tor and settings.route_tor:
|
||||||
|
opener = urllib.request.build_opener(sockshandler.SocksiPyHandler(socks.PROXY_TYPE_SOCKS5, "127.0.0.1", settings.tor_port), cookie_processor)
|
||||||
|
else:
|
||||||
|
opener = urllib.request.build_opener(cookie_processor)
|
||||||
|
|
||||||
|
response = opener.open(req, timeout=timeout)
|
||||||
|
cleanup_func = (lambda r: None)
|
||||||
|
|
||||||
|
else: # Use a urllib3 pool. Cookies can't be used since urllib3 doesn't have easy support for them.
|
||||||
|
# default: Retry.DEFAULT = Retry(3)
|
||||||
|
# (in connectionpool.py in urllib3)
|
||||||
|
# According to the documentation for urlopen, a redirect counts as a
|
||||||
|
# retry. So there are 3 redirects max by default.
|
||||||
|
if max_redirects:
|
||||||
|
retries = urllib3.Retry(3+max_redirects, redirect=max_redirects, raise_on_redirect=False)
|
||||||
|
else:
|
||||||
|
retries = urllib3.Retry(3, raise_on_redirect=False)
|
||||||
|
pool = get_pool(use_tor and settings.route_tor)
|
||||||
|
try:
|
||||||
|
response = pool.request(method, url, headers=headers, body=data,
|
||||||
|
timeout=timeout, preload_content=False,
|
||||||
|
decode_content=False, retries=retries)
|
||||||
|
response.retries = retries
|
||||||
|
except urllib3.exceptions.MaxRetryError as e:
|
||||||
|
exception_cause = e.__context__.__context__
|
||||||
|
if (isinstance(exception_cause, socks.ProxyConnectionError)
|
||||||
|
and settings.route_tor):
|
||||||
|
msg = ('Failed to connect to Tor. Check that Tor is open and '
|
||||||
|
'that your internet connection is working.\n\n'
|
||||||
|
+ str(e))
|
||||||
|
raise FetchError('502', reason='Bad Gateway',
|
||||||
|
error_message=msg)
|
||||||
|
elif isinstance(e.__context__,
|
||||||
|
urllib3.exceptions.NewConnectionError):
|
||||||
|
msg = 'Failed to establish a connection.\n\n' + str(e)
|
||||||
|
raise FetchError(
|
||||||
|
'502', reason='Bad Gateway',
|
||||||
|
error_message=msg)
|
||||||
|
else:
|
||||||
|
raise
|
||||||
|
cleanup_func = (lambda r: r.release_conn())
|
||||||
|
|
||||||
|
return response, cleanup_func
|
||||||
|
|
||||||
|
def fetch_url(url, headers=(), timeout=15, report_text=None, data=None,
|
||||||
|
cookiejar_send=None, cookiejar_receive=None, use_tor=True,
|
||||||
|
debug_name=None):
|
||||||
|
while True:
|
||||||
|
start_time = time.monotonic()
|
||||||
|
|
||||||
|
response, cleanup_func = fetch_url_response(
|
||||||
|
url, headers, timeout=timeout, data=data,
|
||||||
|
cookiejar_send=cookiejar_send, cookiejar_receive=cookiejar_receive,
|
||||||
|
use_tor=use_tor)
|
||||||
|
response_time = time.monotonic()
|
||||||
|
|
||||||
|
content = response.read()
|
||||||
|
|
||||||
|
read_finish = time.monotonic()
|
||||||
|
|
||||||
|
cleanup_func(response) # release_connection for urllib3
|
||||||
|
content = decode_content(
|
||||||
|
content,
|
||||||
|
response.getheader('Content-Encoding', default='identity'))
|
||||||
|
|
||||||
|
if (settings.debugging_save_responses
|
||||||
|
and debug_name is not None
|
||||||
|
and content):
|
||||||
|
save_dir = os.path.join(settings.data_dir, 'debug')
|
||||||
|
if not os.path.exists(save_dir):
|
||||||
|
os.makedirs(save_dir)
|
||||||
|
|
||||||
|
with open(os.path.join(save_dir, debug_name), 'wb') as f:
|
||||||
|
f.write(content)
|
||||||
|
|
||||||
|
if response.status == 429 or (
|
||||||
|
response.status == 302 and (response.getheader('Location') == url
|
||||||
|
or response.getheader('Location').startswith(
|
||||||
|
'https://www.google.com/sorry/index'
|
||||||
|
)
|
||||||
|
)
|
||||||
|
):
|
||||||
|
print(response.status, response.reason, response.headers)
|
||||||
|
ip = re.search(
|
||||||
|
br'IP address: ((?:[\da-f]*:)+[\da-f]+|(?:\d+\.)+\d+)',
|
||||||
|
content)
|
||||||
|
ip = ip.group(1).decode('ascii') if ip else None
|
||||||
|
if not ip:
|
||||||
|
ip = re.search(r'IP=((?:\d+\.)+\d+)',
|
||||||
|
response.getheader('Set-Cookie') or '')
|
||||||
|
ip = ip.group(1) if ip else None
|
||||||
|
|
||||||
|
# don't get new identity if we're not using Tor
|
||||||
|
if not use_tor:
|
||||||
|
raise FetchError('429', reason=response.reason, ip=ip)
|
||||||
|
|
||||||
|
print('Error: Youtube blocked the request because the Tor exit node is overutilized. Exit node IP address: %s' % ip)
|
||||||
|
|
||||||
|
# get new identity
|
||||||
|
error = tor_manager.new_identity(start_time)
|
||||||
|
if error:
|
||||||
|
raise FetchError(
|
||||||
|
'429', reason=response.reason, ip=ip,
|
||||||
|
error_message='Automatic circuit change: ' + error)
|
||||||
|
else:
|
||||||
|
continue # retry now that we have new identity
|
||||||
|
|
||||||
|
elif response.status >= 400:
|
||||||
|
raise FetchError(str(response.status), reason=response.reason,
|
||||||
|
ip=None)
|
||||||
|
break
|
||||||
|
|
||||||
|
if report_text:
|
||||||
|
print(report_text, ' Latency:', round(response_time - start_time,3), ' Read time:', round(read_finish - response_time,3))
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
return content
|
||||||
|
|
||||||
|
def head(url, use_tor=False, report_text=None, max_redirects=10):
|
||||||
|
pool = get_pool(use_tor and settings.route_tor)
|
||||||
|
start_time = time.monotonic()
|
||||||
|
|
||||||
|
# default: Retry.DEFAULT = Retry(3)
|
||||||
|
# (in connectionpool.py in urllib3)
|
||||||
|
# According to the documentation for urlopen, a redirect counts as a retry
|
||||||
|
# So there are 3 redirects max by default. Let's change that
|
||||||
|
# to 10 since googlevideo redirects a lot.
|
||||||
|
retries = urllib3.Retry(3+max_redirects, redirect=max_redirects,
|
||||||
|
raise_on_redirect=False)
|
||||||
|
headers = {'User-Agent': 'Python-urllib'}
|
||||||
|
response = pool.request('HEAD', url, headers=headers, retries=retries)
|
||||||
|
if report_text:
|
||||||
|
print(
|
||||||
|
report_text,
|
||||||
|
' Latency:',
|
||||||
|
round(time.monotonic() - start_time,3))
|
||||||
|
return response
|
||||||
|
|
||||||
|
mobile_user_agent = 'Mozilla/5.0 (Linux; Android 7.0; Redmi Note 4 Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Mobile Safari/537.36'
|
||||||
|
mobile_ua = (('User-Agent', mobile_user_agent),)
|
||||||
|
desktop_user_agent = 'Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0'
|
||||||
|
desktop_ua = (('User-Agent', desktop_user_agent),)
|
||||||
|
json_header = (('Content-Type', 'application/json'),)
|
||||||
|
desktop_xhr_headers = (
|
||||||
|
('Accept', '*/*'),
|
||||||
|
('Accept-Language', 'en-US,en;q=0.5'),
|
||||||
|
('X-YouTube-Client-Name', '1'),
|
||||||
|
('X-YouTube-Client-Version', '2.20240304.00.00'),
|
||||||
|
) + desktop_ua
|
||||||
|
mobile_xhr_headers = (
|
||||||
|
('Accept', '*/*'),
|
||||||
|
('Accept-Language', 'en-US,en;q=0.5'),
|
||||||
|
('X-YouTube-Client-Name', '2'),
|
||||||
|
('X-YouTube-Client-Version', '2.20240304.08.00'),
|
||||||
|
) + mobile_ua
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
class RateLimitedQueue(gevent.queue.Queue):
|
||||||
|
''' Does initial_burst (def. 30) at first, then alternates between waiting waiting_period (def. 5) seconds and doing subsequent_bursts (def. 10) queries. After 5 seconds with nothing left in the queue, resets rate limiting. '''
|
||||||
|
|
||||||
|
def __init__(self, initial_burst=30, waiting_period=5, subsequent_bursts=10):
|
||||||
|
self.initial_burst = initial_burst
|
||||||
|
self.waiting_period = waiting_period
|
||||||
|
self.subsequent_bursts = subsequent_bursts
|
||||||
|
|
||||||
|
self.count_since_last_wait = 0
|
||||||
|
self.surpassed_initial = False
|
||||||
|
|
||||||
|
self.lock = gevent.lock.BoundedSemaphore(1)
|
||||||
|
self.currently_empty = False
|
||||||
|
self.empty_start = 0
|
||||||
|
gevent.queue.Queue.__init__(self)
|
||||||
|
|
||||||
|
|
||||||
|
def get(self):
|
||||||
|
self.lock.acquire() # blocks if another greenlet currently has the lock
|
||||||
|
if self.count_since_last_wait >= self.subsequent_bursts and self.surpassed_initial:
|
||||||
|
gevent.sleep(self.waiting_period)
|
||||||
|
self.count_since_last_wait = 0
|
||||||
|
|
||||||
|
elif self.count_since_last_wait >= self.initial_burst and not self.surpassed_initial:
|
||||||
|
self.surpassed_initial = True
|
||||||
|
gevent.sleep(self.waiting_period)
|
||||||
|
self.count_since_last_wait = 0
|
||||||
|
|
||||||
|
self.count_since_last_wait += 1
|
||||||
|
|
||||||
|
if not self.currently_empty and self.empty():
|
||||||
|
self.currently_empty = True
|
||||||
|
self.empty_start = time.monotonic()
|
||||||
|
|
||||||
|
item = gevent.queue.Queue.get(self) # blocks when nothing left
|
||||||
|
|
||||||
|
if self.currently_empty:
|
||||||
|
if time.monotonic() - self.empty_start >= self.waiting_period:
|
||||||
|
self.count_since_last_wait = 0
|
||||||
|
self.surpassed_initial = False
|
||||||
|
|
||||||
|
self.currently_empty = False
|
||||||
|
|
||||||
|
self.lock.release()
|
||||||
|
|
||||||
|
return item
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def download_thumbnail(save_directory, video_id):
|
||||||
|
url = "https://i.ytimg.com/vi/" + video_id + "/mqdefault.jpg"
|
||||||
|
save_location = os.path.join(save_directory, video_id + ".jpg")
|
||||||
|
try:
|
||||||
|
thumbnail = fetch_url(url, report_text="Saved thumbnail: " + video_id)
|
||||||
|
except urllib.error.HTTPError as e:
|
||||||
|
print("Failed to download thumbnail for " + video_id + ": " + str(e))
|
||||||
|
return False
|
||||||
|
try:
|
||||||
|
f = open(save_location, 'wb')
|
||||||
|
except FileNotFoundError:
|
||||||
|
os.makedirs(save_directory, exist_ok = True)
|
||||||
|
f = open(save_location, 'wb')
|
||||||
|
f.write(thumbnail)
|
||||||
|
f.close()
|
||||||
|
return True
|
||||||
|
|
||||||
|
def download_thumbnails(save_directory, ids):
|
||||||
|
if not isinstance(ids, (list, tuple)):
|
||||||
|
ids = list(ids)
|
||||||
|
# only do 5 at a time
|
||||||
|
# do the n where n is divisible by 5
|
||||||
|
i = -1
|
||||||
|
for i in range(0, int(len(ids)/5) - 1 ):
|
||||||
|
gevent.joinall([gevent.spawn(download_thumbnail, save_directory, ids[j]) for j in range(i*5, i*5 + 5)])
|
||||||
|
# do the remainders (< 5)
|
||||||
|
gevent.joinall([gevent.spawn(download_thumbnail, save_directory, ids[j]) for j in range(i*5 + 5, len(ids))])
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def dict_add(*dicts):
|
||||||
|
for dictionary in dicts[1:]:
|
||||||
|
dicts[0].update(dictionary)
|
||||||
|
return dicts[0]
|
||||||
|
|
||||||
|
def video_id(url):
|
||||||
|
url_parts = urllib.parse.urlparse(url)
|
||||||
|
return urllib.parse.parse_qs(url_parts.query)['v'][0]
|
||||||
|
|
||||||
|
|
||||||
|
# default, sddefault, mqdefault, hqdefault, hq720
|
||||||
|
def get_thumbnail_url(video_id):
|
||||||
|
return settings.img_prefix + "https://i.ytimg.com/vi/" + video_id + "/mqdefault.jpg"
|
||||||
|
|
||||||
|
def seconds_to_timestamp(seconds):
|
||||||
|
seconds = int(seconds)
|
||||||
|
hours, seconds = divmod(seconds,3600)
|
||||||
|
minutes, seconds = divmod(seconds,60)
|
||||||
|
if hours != 0:
|
||||||
|
timestamp = str(hours) + ":"
|
||||||
|
timestamp += str(minutes).zfill(2) # zfill pads with zeros
|
||||||
|
else:
|
||||||
|
timestamp = str(minutes)
|
||||||
|
|
||||||
|
timestamp += ":" + str(seconds).zfill(2)
|
||||||
|
return timestamp
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def update_query_string(query_string, items):
|
||||||
|
parameters = urllib.parse.parse_qs(query_string)
|
||||||
|
parameters.update(items)
|
||||||
|
return urllib.parse.urlencode(parameters, doseq=True)
|
||||||
|
|
||||||
|
|
||||||
|
YOUTUBE_DOMAINS = ('youtube.com', 'youtu.be', 'youtube-nocookie.com')
|
||||||
|
YOUTUBE_URL_RE_STR = r'https?://(?:[a-zA-Z0-9_-]*\.)?(?:'
|
||||||
|
YOUTUBE_URL_RE_STR += r'|'.join(map(re.escape, YOUTUBE_DOMAINS))
|
||||||
|
YOUTUBE_URL_RE_STR += r')(?:/[^"]*)?'
|
||||||
|
YOUTUBE_URL_RE = re.compile(YOUTUBE_URL_RE_STR)
|
||||||
|
|
||||||
|
|
||||||
|
def prefix_url(url):
|
||||||
|
if url is None:
|
||||||
|
return None
|
||||||
|
url = url.lstrip('/') # some urls have // before them, which has a special meaning
|
||||||
|
return '/' + url
|
||||||
|
|
||||||
|
def left_remove(string, substring):
|
||||||
|
'''removes substring from the start of string, if present'''
|
||||||
|
if string.startswith(substring):
|
||||||
|
return string[len(substring):]
|
||||||
|
return string
|
||||||
|
|
||||||
|
def concat_or_none(*strings):
|
||||||
|
'''Concatenates strings. Returns None if any of the arguments are None'''
|
||||||
|
result = ''
|
||||||
|
for string in strings:
|
||||||
|
if string is None:
|
||||||
|
return None
|
||||||
|
result += string
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
def prefix_urls(item):
|
||||||
|
if settings.proxy_images:
|
||||||
|
try:
|
||||||
|
item['thumbnail'] = prefix_url(item['thumbnail'])
|
||||||
|
except KeyError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
try:
|
||||||
|
item['author_url'] = prefix_url(item['author_url'])
|
||||||
|
except KeyError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def add_extra_html_info(item):
|
||||||
|
if item['type'] == 'video':
|
||||||
|
item['url'] = (URL_ORIGIN + '/watch?v=' + item['id']) if item.get('id') else None
|
||||||
|
|
||||||
|
video_info = {}
|
||||||
|
for key in ('id', 'title', 'author', 'duration', 'author_id'):
|
||||||
|
try:
|
||||||
|
video_info[key] = item[key]
|
||||||
|
except KeyError:
|
||||||
|
video_info[key] = None
|
||||||
|
|
||||||
|
item['video_info'] = json.dumps(video_info)
|
||||||
|
|
||||||
|
elif item['type'] == 'playlist' and item['playlist_type'] == 'radio':
|
||||||
|
item['url'] = concat_or_none(
|
||||||
|
URL_ORIGIN,
|
||||||
|
'/watch?v=', item['first_video_id'],
|
||||||
|
'&list=', item['id']
|
||||||
|
)
|
||||||
|
elif item['type'] == 'playlist':
|
||||||
|
item['url'] = concat_or_none(URL_ORIGIN, '/playlist?list=', item['id'])
|
||||||
|
elif item['type'] == 'channel':
|
||||||
|
item['url'] = concat_or_none(URL_ORIGIN, "/channel/", item['id'])
|
||||||
|
|
||||||
|
if item.get('author_id') and 'author_url' not in item:
|
||||||
|
item['author_url'] = URL_ORIGIN + '/channel/' + item['author_id']
|
||||||
|
|
||||||
|
|
||||||
|
def check_gevent_exceptions(*tasks):
|
||||||
|
for task in tasks:
|
||||||
|
if task.exception:
|
||||||
|
raise task.exception
|
||||||
|
|
||||||
|
|
||||||
|
# https://stackoverflow.com/a/62888
|
||||||
|
replacement_map = collections.OrderedDict([
|
||||||
|
('<', '_'),
|
||||||
|
('>', '_'),
|
||||||
|
(': ', ' - '),
|
||||||
|
(':', '-'),
|
||||||
|
('"', "'"),
|
||||||
|
('/', '_'),
|
||||||
|
('\\', '_'),
|
||||||
|
('|', '-'),
|
||||||
|
('?', ''),
|
||||||
|
('*', '_'),
|
||||||
|
('\t', ' '),
|
||||||
|
])
|
||||||
|
DOS_names = {'con', 'prn', 'aux', 'nul', 'com0', 'com1', 'com2', 'com3', 'com4', 'com5', 'com6', 'com7', 'com8', 'com9', 'lpt0', 'lpt1', 'lpt2', 'lpt3', 'lpt4', 'lpt5', 'lpt6', 'lpt7', 'lpt8', 'lpt9'}
|
||||||
|
def to_valid_filename(name):
|
||||||
|
'''Changes the name so it's valid on Windows, Linux, and Mac'''
|
||||||
|
# See https://docs.microsoft.com/en-us/windows/win32/fileio/naming-a-file
|
||||||
|
# for Windows specs
|
||||||
|
|
||||||
|
# Additional recommendations for Linux:
|
||||||
|
# https://dwheeler.com/essays/fixing-unix-linux-filenames.html#standards
|
||||||
|
|
||||||
|
# remove control characters
|
||||||
|
name = re.sub(r'[\x00-\x1f]', '_', name)
|
||||||
|
|
||||||
|
# reserved characters
|
||||||
|
for reserved_char, replacement in replacement_map.items():
|
||||||
|
name = name.replace(reserved_char, replacement)
|
||||||
|
|
||||||
|
# check for all periods/spaces
|
||||||
|
if all(c == '.' or c == ' ' for c in name):
|
||||||
|
name = '_'*len(name)
|
||||||
|
|
||||||
|
# remove trailing periods and spaces
|
||||||
|
name = name.rstrip('. ')
|
||||||
|
|
||||||
|
# check for reserved DOS names, such as nul or nul.txt
|
||||||
|
base_ext_parts = name.rsplit('.', maxsplit=1)
|
||||||
|
if base_ext_parts[0].lower() in DOS_names:
|
||||||
|
base_ext_parts[0] += '_'
|
||||||
|
name = '.'.join(base_ext_parts)
|
||||||
|
|
||||||
|
# check for blank name
|
||||||
|
if name == '':
|
||||||
|
name = '_'
|
||||||
|
|
||||||
|
# check if name begins with a hyphen, period, or space
|
||||||
|
if name[0] in ('-', '.', ' '):
|
||||||
|
name = '_' + name
|
||||||
|
|
||||||
|
return name
|
||||||
|
|
||||||
|
# https://github.com/yt-dlp/yt-dlp/blob/master/yt_dlp/extractor/youtube.py#L72
|
||||||
|
INNERTUBE_CLIENTS = {
|
||||||
|
'android': {
|
||||||
|
'INNERTUBE_API_KEY': 'AIzaSyA8eiZmM1FaDVjRy-df2KTyQ_vz_yYM39w',
|
||||||
|
'INNERTUBE_CONTEXT': {
|
||||||
|
'client': {
|
||||||
|
'hl': 'en',
|
||||||
|
'gl': 'US',
|
||||||
|
'clientName': 'ANDROID',
|
||||||
|
'clientVersion': '19.09.36',
|
||||||
|
'osName': 'Android',
|
||||||
|
'osVersion': '12',
|
||||||
|
'androidSdkVersion': 31,
|
||||||
|
'platform': 'MOBILE',
|
||||||
|
'userAgent': 'com.google.android.youtube/19.09.36 (Linux; U; Android 12; US) gzip'
|
||||||
|
},
|
||||||
|
# https://github.com/yt-dlp/yt-dlp/pull/575#issuecomment-887739287
|
||||||
|
#'thirdParty': {
|
||||||
|
# 'embedUrl': 'https://google.com', # Can be any valid URL
|
||||||
|
#}
|
||||||
|
},
|
||||||
|
'INNERTUBE_CONTEXT_CLIENT_NAME': 3,
|
||||||
|
'REQUIRE_JS_PLAYER': False,
|
||||||
|
},
|
||||||
|
|
||||||
|
'android-test-suite': {
|
||||||
|
'INNERTUBE_API_KEY': 'AIzaSyA8eiZmM1FaDVjRy-df2KTyQ_vz_yYM39w',
|
||||||
|
'INNERTUBE_CONTEXT': {
|
||||||
|
'client': {
|
||||||
|
'hl': 'en',
|
||||||
|
'gl': 'US',
|
||||||
|
'clientName': 'ANDROID_TESTSUITE',
|
||||||
|
'clientVersion': '1.9',
|
||||||
|
'osName': 'Android',
|
||||||
|
'osVersion': '12',
|
||||||
|
'androidSdkVersion': 31,
|
||||||
|
'platform': 'MOBILE',
|
||||||
|
'userAgent': 'com.google.android.youtube/1.9 (Linux; U; Android 12; US) gzip'
|
||||||
|
},
|
||||||
|
# https://github.com/yt-dlp/yt-dlp/pull/575#issuecomment-887739287
|
||||||
|
#'thirdParty': {
|
||||||
|
# 'embedUrl': 'https://google.com', # Can be any valid URL
|
||||||
|
#}
|
||||||
|
},
|
||||||
|
'INNERTUBE_CONTEXT_CLIENT_NAME': 3,
|
||||||
|
'REQUIRE_JS_PLAYER': False,
|
||||||
|
},
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
'ios': {
|
||||||
|
'INNERTUBE_API_KEY': 'AIzaSyB-63vPrdThhKuerbB2N_l7Kwwcxj6yUAc',
|
||||||
|
'INNERTUBE_CONTEXT': {
|
||||||
|
'client': {
|
||||||
|
'hl': 'en',
|
||||||
|
'gl': 'US',
|
||||||
|
'clientName': 'IOS',
|
||||||
|
'clientVersion': '19.09.3',
|
||||||
|
'deviceModel': 'iPhone14,3',
|
||||||
|
'userAgent': 'com.google.ios.youtube/19.09.3 (iPhone14,3; U; CPU iOS 15_6 like Mac OS X)'
|
||||||
|
}
|
||||||
|
},
|
||||||
|
'INNERTUBE_CONTEXT_CLIENT_NAME': 5,
|
||||||
|
'REQUIRE_JS_PLAYER': False
|
||||||
|
},
|
||||||
|
|
||||||
|
# This client can access age restricted videos (unless the uploader has disabled the 'allow embedding' option)
|
||||||
|
# See: https://github.com/zerodytrash/YouTube-Internal-Clients
|
||||||
|
'tv_embedded': {
|
||||||
|
'INNERTUBE_API_KEY': 'AIzaSyAO_FJ2SlqU8Q4STEHLGCilw_Y9_11qcW8',
|
||||||
|
'INNERTUBE_CONTEXT': {
|
||||||
|
'client': {
|
||||||
|
'hl': 'en',
|
||||||
|
'gl': 'US',
|
||||||
|
'clientName': 'TVHTML5_SIMPLY_EMBEDDED_PLAYER',
|
||||||
|
'clientVersion': '2.0',
|
||||||
|
'clientScreen': 'EMBED',
|
||||||
|
},
|
||||||
|
# https://github.com/yt-dlp/yt-dlp/pull/575#issuecomment-887739287
|
||||||
|
'thirdParty': {
|
||||||
|
'embedUrl': 'https://google.com', # Can be any valid URL
|
||||||
|
}
|
||||||
|
|
||||||
|
},
|
||||||
|
'INNERTUBE_CONTEXT_CLIENT_NAME': 85,
|
||||||
|
'REQUIRE_JS_PLAYER': True,
|
||||||
|
},
|
||||||
|
|
||||||
|
'web': {
|
||||||
|
'INNERTUBE_API_KEY': 'AIzaSyAO_FJ2SlqU8Q4STEHLGCilw_Y9_11qcW8',
|
||||||
|
'INNERTUBE_CONTEXT': {
|
||||||
|
'client': {
|
||||||
|
'clientName': 'WEB',
|
||||||
|
'clientVersion': '2.20220801.00.00',
|
||||||
|
'userAgent': desktop_user_agent,
|
||||||
|
}
|
||||||
|
},
|
||||||
|
'INNERTUBE_CONTEXT_CLIENT_NAME': 1
|
||||||
|
},
|
||||||
|
'android_vr': {
|
||||||
|
'INNERTUBE_API_KEY': 'AIzaSyA8eiZmM1FaDVjRy-df2KTyQ_vz_yYM39w',
|
||||||
|
'INNERTUBE_CONTEXT': {
|
||||||
|
'client': {
|
||||||
|
'clientName': 'ANDROID_VR',
|
||||||
|
'clientVersion': '1.60.19',
|
||||||
|
'deviceMake': 'Oculus',
|
||||||
|
'deviceModel': 'Quest 3',
|
||||||
|
'androidSdkVersion': 32,
|
||||||
|
'userAgent': 'com.google.android.apps.youtube.vr.oculus/1.60.19 (Linux; U; Android 12L; eureka-user Build/SQ3A.220605.009.A1) gzip',
|
||||||
|
'osName': 'Android',
|
||||||
|
'osVersion': '12L',
|
||||||
|
},
|
||||||
|
},
|
||||||
|
'INNERTUBE_CONTEXT_CLIENT_NAME': 28,
|
||||||
|
'REQUIRE_JS_PLAYER': False,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
def get_visitor_data():
|
||||||
|
visitor_data = None
|
||||||
|
visitor_data_cache = os.path.join(settings.data_dir, 'visitorData.txt')
|
||||||
|
if not os.path.exists(settings.data_dir):
|
||||||
|
os.makedirs(settings.data_dir)
|
||||||
|
if os.path.isfile(visitor_data_cache):
|
||||||
|
with open(visitor_data_cache, 'r') as file:
|
||||||
|
print('Getting visitor_data from cache')
|
||||||
|
visitor_data = file.read()
|
||||||
|
max_age = 12*3600
|
||||||
|
file_age = time.time() - os.path.getmtime(visitor_data_cache)
|
||||||
|
if file_age > max_age:
|
||||||
|
print('visitor_data cache is too old. Removing file...')
|
||||||
|
os.remove(visitor_data_cache)
|
||||||
|
return visitor_data
|
||||||
|
|
||||||
|
print('Fetching youtube homepage to get visitor_data')
|
||||||
|
yt_homepage = 'https://www.youtube.com'
|
||||||
|
yt_resp = fetch_url(yt_homepage, headers={'User-Agent': mobile_user_agent}, report_text='Getting youtube homepage')
|
||||||
|
visitor_data_re = r'''"visitorData":\s*?"(.+?)"'''
|
||||||
|
visitor_data_match = re.search(visitor_data_re, yt_resp.decode())
|
||||||
|
if visitor_data_match:
|
||||||
|
visitor_data = visitor_data_match.group(1)
|
||||||
|
print(f'Got visitor_data: {len(visitor_data)}')
|
||||||
|
with open(visitor_data_cache, 'w') as file:
|
||||||
|
print('Saving visitor_data cache...')
|
||||||
|
file.write(visitor_data)
|
||||||
|
return visitor_data
|
||||||
|
else:
|
||||||
|
print('Unable to get visitor_data value')
|
||||||
|
return visitor_data
|
||||||
|
|
||||||
|
def call_youtube_api(client, api, data, cookies=None):
|
||||||
|
client_params = INNERTUBE_CLIENTS[client]
|
||||||
|
context = client_params['INNERTUBE_CONTEXT']
|
||||||
|
key = client_params['INNERTUBE_API_KEY']
|
||||||
|
host = client_params.get('INNERTUBE_HOST') or 'www.youtube.com'
|
||||||
|
user_agent = context['client'].get('userAgent') or mobile_user_agent
|
||||||
|
visitor_data = get_visitor_data()
|
||||||
|
|
||||||
|
url = 'https://' + host + '/youtubei/v1/' + api + '?key=' + key
|
||||||
|
if visitor_data:
|
||||||
|
context['client'].update({'visitorData': visitor_data})
|
||||||
|
data['context'] = context
|
||||||
|
|
||||||
|
data = json.dumps(data)
|
||||||
|
headers = [
|
||||||
|
('Content-Type', 'application/json'),
|
||||||
|
('User-Agent', user_agent)
|
||||||
|
]
|
||||||
|
if visitor_data:
|
||||||
|
headers.append(('X-Goog-Visitor-Id', visitor_data))
|
||||||
|
# Add cookies if provided
|
||||||
|
if cookies:
|
||||||
|
cookie_header = '; '.join(f'{k}={v}' for k, v in cookies.items())
|
||||||
|
headers.append(('Cookie', cookie_header))
|
||||||
|
response = fetch_url(
|
||||||
|
url, data=data, headers=headers,
|
||||||
|
debug_name='youtubei_' + api + '_' + client,
|
||||||
|
report_text='Fetched ' + client + ' youtubei ' + api
|
||||||
|
).decode('utf-8')
|
||||||
|
return response
|
||||||
871
youtube/watch.py
Normal file
871
youtube/watch.py
Normal file
@@ -0,0 +1,871 @@
|
|||||||
|
import youtube
|
||||||
|
from youtube import yt_app
|
||||||
|
from youtube import util, comments, local_playlist, yt_data_extract
|
||||||
|
import settings
|
||||||
|
|
||||||
|
from flask import request
|
||||||
|
import flask
|
||||||
|
|
||||||
|
import json
|
||||||
|
import html
|
||||||
|
import gevent
|
||||||
|
import os
|
||||||
|
import math
|
||||||
|
import traceback
|
||||||
|
import urllib
|
||||||
|
import re
|
||||||
|
import urllib3.exceptions
|
||||||
|
from urllib.parse import parse_qs, urlencode
|
||||||
|
from types import SimpleNamespace
|
||||||
|
from math import ceil
|
||||||
|
|
||||||
|
|
||||||
|
try:
|
||||||
|
with open(os.path.join(settings.data_dir, 'decrypt_function_cache.json'), 'r') as f:
|
||||||
|
decrypt_cache = json.loads(f.read())['decrypt_cache']
|
||||||
|
except FileNotFoundError:
|
||||||
|
decrypt_cache = {}
|
||||||
|
|
||||||
|
|
||||||
|
def codec_name(vcodec):
|
||||||
|
if vcodec.startswith('avc'):
|
||||||
|
return 'h264'
|
||||||
|
elif vcodec.startswith('av01'):
|
||||||
|
return 'av1'
|
||||||
|
elif vcodec.startswith('vp'):
|
||||||
|
return 'vp'
|
||||||
|
else:
|
||||||
|
return 'unknown'
|
||||||
|
|
||||||
|
|
||||||
|
def get_video_sources(info, target_resolution):
|
||||||
|
'''return dict with organized sources: {
|
||||||
|
'uni_sources': [{}, ...], # video and audio in one file
|
||||||
|
'uni_idx': int, # default unified source index
|
||||||
|
'pair_sources': [{video: {}, audio: {}, quality: ..., ...}, ...],
|
||||||
|
'pair_idx': int, # default pair source index
|
||||||
|
}
|
||||||
|
'''
|
||||||
|
audio_sources = []
|
||||||
|
video_only_sources = {}
|
||||||
|
uni_sources = []
|
||||||
|
pair_sources = []
|
||||||
|
|
||||||
|
|
||||||
|
for fmt in info['formats']:
|
||||||
|
if not all(fmt[attr] for attr in ('ext', 'url', 'itag')):
|
||||||
|
continue
|
||||||
|
|
||||||
|
# unified source
|
||||||
|
if fmt['acodec'] and fmt['vcodec']:
|
||||||
|
source = {
|
||||||
|
'type': 'video/' + fmt['ext'],
|
||||||
|
'quality_string': short_video_quality_string(fmt),
|
||||||
|
}
|
||||||
|
source['quality_string'] += ' (integrated)'
|
||||||
|
source.update(fmt)
|
||||||
|
uni_sources.append(source)
|
||||||
|
continue
|
||||||
|
|
||||||
|
if not (fmt['init_range'] and fmt['index_range']):
|
||||||
|
continue
|
||||||
|
|
||||||
|
# audio source
|
||||||
|
if fmt['acodec'] and not fmt['vcodec'] and (
|
||||||
|
fmt['audio_bitrate'] or fmt['bitrate']):
|
||||||
|
if fmt['bitrate']: # prefer this one, more accurate right now
|
||||||
|
fmt['audio_bitrate'] = int(fmt['bitrate']/1000)
|
||||||
|
source = {
|
||||||
|
'type': 'audio/' + fmt['ext'],
|
||||||
|
'quality_string': audio_quality_string(fmt),
|
||||||
|
}
|
||||||
|
source.update(fmt)
|
||||||
|
source['mime_codec'] = (source['type'] + '; codecs="'
|
||||||
|
+ source['acodec'] + '"')
|
||||||
|
audio_sources.append(source)
|
||||||
|
# video-only source
|
||||||
|
elif all(fmt[attr] for attr in ('vcodec', 'quality', 'width', 'fps',
|
||||||
|
'file_size')):
|
||||||
|
if codec_name(fmt['vcodec']) == 'unknown':
|
||||||
|
continue
|
||||||
|
source = {
|
||||||
|
'type': 'video/' + fmt['ext'],
|
||||||
|
'quality_string': short_video_quality_string(fmt),
|
||||||
|
}
|
||||||
|
source.update(fmt)
|
||||||
|
source['mime_codec'] = (source['type'] + '; codecs="'
|
||||||
|
+ source['vcodec'] + '"')
|
||||||
|
quality = str(fmt['quality']) + 'p' + str(fmt['fps'])
|
||||||
|
if quality in video_only_sources:
|
||||||
|
video_only_sources[quality].append(source)
|
||||||
|
else:
|
||||||
|
video_only_sources[quality] = [source]
|
||||||
|
|
||||||
|
audio_sources.sort(key=lambda source: source['audio_bitrate'])
|
||||||
|
uni_sources.sort(key=lambda src: src['quality'])
|
||||||
|
|
||||||
|
webm_audios = [a for a in audio_sources if a['ext'] == 'webm']
|
||||||
|
mp4_audios = [a for a in audio_sources if a['ext'] == 'mp4']
|
||||||
|
|
||||||
|
for quality_string, sources in video_only_sources.items():
|
||||||
|
# choose an audio source to go with it
|
||||||
|
# 0.5 is semiarbitrary empirical constant to spread audio sources
|
||||||
|
# between 144p and 1080p. Use something better eventually.
|
||||||
|
quality, fps = map(int, quality_string.split('p'))
|
||||||
|
target_audio_bitrate = quality*fps/30*0.5
|
||||||
|
pair_info = {
|
||||||
|
'quality_string': quality_string,
|
||||||
|
'quality': quality,
|
||||||
|
'height': sources[0]['height'],
|
||||||
|
'width': sources[0]['width'],
|
||||||
|
'fps': fps,
|
||||||
|
'videos': sources,
|
||||||
|
'audios': [],
|
||||||
|
}
|
||||||
|
for audio_choices in (webm_audios, mp4_audios):
|
||||||
|
if not audio_choices:
|
||||||
|
continue
|
||||||
|
closest_audio_source = audio_choices[0]
|
||||||
|
best_err = target_audio_bitrate - audio_choices[0]['audio_bitrate']
|
||||||
|
best_err = abs(best_err)
|
||||||
|
for audio_source in audio_choices[1:]:
|
||||||
|
err = abs(audio_source['audio_bitrate'] - target_audio_bitrate)
|
||||||
|
# once err gets worse we have passed the closest one
|
||||||
|
if err > best_err:
|
||||||
|
break
|
||||||
|
best_err = err
|
||||||
|
closest_audio_source = audio_source
|
||||||
|
pair_info['audios'].append(closest_audio_source)
|
||||||
|
|
||||||
|
if not pair_info['audios']:
|
||||||
|
continue
|
||||||
|
|
||||||
|
def video_rank(src):
|
||||||
|
''' Sort by settings preference. Use file size as tiebreaker '''
|
||||||
|
setting_name = 'codec_rank_' + codec_name(src['vcodec'])
|
||||||
|
return (settings.current_settings_dict[setting_name],
|
||||||
|
src['file_size'])
|
||||||
|
pair_info['videos'].sort(key=video_rank)
|
||||||
|
|
||||||
|
pair_sources.append(pair_info)
|
||||||
|
|
||||||
|
pair_sources.sort(key=lambda src: src['quality'])
|
||||||
|
|
||||||
|
uni_idx = 0 if uni_sources else None
|
||||||
|
for i, source in enumerate(uni_sources):
|
||||||
|
if source['quality'] > target_resolution:
|
||||||
|
break
|
||||||
|
uni_idx = i
|
||||||
|
|
||||||
|
pair_idx = 0 if pair_sources else None
|
||||||
|
for i, pair_info in enumerate(pair_sources):
|
||||||
|
if pair_info['quality'] > target_resolution:
|
||||||
|
break
|
||||||
|
pair_idx = i
|
||||||
|
|
||||||
|
return {
|
||||||
|
'uni_sources': uni_sources,
|
||||||
|
'uni_idx': uni_idx,
|
||||||
|
'pair_sources': pair_sources,
|
||||||
|
'pair_idx': pair_idx,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def make_caption_src(info, lang, auto=False, trans_lang=None):
|
||||||
|
label = lang
|
||||||
|
if auto:
|
||||||
|
label += ' (Automatic)'
|
||||||
|
if trans_lang:
|
||||||
|
label += ' -> ' + trans_lang
|
||||||
|
return {
|
||||||
|
'url': util.prefix_url(yt_data_extract.get_caption_url(info, lang, 'vtt', auto, trans_lang)),
|
||||||
|
'label': label,
|
||||||
|
'srclang': trans_lang[0:2] if trans_lang else lang[0:2],
|
||||||
|
'on': False,
|
||||||
|
}
|
||||||
|
|
||||||
|
def lang_in(lang, sequence):
|
||||||
|
'''Tests if the language is in sequence, with e.g. en and en-US considered the same'''
|
||||||
|
if lang is None:
|
||||||
|
return False
|
||||||
|
lang = lang[0:2]
|
||||||
|
return lang in (l[0:2] for l in sequence)
|
||||||
|
|
||||||
|
def lang_eq(lang1, lang2):
|
||||||
|
'''Tests if two iso 639-1 codes are equal, with en and en-US considered the same.
|
||||||
|
Just because the codes are equal does not mean the dialects are mutually intelligible, but this will have to do for now without a complex language model'''
|
||||||
|
if lang1 is None or lang2 is None:
|
||||||
|
return False
|
||||||
|
return lang1[0:2] == lang2[0:2]
|
||||||
|
|
||||||
|
def equiv_lang_in(lang, sequence):
|
||||||
|
'''Extracts a language in sequence which is equivalent to lang.
|
||||||
|
e.g. if lang is en, extracts en-GB from sequence.
|
||||||
|
Necessary because if only a specific variant like en-GB is available, can't ask Youtube for simply en. Need to get the available variant.'''
|
||||||
|
lang = lang[0:2]
|
||||||
|
for l in sequence:
|
||||||
|
if l[0:2] == lang:
|
||||||
|
return l
|
||||||
|
return None
|
||||||
|
|
||||||
|
def get_subtitle_sources(info):
|
||||||
|
'''Returns these sources, ordered from least to most intelligible:
|
||||||
|
native_video_lang (Automatic)
|
||||||
|
foreign_langs (Manual)
|
||||||
|
native_video_lang (Automatic) -> pref_lang
|
||||||
|
foreign_langs (Manual) -> pref_lang
|
||||||
|
native_video_lang (Manual) -> pref_lang
|
||||||
|
pref_lang (Automatic)
|
||||||
|
pref_lang (Manual)'''
|
||||||
|
sources = []
|
||||||
|
if not yt_data_extract.captions_available(info):
|
||||||
|
return []
|
||||||
|
pref_lang = settings.subtitles_language
|
||||||
|
native_video_lang = None
|
||||||
|
if info['automatic_caption_languages']:
|
||||||
|
native_video_lang = info['automatic_caption_languages'][0]
|
||||||
|
|
||||||
|
highest_fidelity_is_manual = False
|
||||||
|
|
||||||
|
# Sources are added in very specific order outlined above
|
||||||
|
# More intelligible sources are put further down to avoid browser bug when there are too many languages
|
||||||
|
# (in firefox, it is impossible to select a language near the top of the list because it is cut off)
|
||||||
|
|
||||||
|
# native_video_lang (Automatic)
|
||||||
|
if native_video_lang and not lang_eq(native_video_lang, pref_lang):
|
||||||
|
sources.append(make_caption_src(info, native_video_lang, auto=True))
|
||||||
|
|
||||||
|
# foreign_langs (Manual)
|
||||||
|
for lang in info['manual_caption_languages']:
|
||||||
|
if not lang_eq(lang, pref_lang):
|
||||||
|
sources.append(make_caption_src(info, lang))
|
||||||
|
|
||||||
|
if (lang_in(pref_lang, info['translation_languages'])
|
||||||
|
and not lang_in(pref_lang, info['automatic_caption_languages'])
|
||||||
|
and not lang_in(pref_lang, info['manual_caption_languages'])):
|
||||||
|
# native_video_lang (Automatic) -> pref_lang
|
||||||
|
if native_video_lang and not lang_eq(pref_lang, native_video_lang):
|
||||||
|
sources.append(make_caption_src(info, native_video_lang, auto=True, trans_lang=pref_lang))
|
||||||
|
|
||||||
|
# foreign_langs (Manual) -> pref_lang
|
||||||
|
for lang in info['manual_caption_languages']:
|
||||||
|
if not lang_eq(lang, native_video_lang) and not lang_eq(lang, pref_lang):
|
||||||
|
sources.append(make_caption_src(info, lang, trans_lang=pref_lang))
|
||||||
|
|
||||||
|
# native_video_lang (Manual) -> pref_lang
|
||||||
|
if lang_in(native_video_lang, info['manual_caption_languages']):
|
||||||
|
sources.append(make_caption_src(info, native_video_lang, trans_lang=pref_lang))
|
||||||
|
|
||||||
|
# pref_lang (Automatic)
|
||||||
|
if lang_in(pref_lang, info['automatic_caption_languages']):
|
||||||
|
sources.append(make_caption_src(info, equiv_lang_in(pref_lang, info['automatic_caption_languages']), auto=True))
|
||||||
|
|
||||||
|
# pref_lang (Manual)
|
||||||
|
if lang_in(pref_lang, info['manual_caption_languages']):
|
||||||
|
sources.append(make_caption_src(info, equiv_lang_in(pref_lang, info['manual_caption_languages'])))
|
||||||
|
highest_fidelity_is_manual = True
|
||||||
|
|
||||||
|
if sources and sources[-1]['srclang'] == pref_lang:
|
||||||
|
# set as on by default since it's manual a default-on subtitles mode is in settings
|
||||||
|
if highest_fidelity_is_manual and settings.subtitles_mode > 0:
|
||||||
|
sources[-1]['on'] = True
|
||||||
|
# set as on by default since settings indicate to set it as such even if it's not manual
|
||||||
|
elif settings.subtitles_mode == 2:
|
||||||
|
sources[-1]['on'] = True
|
||||||
|
|
||||||
|
if len(sources) == 0:
|
||||||
|
assert len(info['automatic_caption_languages']) == 0 and len(info['manual_caption_languages']) == 0
|
||||||
|
|
||||||
|
return sources
|
||||||
|
|
||||||
|
|
||||||
|
def get_ordered_music_list_attributes(music_list):
|
||||||
|
# get the set of attributes which are used by atleast 1 track
|
||||||
|
# so there isn't an empty, extraneous album column which no tracks use, for example
|
||||||
|
used_attributes = set()
|
||||||
|
for track in music_list:
|
||||||
|
used_attributes = used_attributes | track.keys()
|
||||||
|
|
||||||
|
# now put them in the right order
|
||||||
|
ordered_attributes = []
|
||||||
|
for attribute in ('Artist', 'Title', 'Album'):
|
||||||
|
if attribute.lower() in used_attributes:
|
||||||
|
ordered_attributes.append(attribute)
|
||||||
|
|
||||||
|
return ordered_attributes
|
||||||
|
|
||||||
|
def save_decrypt_cache():
|
||||||
|
try:
|
||||||
|
f = open(os.path.join(settings.data_dir, 'decrypt_function_cache.json'), 'w')
|
||||||
|
except FileNotFoundError:
|
||||||
|
os.makedirs(settings.data_dir)
|
||||||
|
f = open(os.path.join(settings.data_dir, 'decrypt_function_cache.json'), 'w')
|
||||||
|
|
||||||
|
f.write(json.dumps({'version': 1, 'decrypt_cache':decrypt_cache}, indent=4, sort_keys=True))
|
||||||
|
f.close()
|
||||||
|
|
||||||
|
def decrypt_signatures(info, video_id):
|
||||||
|
'''return error string, or False if no errors'''
|
||||||
|
if not yt_data_extract.requires_decryption(info):
|
||||||
|
return False
|
||||||
|
if not info['player_name']:
|
||||||
|
return 'Could not find player name'
|
||||||
|
|
||||||
|
player_name = info['player_name']
|
||||||
|
if player_name in decrypt_cache:
|
||||||
|
print('Using cached decryption function for: ' + player_name)
|
||||||
|
info['decryption_function'] = decrypt_cache[player_name]
|
||||||
|
else:
|
||||||
|
base_js = util.fetch_url(info['base_js'], debug_name='base.js', report_text='Fetched player ' + player_name)
|
||||||
|
base_js = base_js.decode('utf-8')
|
||||||
|
err = yt_data_extract.extract_decryption_function(info, base_js)
|
||||||
|
if err:
|
||||||
|
return err
|
||||||
|
decrypt_cache[player_name] = info['decryption_function']
|
||||||
|
save_decrypt_cache()
|
||||||
|
err = yt_data_extract.decrypt_signatures(info)
|
||||||
|
return err
|
||||||
|
|
||||||
|
|
||||||
|
def _add_to_error(info, key, additional_message):
|
||||||
|
if key in info and info[key]:
|
||||||
|
info[key] += additional_message
|
||||||
|
else:
|
||||||
|
info[key] = additional_message
|
||||||
|
|
||||||
|
def fetch_player_response(client, video_id):
|
||||||
|
return util.call_youtube_api(client, 'player', {
|
||||||
|
'videoId': video_id,
|
||||||
|
})
|
||||||
|
|
||||||
|
def fetch_watch_page_info(video_id, playlist_id, index):
|
||||||
|
# bpctr=9999999999 will bypass are-you-sure dialogs for controversial
|
||||||
|
# videos
|
||||||
|
url = 'https://m.youtube.com/embed/' + video_id + '?bpctr=9999999999'
|
||||||
|
if playlist_id:
|
||||||
|
url += '&list=' + playlist_id
|
||||||
|
if index:
|
||||||
|
url += '&index=' + index
|
||||||
|
|
||||||
|
headers = (
|
||||||
|
('Accept', '*/*'),
|
||||||
|
('Accept-Language', 'en-US,en;q=0.5'),
|
||||||
|
('X-YouTube-Client-Name', '2'),
|
||||||
|
('X-YouTube-Client-Version', '2.20180830'),
|
||||||
|
) + util.mobile_ua
|
||||||
|
|
||||||
|
watch_page = util.fetch_url(url, headers=headers,
|
||||||
|
debug_name='watch')
|
||||||
|
watch_page = watch_page.decode('utf-8')
|
||||||
|
return yt_data_extract.extract_watch_info_from_html(watch_page)
|
||||||
|
|
||||||
|
def extract_info(video_id, use_invidious, playlist_id=None, index=None):
|
||||||
|
tasks = (
|
||||||
|
# Get video metadata from here
|
||||||
|
gevent.spawn(fetch_watch_page_info, video_id, playlist_id, index),
|
||||||
|
|
||||||
|
|
||||||
|
gevent.spawn(fetch_player_response, 'android_vr', video_id)
|
||||||
|
)
|
||||||
|
gevent.joinall(tasks)
|
||||||
|
util.check_gevent_exceptions(*tasks)
|
||||||
|
info, player_response = tasks[0].value, tasks[1].value
|
||||||
|
|
||||||
|
yt_data_extract.update_with_new_urls(info, player_response)
|
||||||
|
|
||||||
|
# Age restricted video, retry
|
||||||
|
if info['age_restricted'] or info['player_urls_missing']:
|
||||||
|
if info['age_restricted']:
|
||||||
|
print('Age restricted video, retrying')
|
||||||
|
else:
|
||||||
|
print('Player urls missing, retrying')
|
||||||
|
player_response = fetch_player_response('tv_embedded', video_id)
|
||||||
|
yt_data_extract.update_with_new_urls(info, player_response)
|
||||||
|
|
||||||
|
# signature decryption
|
||||||
|
decryption_error = decrypt_signatures(info, video_id)
|
||||||
|
if decryption_error:
|
||||||
|
decryption_error = 'Error decrypting url signatures: ' + decryption_error
|
||||||
|
info['playability_error'] = decryption_error
|
||||||
|
|
||||||
|
# check if urls ready (non-live format) in former livestream
|
||||||
|
# urls not ready if all of them have no filesize
|
||||||
|
if info['was_live']:
|
||||||
|
info['urls_ready'] = False
|
||||||
|
for fmt in info['formats']:
|
||||||
|
if fmt['file_size'] is not None:
|
||||||
|
info['urls_ready'] = True
|
||||||
|
else:
|
||||||
|
info['urls_ready'] = True
|
||||||
|
|
||||||
|
# livestream urls
|
||||||
|
# sometimes only the livestream urls work soon after the livestream is over
|
||||||
|
if (info['hls_manifest_url']
|
||||||
|
and (info['live'] or not info['formats'] or not info['urls_ready'])
|
||||||
|
):
|
||||||
|
manifest = util.fetch_url(info['hls_manifest_url'],
|
||||||
|
debug_name='hls_manifest.m3u8',
|
||||||
|
report_text='Fetched hls manifest'
|
||||||
|
).decode('utf-8')
|
||||||
|
|
||||||
|
info['hls_formats'], err = yt_data_extract.extract_hls_formats(manifest)
|
||||||
|
if not err:
|
||||||
|
info['playability_error'] = None
|
||||||
|
for fmt in info['hls_formats']:
|
||||||
|
fmt['video_quality'] = video_quality_string(fmt)
|
||||||
|
else:
|
||||||
|
info['hls_formats'] = []
|
||||||
|
|
||||||
|
# check for 403. Unnecessary for tor video routing b/c ip address is same
|
||||||
|
info['invidious_used'] = False
|
||||||
|
info['invidious_reload_button'] = False
|
||||||
|
info['tor_bypass_used'] = False
|
||||||
|
if (settings.route_tor == 1
|
||||||
|
and info['formats'] and info['formats'][0]['url']):
|
||||||
|
try:
|
||||||
|
response = util.head(info['formats'][0]['url'],
|
||||||
|
report_text='Checked for URL access')
|
||||||
|
except urllib3.exceptions.HTTPError:
|
||||||
|
print('Error while checking for URL access:\n')
|
||||||
|
traceback.print_exc()
|
||||||
|
return info
|
||||||
|
|
||||||
|
if response.status == 403:
|
||||||
|
print('Access denied (403) for video urls.')
|
||||||
|
print('Routing video through Tor')
|
||||||
|
info['tor_bypass_used'] = True
|
||||||
|
for fmt in info['formats']:
|
||||||
|
fmt['url'] += '&use_tor=1'
|
||||||
|
elif 300 <= response.status < 400:
|
||||||
|
print('Error: exceeded max redirects while checking video URL')
|
||||||
|
return info
|
||||||
|
|
||||||
|
def video_quality_string(format):
|
||||||
|
if format['vcodec']:
|
||||||
|
result =str(format['width'] or '?') + 'x' + str(format['height'] or '?')
|
||||||
|
if format['fps']:
|
||||||
|
result += ' ' + str(format['fps']) + 'fps'
|
||||||
|
return result
|
||||||
|
elif format['acodec']:
|
||||||
|
return 'audio only'
|
||||||
|
|
||||||
|
return '?'
|
||||||
|
|
||||||
|
|
||||||
|
def short_video_quality_string(fmt):
|
||||||
|
result = str(fmt['quality'] or '?') + 'p'
|
||||||
|
if fmt['fps']:
|
||||||
|
result += str(fmt['fps'])
|
||||||
|
if fmt['vcodec'].startswith('av01'):
|
||||||
|
result += ' AV1'
|
||||||
|
elif fmt['vcodec'].startswith('avc'):
|
||||||
|
result += ' h264'
|
||||||
|
else:
|
||||||
|
result += ' ' + fmt['vcodec']
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
def audio_quality_string(fmt):
|
||||||
|
if fmt['acodec']:
|
||||||
|
if fmt['audio_bitrate']:
|
||||||
|
result = '%d' % fmt['audio_bitrate'] + 'k'
|
||||||
|
else:
|
||||||
|
result = '?k'
|
||||||
|
if fmt['audio_sample_rate']:
|
||||||
|
result += ' ' + '%.3G' % (fmt['audio_sample_rate']/1000) + 'kHz'
|
||||||
|
return result
|
||||||
|
elif fmt['vcodec']:
|
||||||
|
return 'video only'
|
||||||
|
return '?'
|
||||||
|
|
||||||
|
|
||||||
|
# from https://github.com/ytdl-org/youtube-dl/blob/master/youtube_dl/utils.py
|
||||||
|
def format_bytes(bytes):
|
||||||
|
if bytes is None:
|
||||||
|
return 'N/A'
|
||||||
|
if type(bytes) is str:
|
||||||
|
bytes = float(bytes)
|
||||||
|
if bytes == 0.0:
|
||||||
|
exponent = 0
|
||||||
|
else:
|
||||||
|
exponent = int(math.log(bytes, 1024.0))
|
||||||
|
suffix = ['B', 'KiB', 'MiB', 'GiB', 'TiB', 'PiB', 'EiB', 'ZiB', 'YiB'][exponent]
|
||||||
|
converted = float(bytes) / float(1024 ** exponent)
|
||||||
|
return '%.2f%s' % (converted, suffix)
|
||||||
|
|
||||||
|
@yt_app.route('/ytl-api/storyboard.vtt')
|
||||||
|
def get_storyboard_vtt():
|
||||||
|
"""
|
||||||
|
See:
|
||||||
|
https://github.com/iv-org/invidious/blob/9a8b81fcbe49ff8d88f197b7f731d6bf79fc8087/src/invidious.cr#L3603
|
||||||
|
https://github.com/iv-org/invidious/blob/3bb7fbb2f119790ee6675076b31cd990f75f64bb/src/invidious/videos.cr#L623
|
||||||
|
"""
|
||||||
|
|
||||||
|
spec_url = request.args.get('spec_url')
|
||||||
|
url, *boards = spec_url.split('|')
|
||||||
|
base_url, q = url.split('?')
|
||||||
|
q = parse_qs(q) # for url query
|
||||||
|
|
||||||
|
storyboard = None
|
||||||
|
wanted_height = 90
|
||||||
|
|
||||||
|
for i, board in enumerate(boards):
|
||||||
|
*t, _, sigh = board.split("#")
|
||||||
|
width, height, count, width_cnt, height_cnt, interval = map(int, t)
|
||||||
|
if height != wanted_height: continue
|
||||||
|
q['sigh'] = [sigh]
|
||||||
|
url = f"{base_url}?{urlencode(q, doseq=True)}"
|
||||||
|
storyboard = SimpleNamespace(
|
||||||
|
url = url.replace("$L", str(i)).replace("$N", "M$M"),
|
||||||
|
width = width,
|
||||||
|
height = height,
|
||||||
|
interval = interval,
|
||||||
|
width_cnt = width_cnt,
|
||||||
|
height_cnt = height_cnt,
|
||||||
|
storyboard_count = ceil(count / (width_cnt * height_cnt))
|
||||||
|
)
|
||||||
|
|
||||||
|
if not storyboard:
|
||||||
|
flask.abort(404)
|
||||||
|
|
||||||
|
def to_ts(ms):
|
||||||
|
s, ms = divmod(ms, 1000)
|
||||||
|
h, s = divmod(s, 3600)
|
||||||
|
m, s = divmod(s, 60)
|
||||||
|
return f"{h:02}:{m:02}:{s:02}.{ms:03}"
|
||||||
|
|
||||||
|
r = "WEBVTT" # result
|
||||||
|
ts = 0 # current timestamp
|
||||||
|
|
||||||
|
for i in range(storyboard.storyboard_count):
|
||||||
|
url = '/' + storyboard.url.replace("$M", str(i))
|
||||||
|
interval = storyboard.interval
|
||||||
|
w, h = storyboard.width, storyboard.height
|
||||||
|
w_cnt, h_cnt = storyboard.width_cnt, storyboard.height_cnt
|
||||||
|
|
||||||
|
for j in range(h_cnt):
|
||||||
|
for k in range(w_cnt):
|
||||||
|
r += f"{to_ts(ts)} --> {to_ts(ts+interval)}\n"
|
||||||
|
r += f"{url}#xywh={w * k},{h * j},{w},{h}\n\n"
|
||||||
|
ts += interval
|
||||||
|
|
||||||
|
return flask.Response(r, mimetype='text/vtt')
|
||||||
|
|
||||||
|
|
||||||
|
time_table = {'h': 3600, 'm': 60, 's': 1}
|
||||||
|
@yt_app.route('/watch')
|
||||||
|
@yt_app.route('/embed')
|
||||||
|
@yt_app.route('/embed/<video_id>')
|
||||||
|
@yt_app.route('/shorts')
|
||||||
|
@yt_app.route('/shorts/<video_id>')
|
||||||
|
def get_watch_page(video_id=None):
|
||||||
|
video_id = request.args.get('v') or video_id
|
||||||
|
if not video_id:
|
||||||
|
return flask.render_template('error.html', error_message='Missing video id'), 404
|
||||||
|
if len(video_id) < 11:
|
||||||
|
return flask.render_template('error.html', error_message='Incomplete video id (too short): ' + video_id), 404
|
||||||
|
|
||||||
|
time_start_str = request.args.get('t', '0s')
|
||||||
|
time_start = 0
|
||||||
|
if re.fullmatch(r'(\d+(h|m|s))+', time_start_str):
|
||||||
|
for match in re.finditer(r'(\d+)(h|m|s)', time_start_str):
|
||||||
|
time_start += int(match.group(1))*time_table[match.group(2)]
|
||||||
|
elif re.fullmatch(r'\d+', time_start_str):
|
||||||
|
time_start = int(time_start_str)
|
||||||
|
|
||||||
|
lc = request.args.get('lc', '')
|
||||||
|
playlist_id = request.args.get('list')
|
||||||
|
index = request.args.get('index')
|
||||||
|
use_invidious = bool(int(request.args.get('use_invidious', '1')))
|
||||||
|
if request.path.startswith('/embed') and settings.embed_page_mode:
|
||||||
|
tasks = (
|
||||||
|
gevent.spawn((lambda: {})),
|
||||||
|
gevent.spawn(extract_info, video_id, use_invidious,
|
||||||
|
playlist_id=playlist_id, index=index),
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
tasks = (
|
||||||
|
gevent.spawn(comments.video_comments, video_id,
|
||||||
|
int(settings.default_comment_sorting), lc=lc),
|
||||||
|
gevent.spawn(extract_info, video_id, use_invidious,
|
||||||
|
playlist_id=playlist_id, index=index),
|
||||||
|
)
|
||||||
|
gevent.joinall(tasks)
|
||||||
|
util.check_gevent_exceptions(tasks[1])
|
||||||
|
comments_info, info = tasks[0].value, tasks[1].value
|
||||||
|
|
||||||
|
if info['error']:
|
||||||
|
return flask.render_template('error.html', error_message = info['error'])
|
||||||
|
|
||||||
|
video_info = {
|
||||||
|
'duration': util.seconds_to_timestamp(info['duration'] or 0),
|
||||||
|
'id': info['id'],
|
||||||
|
'title': info['title'],
|
||||||
|
'author': info['author'],
|
||||||
|
'author_id': info['author_id'],
|
||||||
|
}
|
||||||
|
|
||||||
|
# prefix urls, and other post-processing not handled by yt_data_extract
|
||||||
|
for item in info['related_videos']:
|
||||||
|
util.prefix_urls(item)
|
||||||
|
util.add_extra_html_info(item)
|
||||||
|
for song in info['music_list']:
|
||||||
|
song['url'] = util.prefix_url(song['url'])
|
||||||
|
if info['playlist']:
|
||||||
|
playlist_id = info['playlist']['id']
|
||||||
|
for item in info['playlist']['items']:
|
||||||
|
util.prefix_urls(item)
|
||||||
|
util.add_extra_html_info(item)
|
||||||
|
if playlist_id:
|
||||||
|
item['url'] += '&list=' + playlist_id
|
||||||
|
if item['index']:
|
||||||
|
item['url'] += '&index=' + str(item['index'])
|
||||||
|
info['playlist']['author_url'] = util.prefix_url(
|
||||||
|
info['playlist']['author_url'])
|
||||||
|
if settings.img_prefix:
|
||||||
|
# Don't prefix hls_formats for now because the urls inside the manifest
|
||||||
|
# would need to be prefixed as well.
|
||||||
|
for fmt in info['formats']:
|
||||||
|
fmt['url'] = util.prefix_url(fmt['url'])
|
||||||
|
|
||||||
|
# Add video title to end of url path so it has a filename other than just
|
||||||
|
# "videoplayback" when downloaded
|
||||||
|
title = urllib.parse.quote(util.to_valid_filename(info['title'] or ''))
|
||||||
|
for fmt in info['formats']:
|
||||||
|
filename = title
|
||||||
|
ext = fmt.get('ext')
|
||||||
|
if ext:
|
||||||
|
filename += '.' + ext
|
||||||
|
fmt['url'] = fmt['url'].replace(
|
||||||
|
'/videoplayback',
|
||||||
|
'/videoplayback/name/' + filename)
|
||||||
|
|
||||||
|
|
||||||
|
download_formats = []
|
||||||
|
|
||||||
|
for format in (info['formats'] + info['hls_formats']):
|
||||||
|
if format['acodec'] and format['vcodec']:
|
||||||
|
codecs_string = format['acodec'] + ', ' + format['vcodec']
|
||||||
|
else:
|
||||||
|
codecs_string = format['acodec'] or format['vcodec'] or '?'
|
||||||
|
download_formats.append({
|
||||||
|
'url': format['url'],
|
||||||
|
'ext': format['ext'] or '?',
|
||||||
|
'audio_quality': audio_quality_string(format),
|
||||||
|
'video_quality': video_quality_string(format),
|
||||||
|
'file_size': format_bytes(format['file_size']),
|
||||||
|
'codecs': codecs_string,
|
||||||
|
})
|
||||||
|
|
||||||
|
if (settings.route_tor == 2) or info['tor_bypass_used']:
|
||||||
|
target_resolution = 240
|
||||||
|
else:
|
||||||
|
target_resolution = settings.default_resolution
|
||||||
|
|
||||||
|
source_info = get_video_sources(info, target_resolution)
|
||||||
|
uni_sources = source_info['uni_sources']
|
||||||
|
pair_sources = source_info['pair_sources']
|
||||||
|
uni_idx, pair_idx = source_info['uni_idx'], source_info['pair_idx']
|
||||||
|
|
||||||
|
pair_quality = yt_data_extract.deep_get(pair_sources, pair_idx, 'quality')
|
||||||
|
uni_quality = yt_data_extract.deep_get(uni_sources, uni_idx, 'quality')
|
||||||
|
|
||||||
|
pair_error = abs((pair_quality or 360) - target_resolution)
|
||||||
|
uni_error = abs((uni_quality or 360) - target_resolution)
|
||||||
|
if uni_error == pair_error:
|
||||||
|
# use settings.prefer_uni_sources as a tiebreaker
|
||||||
|
closer_to_target = 'uni' if settings.prefer_uni_sources else 'pair'
|
||||||
|
elif uni_error < pair_error:
|
||||||
|
closer_to_target = 'uni'
|
||||||
|
else:
|
||||||
|
closer_to_target = 'pair'
|
||||||
|
|
||||||
|
if settings.prefer_uni_sources == 2:
|
||||||
|
# Use uni sources unless there's no choice.
|
||||||
|
using_pair_sources = (
|
||||||
|
bool(pair_sources) and (not uni_sources)
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# Use the pair sources if they're closer to the desired resolution
|
||||||
|
using_pair_sources = (
|
||||||
|
bool(pair_sources)
|
||||||
|
and (not uni_sources or closer_to_target == 'pair')
|
||||||
|
)
|
||||||
|
if using_pair_sources:
|
||||||
|
video_height = pair_sources[pair_idx]['height']
|
||||||
|
video_width = pair_sources[pair_idx]['width']
|
||||||
|
else:
|
||||||
|
video_height = yt_data_extract.deep_get(
|
||||||
|
uni_sources, uni_idx, 'height', default=360
|
||||||
|
)
|
||||||
|
video_width = yt_data_extract.deep_get(
|
||||||
|
uni_sources, uni_idx, 'width', default=640
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# 1 second per pixel, or the actual video width
|
||||||
|
theater_video_target_width = max(640, info['duration'] or 0, video_width)
|
||||||
|
|
||||||
|
# Check for false determination of disabled comments, which comes from
|
||||||
|
# the watch page. But if we got comments in the separate request for those,
|
||||||
|
# then the determination is wrong.
|
||||||
|
if info['comments_disabled'] and comments_info.get('comments'):
|
||||||
|
info['comments_disabled'] = False
|
||||||
|
print('Warning: False determination that comments are disabled')
|
||||||
|
print('Comment count:', info['comment_count'])
|
||||||
|
info['comment_count'] = None # hack to make it obvious there's a bug
|
||||||
|
|
||||||
|
# captions and transcript
|
||||||
|
subtitle_sources = get_subtitle_sources(info)
|
||||||
|
other_downloads = []
|
||||||
|
for source in subtitle_sources:
|
||||||
|
best_caption_parse = urllib.parse.urlparse(
|
||||||
|
source['url'].lstrip('/'))
|
||||||
|
transcript_url = (util.URL_ORIGIN
|
||||||
|
+ '/watch/transcript'
|
||||||
|
+ best_caption_parse.path
|
||||||
|
+ '?' + best_caption_parse.query)
|
||||||
|
other_downloads.append({
|
||||||
|
'label': 'Video Transcript: ' + source['label'],
|
||||||
|
'ext': 'txt',
|
||||||
|
'url': transcript_url
|
||||||
|
})
|
||||||
|
|
||||||
|
if request.path.startswith('/embed') and settings.embed_page_mode:
|
||||||
|
template_name = 'embed.html'
|
||||||
|
else:
|
||||||
|
template_name = 'watch.html'
|
||||||
|
return flask.render_template(template_name,
|
||||||
|
header_playlist_names = local_playlist.get_playlist_names(),
|
||||||
|
uploader_channel_url = ('/' + info['author_url']) if info['author_url'] else '',
|
||||||
|
time_published = info['time_published'],
|
||||||
|
view_count = (lambda x: '{:,}'.format(x) if x is not None else "")(info.get("view_count", None)),
|
||||||
|
like_count = (lambda x: '{:,}'.format(x) if x is not None else "")(info.get("like_count", None)),
|
||||||
|
dislike_count = (lambda x: '{:,}'.format(x) if x is not None else "")(info.get("dislike_count", None)),
|
||||||
|
download_formats = download_formats,
|
||||||
|
other_downloads = other_downloads,
|
||||||
|
video_info = json.dumps(video_info),
|
||||||
|
hls_formats = info['hls_formats'],
|
||||||
|
subtitle_sources = subtitle_sources,
|
||||||
|
related = info['related_videos'],
|
||||||
|
playlist = info['playlist'],
|
||||||
|
music_list = info['music_list'],
|
||||||
|
music_attributes = get_ordered_music_list_attributes(info['music_list']),
|
||||||
|
comments_info = comments_info,
|
||||||
|
comment_count = info['comment_count'],
|
||||||
|
comments_disabled = info['comments_disabled'],
|
||||||
|
|
||||||
|
video_height = video_height,
|
||||||
|
video_width = video_width,
|
||||||
|
theater_video_target_width = theater_video_target_width,
|
||||||
|
|
||||||
|
title = info['title'],
|
||||||
|
uploader = info['author'],
|
||||||
|
description = info['description'],
|
||||||
|
unlisted = info['unlisted'],
|
||||||
|
limited_state = info['limited_state'],
|
||||||
|
age_restricted = info['age_restricted'],
|
||||||
|
live = info['live'],
|
||||||
|
playability_error = info['playability_error'],
|
||||||
|
|
||||||
|
allowed_countries = info['allowed_countries'],
|
||||||
|
ip_address = info['ip_address'] if settings.route_tor else None,
|
||||||
|
invidious_used = info['invidious_used'],
|
||||||
|
invidious_reload_button = info['invidious_reload_button'],
|
||||||
|
video_url = util.URL_ORIGIN + '/watch?v=' + video_id,
|
||||||
|
video_id = video_id,
|
||||||
|
storyboard_url = (util.URL_ORIGIN + '/ytl-api/storyboard.vtt?' +
|
||||||
|
urlencode([('spec_url', info['storyboard_spec_url'])])
|
||||||
|
if info['storyboard_spec_url'] else None),
|
||||||
|
|
||||||
|
js_data = {
|
||||||
|
'video_id': info['id'],
|
||||||
|
'video_duration': info['duration'],
|
||||||
|
'settings': settings.current_settings_dict,
|
||||||
|
'has_manual_captions': any(s.get('on') for s in subtitle_sources),
|
||||||
|
**source_info,
|
||||||
|
'using_pair_sources': using_pair_sources,
|
||||||
|
'time_start': time_start,
|
||||||
|
'playlist': info['playlist'],
|
||||||
|
'related': info['related_videos'],
|
||||||
|
'playability_error': info['playability_error'],
|
||||||
|
},
|
||||||
|
font_family = youtube.font_choices[settings.font], # for embed page
|
||||||
|
**source_info,
|
||||||
|
using_pair_sources = using_pair_sources,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@yt_app.route('/api/<path:dummy>')
|
||||||
|
def get_captions(dummy):
|
||||||
|
result = util.fetch_url('https://www.youtube.com' + request.full_path)
|
||||||
|
result = result.replace(b"align:start position:0%", b"")
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
times_reg = re.compile(r'^\d\d:\d\d:\d\d\.\d\d\d --> \d\d:\d\d:\d\d\.\d\d\d.*$')
|
||||||
|
inner_timestamp_removal_reg = re.compile(r'<[^>]+>')
|
||||||
|
@yt_app.route('/watch/transcript/<path:caption_path>')
|
||||||
|
def get_transcript(caption_path):
|
||||||
|
try:
|
||||||
|
captions = util.fetch_url('https://www.youtube.com/'
|
||||||
|
+ caption_path
|
||||||
|
+ '?' + request.environ['QUERY_STRING']).decode('utf-8')
|
||||||
|
except util.FetchError as e:
|
||||||
|
msg = ('Error retrieving captions: ' + str(e) + '\n\n'
|
||||||
|
+ 'The caption url may have expired.')
|
||||||
|
print(msg)
|
||||||
|
return flask.Response(msg,
|
||||||
|
status = e.code,
|
||||||
|
mimetype='text/plain;charset=UTF-8')
|
||||||
|
|
||||||
|
lines = captions.splitlines()
|
||||||
|
segments = []
|
||||||
|
|
||||||
|
# skip captions file header
|
||||||
|
i = 0
|
||||||
|
while lines[i] != '':
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
current_segment = None
|
||||||
|
while i < len(lines):
|
||||||
|
line = lines[i]
|
||||||
|
if line == '':
|
||||||
|
if ((current_segment is not None)
|
||||||
|
and (current_segment['begin'] is not None)):
|
||||||
|
segments.append(current_segment)
|
||||||
|
current_segment = {
|
||||||
|
'begin': None,
|
||||||
|
'end': None,
|
||||||
|
'lines': [],
|
||||||
|
}
|
||||||
|
elif times_reg.fullmatch(line.rstrip()):
|
||||||
|
current_segment['begin'], current_segment['end'] = line.split(' --> ')
|
||||||
|
else:
|
||||||
|
current_segment['lines'].append(
|
||||||
|
inner_timestamp_removal_reg.sub('', line))
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
# if automatic captions, but not translated
|
||||||
|
if request.args.get('kind') == 'asr' and not request.args.get('tlang'):
|
||||||
|
# Automatic captions repeat content. The new segment is displayed
|
||||||
|
# on the bottom row; the old one is displayed on the top row.
|
||||||
|
# So grab the bottom row only
|
||||||
|
for seg in segments:
|
||||||
|
seg['text'] = seg['lines'][1]
|
||||||
|
else:
|
||||||
|
for seg in segments:
|
||||||
|
seg['text'] = ' '.join(map(str.rstrip, seg['lines']))
|
||||||
|
|
||||||
|
result = ''
|
||||||
|
for seg in segments:
|
||||||
|
if seg['text'] != ' ':
|
||||||
|
result += seg['begin'] + ' ' + seg['text'] + '\r\n'
|
||||||
|
|
||||||
|
return flask.Response(result.encode('utf-8'),
|
||||||
|
mimetype='text/plain;charset=UTF-8')
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
13
youtube/yt_data_extract/__init__.py
Normal file
13
youtube/yt_data_extract/__init__.py
Normal file
@@ -0,0 +1,13 @@
|
|||||||
|
from .common import (get, multi_get, deep_get, multi_deep_get,
|
||||||
|
liberal_update, conservative_update, remove_redirect, normalize_url,
|
||||||
|
extract_str, extract_formatted_text, extract_int, extract_approx_int,
|
||||||
|
extract_date, extract_item_info, extract_items, extract_response)
|
||||||
|
|
||||||
|
from .everything_else import (extract_channel_info, extract_search_info,
|
||||||
|
extract_playlist_metadata, extract_playlist_info, extract_comments_info)
|
||||||
|
|
||||||
|
from .watch_extraction import (extract_watch_info, get_caption_url,
|
||||||
|
update_with_new_urls, requires_decryption,
|
||||||
|
extract_decryption_function, decrypt_signatures, _formats,
|
||||||
|
update_format_with_type_info, extract_hls_formats,
|
||||||
|
extract_watch_info_from_html, captions_available)
|
||||||
610
youtube/yt_data_extract/common.py
Normal file
610
youtube/yt_data_extract/common.py
Normal file
@@ -0,0 +1,610 @@
|
|||||||
|
import re
|
||||||
|
import urllib.parse
|
||||||
|
import collections
|
||||||
|
import collections.abc
|
||||||
|
|
||||||
|
def get(object, key, default=None, types=()):
|
||||||
|
'''Like dict.get(), but returns default if the result doesn't match one of the types.
|
||||||
|
Also works for indexing lists.'''
|
||||||
|
try:
|
||||||
|
result = object[key]
|
||||||
|
except (TypeError, IndexError, KeyError):
|
||||||
|
return default
|
||||||
|
|
||||||
|
if not types or isinstance(result, types):
|
||||||
|
return result
|
||||||
|
else:
|
||||||
|
return default
|
||||||
|
|
||||||
|
def multi_get(object, *keys, default=None, types=()):
|
||||||
|
'''Like get, but try other keys if the first fails'''
|
||||||
|
for key in keys:
|
||||||
|
try:
|
||||||
|
result = object[key]
|
||||||
|
except (TypeError, IndexError, KeyError):
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
if not types or isinstance(result, types):
|
||||||
|
return result
|
||||||
|
else:
|
||||||
|
continue
|
||||||
|
return default
|
||||||
|
|
||||||
|
|
||||||
|
def deep_get(object, *keys, default=None, types=()):
|
||||||
|
'''Like dict.get(), but for nested dictionaries/sequences, supporting keys or indices.
|
||||||
|
Last argument is the default value to use in case of any IndexErrors or KeyErrors.
|
||||||
|
If types is given and the result doesn't match one of those types, default is returned'''
|
||||||
|
try:
|
||||||
|
for key in keys:
|
||||||
|
object = object[key]
|
||||||
|
except (TypeError, IndexError, KeyError):
|
||||||
|
return default
|
||||||
|
else:
|
||||||
|
if not types or isinstance(object, types):
|
||||||
|
return object
|
||||||
|
else:
|
||||||
|
return default
|
||||||
|
|
||||||
|
def multi_deep_get(object, *key_sequences, default=None, types=()):
|
||||||
|
'''Like deep_get, but can try different key sequences in case one fails.
|
||||||
|
Return default if all of them fail. key_sequences is a list of lists'''
|
||||||
|
for key_sequence in key_sequences:
|
||||||
|
_object = object
|
||||||
|
try:
|
||||||
|
for key in key_sequence:
|
||||||
|
_object = _object[key]
|
||||||
|
except (TypeError, IndexError, KeyError):
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
if not types or isinstance(_object, types):
|
||||||
|
return _object
|
||||||
|
else:
|
||||||
|
continue
|
||||||
|
return default
|
||||||
|
|
||||||
|
|
||||||
|
def _is_empty(value):
|
||||||
|
'''Determines if value is None or an empty iterable, such as '' and []'''
|
||||||
|
if value is None:
|
||||||
|
return True
|
||||||
|
elif isinstance(value, collections.abc.Iterable) and not value:
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def liberal_update(obj, key, value):
|
||||||
|
'''Updates obj[key] with value as long as value is not None or empty.
|
||||||
|
Ensures obj[key] will at least get an empty value, however'''
|
||||||
|
if (not _is_empty(value)) or (key not in obj):
|
||||||
|
obj[key] = value
|
||||||
|
|
||||||
|
def conservative_update(obj, key, value):
|
||||||
|
'''Only updates obj if it doesn't have key or obj[key] is None/empty'''
|
||||||
|
if _is_empty(obj.get(key)):
|
||||||
|
obj[key] = value
|
||||||
|
|
||||||
|
|
||||||
|
def liberal_dict_update(dict1, dict2):
|
||||||
|
'''Update dict1 with keys from dict2 using liberal_update'''
|
||||||
|
for key, value in dict2.items():
|
||||||
|
liberal_update(dict1, key, value)
|
||||||
|
|
||||||
|
|
||||||
|
def conservative_dict_update(dict1, dict2):
|
||||||
|
'''Update dict1 with keys from dict2 using conservative_update'''
|
||||||
|
for key, value in dict2.items():
|
||||||
|
conservative_update(dict1, key, value)
|
||||||
|
|
||||||
|
|
||||||
|
def concat_or_none(*strings):
|
||||||
|
'''Concatenates strings. Returns None if any of the arguments are None'''
|
||||||
|
result = ''
|
||||||
|
for string in strings:
|
||||||
|
if string is None:
|
||||||
|
return None
|
||||||
|
result += string
|
||||||
|
return result
|
||||||
|
|
||||||
|
def remove_redirect(url):
|
||||||
|
if url is None:
|
||||||
|
return None
|
||||||
|
if re.fullmatch(r'(((https?:)?//)?(www.)?youtube.com)?/redirect\?.*', url) is not None: # youtube puts these on external links to do tracking
|
||||||
|
query_string = url[url.find('?')+1: ]
|
||||||
|
return urllib.parse.parse_qs(query_string)['q'][0]
|
||||||
|
return url
|
||||||
|
|
||||||
|
norm_url_re = re.compile(r'^(?:(?:https?:)?//)?((?:[\w-]+\.)+[\w-]+)?(/.*)$')
|
||||||
|
def normalize_url(url):
|
||||||
|
'''Insert https, resolve relative paths for youtube.com, and put www. infront of youtube.com'''
|
||||||
|
if url is None:
|
||||||
|
return None
|
||||||
|
match = norm_url_re.fullmatch(url)
|
||||||
|
if match is None:
|
||||||
|
raise Exception(url)
|
||||||
|
|
||||||
|
domain = match.group(1) or 'www.youtube.com'
|
||||||
|
if domain == 'youtube.com':
|
||||||
|
domain = 'www.youtube.com'
|
||||||
|
|
||||||
|
return 'https://' + domain + match.group(2)
|
||||||
|
|
||||||
|
def _recover_urls(runs):
|
||||||
|
for run in runs:
|
||||||
|
url = deep_get(run, 'navigationEndpoint', 'urlEndpoint', 'url')
|
||||||
|
text = run.get('text', '')
|
||||||
|
# second condition is necessary because youtube makes other things into urls, such as hashtags, which we want to keep as text
|
||||||
|
if url is not None and (text.startswith('http://') or text.startswith('https://')):
|
||||||
|
url = remove_redirect(url)
|
||||||
|
run['url'] = url
|
||||||
|
run['text'] = url # youtube truncates the url text, use actual url instead
|
||||||
|
|
||||||
|
def extract_str(node, default=None, recover_urls=False):
|
||||||
|
'''default is the value returned if the extraction fails. If recover_urls is true, will attempt to fix Youtube's truncation of url text (most prominently seen in descriptions)'''
|
||||||
|
if isinstance(node, str):
|
||||||
|
return node
|
||||||
|
|
||||||
|
try:
|
||||||
|
return node['simpleText']
|
||||||
|
except (KeyError, TypeError):
|
||||||
|
pass
|
||||||
|
|
||||||
|
if isinstance(node, dict) and 'runs' in node:
|
||||||
|
if recover_urls:
|
||||||
|
_recover_urls(node['runs'])
|
||||||
|
return ''.join(text_run.get('text', '') for text_run in node['runs'])
|
||||||
|
|
||||||
|
return default
|
||||||
|
|
||||||
|
def extract_formatted_text(node):
|
||||||
|
if not node:
|
||||||
|
return []
|
||||||
|
if 'runs' in node:
|
||||||
|
_recover_urls(node['runs'])
|
||||||
|
return node['runs']
|
||||||
|
elif 'simpleText' in node:
|
||||||
|
return [{'text': node['simpleText']}]
|
||||||
|
return []
|
||||||
|
|
||||||
|
def extract_int(string, default=None, whole_word=True):
|
||||||
|
if isinstance(string, int):
|
||||||
|
return string
|
||||||
|
if not isinstance(string, str):
|
||||||
|
string = extract_str(string)
|
||||||
|
if not string:
|
||||||
|
return default
|
||||||
|
if whole_word:
|
||||||
|
match = re.search(r'\b(\d+)\b', string.replace(',', ''))
|
||||||
|
else:
|
||||||
|
match = re.search(r'(\d+)', string.replace(',', ''))
|
||||||
|
if match is None:
|
||||||
|
return default
|
||||||
|
try:
|
||||||
|
return int(match.group(1))
|
||||||
|
except ValueError:
|
||||||
|
return default
|
||||||
|
|
||||||
|
def extract_approx_int(string):
|
||||||
|
'''e.g. "15.1M" from "15.1M subscribers" or '4,353' from 4353'''
|
||||||
|
if not isinstance(string, str):
|
||||||
|
string = extract_str(string)
|
||||||
|
if not string:
|
||||||
|
return None
|
||||||
|
match = re.search(r'\b(\d+(?:\.\d+)?[KMBTkmbt]?)\b', string.replace(',', ''))
|
||||||
|
if match is None:
|
||||||
|
return None
|
||||||
|
result = match.group(1)
|
||||||
|
if re.fullmatch(r'\d+', result):
|
||||||
|
result = '{:,}'.format(int(result))
|
||||||
|
return result
|
||||||
|
|
||||||
|
MONTH_ABBREVIATIONS = {'jan':'1', 'feb':'2', 'mar':'3', 'apr':'4', 'may':'5', 'jun':'6', 'jul':'7', 'aug':'8', 'sep':'9', 'oct':'10', 'nov':'11', 'dec':'12'}
|
||||||
|
def extract_date(date_text):
|
||||||
|
'''Input: "Mar 9, 2019". Output: "2019-3-9"'''
|
||||||
|
if not isinstance(date_text, str):
|
||||||
|
date_text = extract_str(date_text)
|
||||||
|
if date_text is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
date_text = date_text.replace(',', '').lower()
|
||||||
|
parts = date_text.split()
|
||||||
|
if len(parts) >= 3:
|
||||||
|
month, day, year = parts[-3:]
|
||||||
|
month = MONTH_ABBREVIATIONS.get(month[0:3]) # slicing in case they start writing out the full month name
|
||||||
|
if month and (re.fullmatch(r'\d\d?', day) is not None) and (re.fullmatch(r'\d{4}', year) is not None):
|
||||||
|
return year + '-' + month + '-' + day
|
||||||
|
return None
|
||||||
|
|
||||||
|
def check_missing_keys(object, *key_sequences):
|
||||||
|
for key_sequence in key_sequences:
|
||||||
|
_object = object
|
||||||
|
try:
|
||||||
|
for key in key_sequence:
|
||||||
|
_object = _object[key]
|
||||||
|
except (KeyError, IndexError, TypeError):
|
||||||
|
return 'Could not find ' + key
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
def extract_item_info(item, additional_info={}):
|
||||||
|
if not item:
|
||||||
|
return {'error': 'No item given'}
|
||||||
|
|
||||||
|
type = get(list(item.keys()), 0)
|
||||||
|
if not type:
|
||||||
|
return {'error': 'Could not find type'}
|
||||||
|
item = item[type]
|
||||||
|
|
||||||
|
info = {'error': None}
|
||||||
|
if type in ('itemSectionRenderer', 'compactAutoplayRenderer'):
|
||||||
|
return extract_item_info(deep_get(item, 'contents', 0), additional_info)
|
||||||
|
|
||||||
|
if type in ('movieRenderer', 'clarificationRenderer'):
|
||||||
|
info['type'] = 'unsupported'
|
||||||
|
return info
|
||||||
|
|
||||||
|
# type looks like e.g. 'compactVideoRenderer' or 'gridVideoRenderer'
|
||||||
|
# camelCase split, https://stackoverflow.com/a/37697078
|
||||||
|
type_parts = [s.lower() for s in re.sub(r'([A-Z][a-z]+)', r' \1', type).split()]
|
||||||
|
if len(type_parts) < 2:
|
||||||
|
info['type'] = 'unsupported'
|
||||||
|
return
|
||||||
|
primary_type = type_parts[-2]
|
||||||
|
if primary_type == 'video':
|
||||||
|
info['type'] = 'video'
|
||||||
|
elif type_parts[0] == 'reel': # shorts
|
||||||
|
info['type'] = 'video'
|
||||||
|
primary_type = 'video'
|
||||||
|
elif primary_type in ('playlist', 'radio', 'show'):
|
||||||
|
info['type'] = 'playlist'
|
||||||
|
info['playlist_type'] = primary_type
|
||||||
|
elif primary_type == 'channel':
|
||||||
|
info['type'] = 'channel'
|
||||||
|
elif type == 'videoWithContextRenderer': # stupid exception
|
||||||
|
info['type'] = 'video'
|
||||||
|
primary_type = 'video'
|
||||||
|
else:
|
||||||
|
info['type'] = 'unsupported'
|
||||||
|
|
||||||
|
# videoWithContextRenderer changes it to 'headline' just to be annoying
|
||||||
|
info['title'] = extract_str(multi_get(item, 'title', 'headline'))
|
||||||
|
if primary_type != 'channel':
|
||||||
|
info['author'] = extract_str(multi_get(item, 'longBylineText', 'shortBylineText', 'ownerText'))
|
||||||
|
info['author_id'] = extract_str(multi_deep_get(item,
|
||||||
|
['longBylineText', 'runs', 0, 'navigationEndpoint', 'browseEndpoint', 'browseId'],
|
||||||
|
['shortBylineText', 'runs', 0, 'navigationEndpoint', 'browseEndpoint', 'browseId'],
|
||||||
|
['ownerText', 'runs', 0, 'navigationEndpoint', 'browseEndpoint', 'browseId']
|
||||||
|
))
|
||||||
|
info['author_url'] = ('https://www.youtube.com/channel/' + info['author_id']) if info['author_id'] else None
|
||||||
|
info['description'] = extract_formatted_text(multi_deep_get(
|
||||||
|
item,
|
||||||
|
['descriptionText'], ['descriptionSnippet'],
|
||||||
|
['detailedMetadataSnippets', 0, 'snippetText'],
|
||||||
|
))
|
||||||
|
info['thumbnail'] = normalize_url(multi_deep_get(item,
|
||||||
|
['thumbnail', 'thumbnails', 0, 'url'], # videos
|
||||||
|
['thumbnails', 0, 'thumbnails', 0, 'url'], # playlists
|
||||||
|
['thumbnailRenderer', 'showCustomThumbnailRenderer', 'thumbnail', 'thumbnails', 0, 'url'], # shows
|
||||||
|
))
|
||||||
|
|
||||||
|
info['badges'] = []
|
||||||
|
for badge_node in multi_get(item, 'badges', 'ownerBadges', default=()):
|
||||||
|
badge = deep_get(badge_node, 'metadataBadgeRenderer', 'label')
|
||||||
|
if badge:
|
||||||
|
info['badges'].append(badge)
|
||||||
|
|
||||||
|
if primary_type in ('video', 'playlist'):
|
||||||
|
info['time_published'] = None
|
||||||
|
timestamp = re.search(r'(\d+ \w+ ago)',
|
||||||
|
extract_str(item.get('publishedTimeText'), default=''))
|
||||||
|
if timestamp:
|
||||||
|
info['time_published'] = timestamp.group(1)
|
||||||
|
|
||||||
|
if primary_type == 'video':
|
||||||
|
info['id'] = multi_deep_get(item,
|
||||||
|
['videoId'],
|
||||||
|
['navigationEndpoint', 'watchEndpoint', 'videoId'],
|
||||||
|
['navigationEndpoint', 'reelWatchEndpoint', 'videoId'] # shorts
|
||||||
|
)
|
||||||
|
info['view_count'] = extract_int(item.get('viewCountText'))
|
||||||
|
|
||||||
|
# dig into accessibility data to get view_count for videos marked as recommended, and to get time_published
|
||||||
|
accessibility_label = multi_deep_get(item,
|
||||||
|
['title', 'accessibility', 'accessibilityData', 'label'],
|
||||||
|
['headline', 'accessibility', 'accessibilityData', 'label'],
|
||||||
|
default='')
|
||||||
|
timestamp = re.search(r'(\d+ \w+ ago)', accessibility_label)
|
||||||
|
if timestamp:
|
||||||
|
conservative_update(info, 'time_published', timestamp.group(1))
|
||||||
|
view_count = re.search(r'(\d+) views', accessibility_label.replace(',', ''))
|
||||||
|
if view_count:
|
||||||
|
conservative_update(info, 'view_count', int(view_count.group(1)))
|
||||||
|
|
||||||
|
if info['view_count']:
|
||||||
|
info['approx_view_count'] = '{:,}'.format(info['view_count'])
|
||||||
|
else:
|
||||||
|
info['approx_view_count'] = extract_approx_int(multi_get(item,
|
||||||
|
'shortViewCountText',
|
||||||
|
'viewCountText' # shorts
|
||||||
|
))
|
||||||
|
|
||||||
|
# handle case where it is "No views"
|
||||||
|
if not info['approx_view_count']:
|
||||||
|
if ('No views' in item.get('shortViewCountText', '')
|
||||||
|
or 'no views' in accessibility_label.lower()
|
||||||
|
or 'No views' in extract_str(item.get('viewCountText', '')) # shorts
|
||||||
|
):
|
||||||
|
info['view_count'] = 0
|
||||||
|
info['approx_view_count'] = '0'
|
||||||
|
|
||||||
|
info['duration'] = extract_str(item.get('lengthText'))
|
||||||
|
|
||||||
|
# dig into accessibility data to get duration for shorts
|
||||||
|
accessibility_label = deep_get(item,
|
||||||
|
'accessibility', 'accessibilityData', 'label',
|
||||||
|
default='')
|
||||||
|
duration = re.search(r'(\d+) (second|seconds|minute) - play video$',
|
||||||
|
accessibility_label)
|
||||||
|
if duration:
|
||||||
|
if duration.group(2) == 'minute':
|
||||||
|
conservative_update(info, 'duration', '1:00')
|
||||||
|
else:
|
||||||
|
conservative_update(info,
|
||||||
|
'duration', '0:' + duration.group(1).zfill(2))
|
||||||
|
|
||||||
|
# if it's an item in a playlist, get its index
|
||||||
|
if 'index' in item: # url has wrong index on playlist page
|
||||||
|
info['index'] = extract_int(item.get('index'))
|
||||||
|
elif 'indexText' in item:
|
||||||
|
# Current item in playlist has ▶ instead of the actual index, must
|
||||||
|
# dig into url
|
||||||
|
match = re.search(r'index=(\d+)', deep_get(item,
|
||||||
|
'navigationEndpoint', 'commandMetadata', 'webCommandMetadata',
|
||||||
|
'url', default=''))
|
||||||
|
if match is None: # worth a try then
|
||||||
|
info['index'] = extract_int(item.get('indexText'))
|
||||||
|
else:
|
||||||
|
info['index'] = int(match.group(1))
|
||||||
|
else:
|
||||||
|
info['index'] = None
|
||||||
|
|
||||||
|
elif primary_type in ('playlist', 'radio'):
|
||||||
|
info['id'] = item.get('playlistId')
|
||||||
|
info['video_count'] = extract_int(item.get('videoCount'))
|
||||||
|
info['first_video_id'] = deep_get(item, 'navigationEndpoint',
|
||||||
|
'watchEndpoint', 'videoId')
|
||||||
|
elif primary_type == 'channel':
|
||||||
|
info['id'] = item.get('channelId')
|
||||||
|
info['approx_subscriber_count'] = extract_approx_int(item.get('subscriberCountText'))
|
||||||
|
elif primary_type == 'show':
|
||||||
|
info['id'] = deep_get(item, 'navigationEndpoint', 'watchEndpoint', 'playlistId')
|
||||||
|
info['first_video_id'] = deep_get(item, 'navigationEndpoint',
|
||||||
|
'watchEndpoint', 'videoId')
|
||||||
|
|
||||||
|
if primary_type in ('playlist', 'channel'):
|
||||||
|
conservative_update(info, 'video_count', extract_int(item.get('videoCountText')))
|
||||||
|
|
||||||
|
for overlay in item.get('thumbnailOverlays', []):
|
||||||
|
conservative_update(info, 'duration', extract_str(deep_get(
|
||||||
|
overlay, 'thumbnailOverlayTimeStatusRenderer', 'text'
|
||||||
|
)))
|
||||||
|
# show renderers don't have videoCountText
|
||||||
|
conservative_update(info, 'video_count', extract_int(deep_get(
|
||||||
|
overlay, 'thumbnailOverlayBottomPanelRenderer', 'text'
|
||||||
|
)))
|
||||||
|
|
||||||
|
info.update(additional_info)
|
||||||
|
|
||||||
|
return info
|
||||||
|
|
||||||
|
def extract_response(polymer_json):
|
||||||
|
'''return response, error'''
|
||||||
|
# /youtubei/v1/browse endpoint returns response directly
|
||||||
|
if isinstance(polymer_json, dict) and 'responseContext' in polymer_json:
|
||||||
|
# this is the response
|
||||||
|
return polymer_json, None
|
||||||
|
|
||||||
|
response = multi_deep_get(polymer_json, [1, 'response'], ['response'])
|
||||||
|
if response is None:
|
||||||
|
return None, 'Failed to extract response'
|
||||||
|
else:
|
||||||
|
return response, None
|
||||||
|
|
||||||
|
|
||||||
|
_item_types = {
|
||||||
|
'movieRenderer',
|
||||||
|
'didYouMeanRenderer',
|
||||||
|
'showingResultsForRenderer',
|
||||||
|
|
||||||
|
'videoRenderer',
|
||||||
|
'compactVideoRenderer',
|
||||||
|
'compactAutoplayRenderer',
|
||||||
|
'videoWithContextRenderer',
|
||||||
|
'gridVideoRenderer',
|
||||||
|
'playlistVideoRenderer',
|
||||||
|
|
||||||
|
'reelItemRenderer',
|
||||||
|
|
||||||
|
'playlistRenderer',
|
||||||
|
'compactPlaylistRenderer',
|
||||||
|
'gridPlaylistRenderer',
|
||||||
|
|
||||||
|
'radioRenderer',
|
||||||
|
'compactRadioRenderer',
|
||||||
|
'gridRadioRenderer',
|
||||||
|
|
||||||
|
'showRenderer',
|
||||||
|
'compactShowRenderer',
|
||||||
|
'gridShowRenderer',
|
||||||
|
|
||||||
|
|
||||||
|
'channelRenderer',
|
||||||
|
'compactChannelRenderer',
|
||||||
|
'gridChannelRenderer',
|
||||||
|
}
|
||||||
|
|
||||||
|
def _traverse_browse_renderer(renderer):
|
||||||
|
for tab in get(renderer, 'tabs', ()):
|
||||||
|
tab_renderer = multi_get(tab, 'tabRenderer', 'expandableTabRenderer')
|
||||||
|
if tab_renderer is None:
|
||||||
|
continue
|
||||||
|
if tab_renderer.get('selected', False):
|
||||||
|
return get(tab_renderer, 'content', {})
|
||||||
|
print('Could not find tab with content')
|
||||||
|
return {}
|
||||||
|
|
||||||
|
def _traverse_standard_list(renderer):
|
||||||
|
renderer_list = multi_get(renderer, 'contents', 'items', default=())
|
||||||
|
continuation = deep_get(renderer, 'continuations', 0, 'nextContinuationData', 'continuation')
|
||||||
|
return renderer_list, continuation
|
||||||
|
|
||||||
|
# these renderers contain one inside them
|
||||||
|
nested_renderer_dispatch = {
|
||||||
|
'singleColumnBrowseResultsRenderer': _traverse_browse_renderer,
|
||||||
|
'twoColumnBrowseResultsRenderer': _traverse_browse_renderer,
|
||||||
|
'twoColumnSearchResultsRenderer': lambda r: get(r, 'primaryContents', {}),
|
||||||
|
'richItemRenderer': lambda r: get(r, 'content', {}),
|
||||||
|
'engagementPanelSectionListRenderer': lambda r: get(r, 'content', {}),
|
||||||
|
}
|
||||||
|
|
||||||
|
# these renderers contain a list of renderers inside them
|
||||||
|
nested_renderer_list_dispatch = {
|
||||||
|
'sectionListRenderer': _traverse_standard_list,
|
||||||
|
'itemSectionRenderer': _traverse_standard_list,
|
||||||
|
'gridRenderer': _traverse_standard_list,
|
||||||
|
'richGridRenderer': _traverse_standard_list,
|
||||||
|
'playlistVideoListRenderer': _traverse_standard_list,
|
||||||
|
'structuredDescriptionContentRenderer': _traverse_standard_list,
|
||||||
|
'slimVideoMetadataSectionRenderer': _traverse_standard_list,
|
||||||
|
'singleColumnWatchNextResults': lambda r: (deep_get(r, 'results', 'results', 'contents', default=[]), None),
|
||||||
|
}
|
||||||
|
def get_nested_renderer_list_function(key):
|
||||||
|
if key in nested_renderer_list_dispatch:
|
||||||
|
return nested_renderer_list_dispatch[key]
|
||||||
|
elif key.endswith('Continuation'):
|
||||||
|
return _traverse_standard_list
|
||||||
|
return None
|
||||||
|
|
||||||
|
def extract_items_from_renderer(renderer, item_types=_item_types):
|
||||||
|
ctoken = None
|
||||||
|
items = []
|
||||||
|
|
||||||
|
iter_stack = collections.deque()
|
||||||
|
current_iter = iter(())
|
||||||
|
|
||||||
|
while True:
|
||||||
|
# mode 1: get a new renderer by iterating.
|
||||||
|
# goes down the stack for an iterator if one has been exhausted
|
||||||
|
if not renderer:
|
||||||
|
try:
|
||||||
|
renderer = current_iter.__next__()
|
||||||
|
except StopIteration:
|
||||||
|
try:
|
||||||
|
current_iter = iter_stack.pop()
|
||||||
|
except IndexError:
|
||||||
|
return items, ctoken
|
||||||
|
# Get new renderer or check that the one we got is good before
|
||||||
|
# proceeding to mode 2
|
||||||
|
continue
|
||||||
|
|
||||||
|
|
||||||
|
# mode 2: dig into the current renderer
|
||||||
|
key, value = list(renderer.items())[0]
|
||||||
|
|
||||||
|
# the renderer is an item
|
||||||
|
if key in item_types:
|
||||||
|
items.append(renderer)
|
||||||
|
|
||||||
|
# ctoken sometimes placed in these renderers, e.g. channel playlists
|
||||||
|
elif key == 'continuationItemRenderer':
|
||||||
|
cont = deep_get(
|
||||||
|
value, 'continuationEndpoint', 'continuationCommand', 'token'
|
||||||
|
)
|
||||||
|
if cont:
|
||||||
|
ctoken = cont
|
||||||
|
|
||||||
|
# has a list in it, add it to the iter stack
|
||||||
|
elif get_nested_renderer_list_function(key):
|
||||||
|
renderer_list, cont = get_nested_renderer_list_function(key)(value)
|
||||||
|
if renderer_list:
|
||||||
|
iter_stack.append(current_iter)
|
||||||
|
current_iter = iter(renderer_list)
|
||||||
|
if cont:
|
||||||
|
ctoken = cont
|
||||||
|
|
||||||
|
# new renderer nested inside this one
|
||||||
|
elif key in nested_renderer_dispatch:
|
||||||
|
renderer = nested_renderer_dispatch[key](value)
|
||||||
|
continue # don't reset renderer to None
|
||||||
|
|
||||||
|
renderer = None
|
||||||
|
|
||||||
|
|
||||||
|
def extract_items_from_renderer_list(renderers, item_types=_item_types):
|
||||||
|
'''Same as extract_items_from_renderer, but provide a list of renderers'''
|
||||||
|
items = []
|
||||||
|
ctoken = None
|
||||||
|
for renderer in renderers:
|
||||||
|
new_items, new_ctoken = extract_items_from_renderer(
|
||||||
|
renderer,
|
||||||
|
item_types=item_types)
|
||||||
|
items += new_items
|
||||||
|
# prioritize ctoken associated with items
|
||||||
|
if (not ctoken) or (new_ctoken and new_items):
|
||||||
|
ctoken = new_ctoken
|
||||||
|
return items, ctoken
|
||||||
|
|
||||||
|
|
||||||
|
def extract_items(response, item_types=_item_types,
|
||||||
|
search_engagement_panels=False):
|
||||||
|
'''return items, ctoken'''
|
||||||
|
items = []
|
||||||
|
ctoken = None
|
||||||
|
if 'continuationContents' in response:
|
||||||
|
# sometimes there's another, empty, junk [something]Continuation key
|
||||||
|
# find real one
|
||||||
|
for key, renderer_cont in get(response,
|
||||||
|
'continuationContents', {}).items():
|
||||||
|
# e.g. commentSectionContinuation, playlistVideoListContinuation
|
||||||
|
if key.endswith('Continuation'):
|
||||||
|
items, ctoken = extract_items_from_renderer(
|
||||||
|
{key: renderer_cont},
|
||||||
|
item_types=item_types)
|
||||||
|
if items:
|
||||||
|
break
|
||||||
|
if ('onResponseReceivedEndpoints' in response
|
||||||
|
or 'onResponseReceivedActions' in response):
|
||||||
|
for endpoint in multi_get(response,
|
||||||
|
'onResponseReceivedEndpoints',
|
||||||
|
'onResponseReceivedActions',
|
||||||
|
[]):
|
||||||
|
new_items, new_ctoken = extract_items_from_renderer_list(
|
||||||
|
multi_deep_get(
|
||||||
|
endpoint,
|
||||||
|
['reloadContinuationItemsCommand', 'continuationItems'],
|
||||||
|
['appendContinuationItemsAction', 'continuationItems'],
|
||||||
|
default=[]
|
||||||
|
),
|
||||||
|
item_types=item_types,
|
||||||
|
)
|
||||||
|
items += new_items
|
||||||
|
if (not ctoken) or (new_ctoken and new_items):
|
||||||
|
ctoken = new_ctoken
|
||||||
|
if 'contents' in response:
|
||||||
|
renderer = get(response, 'contents', {})
|
||||||
|
new_items, new_ctoken = extract_items_from_renderer(
|
||||||
|
renderer,
|
||||||
|
item_types=item_types)
|
||||||
|
items += new_items
|
||||||
|
if (not ctoken) or (new_ctoken and new_items):
|
||||||
|
ctoken = new_ctoken
|
||||||
|
|
||||||
|
if search_engagement_panels and 'engagementPanels' in response:
|
||||||
|
new_items, new_ctoken = extract_items_from_renderer_list(
|
||||||
|
response['engagementPanels'], item_types=item_types
|
||||||
|
)
|
||||||
|
items += new_items
|
||||||
|
if (not ctoken) or (new_ctoken and new_items):
|
||||||
|
ctoken = new_ctoken
|
||||||
|
|
||||||
|
return items, ctoken
|
||||||
372
youtube/yt_data_extract/everything_else.py
Normal file
372
youtube/yt_data_extract/everything_else.py
Normal file
@@ -0,0 +1,372 @@
|
|||||||
|
from .common import (get, multi_get, deep_get, multi_deep_get,
|
||||||
|
liberal_update, conservative_update, remove_redirect, normalize_url,
|
||||||
|
extract_str, extract_formatted_text, extract_int, extract_approx_int,
|
||||||
|
extract_date, check_missing_keys, extract_item_info, extract_items,
|
||||||
|
extract_response)
|
||||||
|
from youtube import proto
|
||||||
|
|
||||||
|
import re
|
||||||
|
import urllib
|
||||||
|
from math import ceil
|
||||||
|
|
||||||
|
def extract_channel_info(polymer_json, tab, continuation=False):
|
||||||
|
response, err = extract_response(polymer_json)
|
||||||
|
if err:
|
||||||
|
return {'error': err}
|
||||||
|
|
||||||
|
|
||||||
|
metadata = deep_get(response, 'metadata', 'channelMetadataRenderer',
|
||||||
|
default={})
|
||||||
|
if not metadata:
|
||||||
|
metadata = deep_get(response, 'microformat', 'microformatDataRenderer',
|
||||||
|
default={})
|
||||||
|
|
||||||
|
# channel doesn't exist or was terminated
|
||||||
|
# example terminated channel: https://www.youtube.com/channel/UCnKJeK_r90jDdIuzHXC0Org
|
||||||
|
# metadata and microformat are not present for continuation requests
|
||||||
|
if not metadata and not continuation:
|
||||||
|
if response.get('alerts'):
|
||||||
|
error_string = ' '.join(
|
||||||
|
extract_str(deep_get(alert, 'alertRenderer', 'text'), default='')
|
||||||
|
for alert in response['alerts']
|
||||||
|
)
|
||||||
|
if not error_string:
|
||||||
|
error_string = 'Failed to extract error'
|
||||||
|
return {'error': error_string}
|
||||||
|
elif deep_get(response, 'responseContext', 'errors'):
|
||||||
|
for error in response['responseContext']['errors'].get('error', []):
|
||||||
|
if error.get('code') == 'INVALID_VALUE' and error.get('location') == 'browse_id':
|
||||||
|
return {'error': 'This channel does not exist'}
|
||||||
|
return {'error': 'Failure getting metadata'}
|
||||||
|
|
||||||
|
info = {'error': None}
|
||||||
|
info['current_tab'] = tab
|
||||||
|
|
||||||
|
info['approx_subscriber_count'] = extract_approx_int(deep_get(response,
|
||||||
|
'header', 'c4TabbedHeaderRenderer', 'subscriberCountText'))
|
||||||
|
|
||||||
|
# stuff from microformat (info given by youtube for first page on channel)
|
||||||
|
info['short_description'] = metadata.get('description')
|
||||||
|
if info['short_description'] and len(info['short_description']) > 730:
|
||||||
|
info['short_description'] = info['short_description'][0:730] + '...'
|
||||||
|
info['channel_name'] = metadata.get('title')
|
||||||
|
info['avatar'] = normalize_url(multi_deep_get(metadata,
|
||||||
|
['avatar', 'thumbnails', 0, 'url'],
|
||||||
|
['thumbnail', 'thumbnails', 0, 'url'],
|
||||||
|
))
|
||||||
|
channel_url = multi_get(metadata, 'urlCanonical', 'channelUrl')
|
||||||
|
if channel_url:
|
||||||
|
channel_id = get(channel_url.rstrip('/').split('/'), -1)
|
||||||
|
info['channel_id'] = channel_id
|
||||||
|
else:
|
||||||
|
info['channel_id'] = metadata.get('externalId')
|
||||||
|
if info['channel_id']:
|
||||||
|
info['channel_url'] = 'https://www.youtube.com/channel/' + channel_id
|
||||||
|
else:
|
||||||
|
info['channel_url'] = None
|
||||||
|
|
||||||
|
# get items
|
||||||
|
info['items'] = []
|
||||||
|
info['ctoken'] = None
|
||||||
|
|
||||||
|
# empty channel
|
||||||
|
#if 'contents' not in response and 'continuationContents' not in response:
|
||||||
|
# return info
|
||||||
|
|
||||||
|
if tab in ('videos', 'shorts', 'streams', 'playlists', 'search'):
|
||||||
|
items, ctoken = extract_items(response)
|
||||||
|
additional_info = {
|
||||||
|
'author': info['channel_name'],
|
||||||
|
'author_id': info['channel_id'],
|
||||||
|
'author_url': info['channel_url'],
|
||||||
|
}
|
||||||
|
info['items'] = [extract_item_info(renderer, additional_info) for renderer in items]
|
||||||
|
info['ctoken'] = ctoken
|
||||||
|
if tab in ('search', 'playlists'):
|
||||||
|
info['is_last_page'] = (ctoken is None)
|
||||||
|
elif tab == 'about':
|
||||||
|
# Latest type
|
||||||
|
items, _ = extract_items(response, item_types={'aboutChannelRenderer'})
|
||||||
|
if items:
|
||||||
|
a_metadata = deep_get(items, 0, 'aboutChannelRenderer',
|
||||||
|
'metadata', 'aboutChannelViewModel')
|
||||||
|
if not a_metadata:
|
||||||
|
info['error'] = 'Could not find aboutChannelViewModel'
|
||||||
|
return info
|
||||||
|
|
||||||
|
info['links'] = []
|
||||||
|
for link_outer in a_metadata.get('links', ()):
|
||||||
|
link = link_outer.get('channelExternalLinkViewModel') or {}
|
||||||
|
link_content = extract_str(deep_get(link, 'link', 'content'))
|
||||||
|
for run in deep_get(link, 'link', 'commandRuns') or ():
|
||||||
|
url = remove_redirect(deep_get(run, 'onTap',
|
||||||
|
'innertubeCommand', 'urlEndpoint', 'url'))
|
||||||
|
if url and not (url.startswith('http://')
|
||||||
|
or url.startswith('https://')):
|
||||||
|
url = 'https://' + url
|
||||||
|
if link_content is None or (link_content in url):
|
||||||
|
break
|
||||||
|
else: # didn't break
|
||||||
|
url = link_content
|
||||||
|
if url and not (url.startswith('http://')
|
||||||
|
or url.startswith('https://')):
|
||||||
|
url = 'https://' + url
|
||||||
|
text = extract_str(deep_get(link, 'title', 'content'))
|
||||||
|
info['links'].append( (text, url) )
|
||||||
|
|
||||||
|
info['date_joined'] = extract_date(
|
||||||
|
a_metadata.get('joinedDateText')
|
||||||
|
)
|
||||||
|
info['view_count'] = extract_int(a_metadata.get('viewCountText'))
|
||||||
|
info['approx_view_count'] = extract_approx_int(
|
||||||
|
a_metadata.get('viewCountText')
|
||||||
|
)
|
||||||
|
info['description'] = extract_str(
|
||||||
|
a_metadata.get('description'), default=''
|
||||||
|
)
|
||||||
|
info['approx_video_count'] = extract_approx_int(
|
||||||
|
a_metadata.get('videoCountText')
|
||||||
|
)
|
||||||
|
info['approx_subscriber_count'] = extract_approx_int(
|
||||||
|
a_metadata.get('subscriberCountText')
|
||||||
|
)
|
||||||
|
info['country'] = extract_str(a_metadata.get('country'))
|
||||||
|
info['canonical_url'] = extract_str(
|
||||||
|
a_metadata.get('canonicalChannelUrl')
|
||||||
|
)
|
||||||
|
|
||||||
|
# Old type
|
||||||
|
else:
|
||||||
|
items, _ = extract_items(response,
|
||||||
|
item_types={'channelAboutFullMetadataRenderer'})
|
||||||
|
if not items:
|
||||||
|
info['error'] = 'Could not find aboutChannelRenderer or channelAboutFullMetadataRenderer'
|
||||||
|
return info
|
||||||
|
a_metadata = items[0]['channelAboutFullMetadataRenderer']
|
||||||
|
|
||||||
|
info['links'] = []
|
||||||
|
for link_json in a_metadata.get('primaryLinks', ()):
|
||||||
|
url = remove_redirect(deep_get(link_json, 'navigationEndpoint',
|
||||||
|
'urlEndpoint', 'url'))
|
||||||
|
if url and not (url.startswith('http://')
|
||||||
|
or url.startswith('https://')):
|
||||||
|
url = 'https://' + url
|
||||||
|
text = extract_str(link_json.get('title'))
|
||||||
|
info['links'].append( (text, url) )
|
||||||
|
|
||||||
|
info['date_joined'] = extract_date(a_metadata.get('joinedDateText'))
|
||||||
|
info['view_count'] = extract_int(a_metadata.get('viewCountText'))
|
||||||
|
info['description'] = extract_str(a_metadata.get(
|
||||||
|
'description'), default='')
|
||||||
|
|
||||||
|
info['approx_video_count'] = None
|
||||||
|
info['approx_subscriber_count'] = None
|
||||||
|
info['country'] = None
|
||||||
|
info['canonical_url'] = None
|
||||||
|
else:
|
||||||
|
raise NotImplementedError('Unknown or unsupported channel tab: ' + tab)
|
||||||
|
|
||||||
|
return info
|
||||||
|
|
||||||
|
def extract_search_info(polymer_json):
|
||||||
|
response, err = extract_response(polymer_json)
|
||||||
|
if err:
|
||||||
|
return {'error': err}
|
||||||
|
info = {'error': None}
|
||||||
|
info['estimated_results'] = int(response['estimatedResults'])
|
||||||
|
info['estimated_pages'] = ceil(info['estimated_results']/20)
|
||||||
|
|
||||||
|
|
||||||
|
results, _ = extract_items(response)
|
||||||
|
|
||||||
|
|
||||||
|
info['items'] = []
|
||||||
|
info['corrections'] = {'type': None}
|
||||||
|
for renderer in results:
|
||||||
|
type = list(renderer.keys())[0]
|
||||||
|
if type == 'shelfRenderer':
|
||||||
|
continue
|
||||||
|
if type == 'didYouMeanRenderer':
|
||||||
|
renderer = renderer[type]
|
||||||
|
|
||||||
|
info['corrections'] = {
|
||||||
|
'type': 'did_you_mean',
|
||||||
|
'corrected_query': renderer['correctedQueryEndpoint']['searchEndpoint']['query'],
|
||||||
|
'corrected_query_text': renderer['correctedQuery']['runs'],
|
||||||
|
}
|
||||||
|
continue
|
||||||
|
if type == 'showingResultsForRenderer':
|
||||||
|
renderer = renderer[type]
|
||||||
|
|
||||||
|
info['corrections'] = {
|
||||||
|
'type': 'showing_results_for',
|
||||||
|
'corrected_query_text': renderer['correctedQuery']['runs'],
|
||||||
|
'original_query_text': renderer['originalQuery']['simpleText'],
|
||||||
|
}
|
||||||
|
continue
|
||||||
|
|
||||||
|
i_info = extract_item_info(renderer)
|
||||||
|
if i_info.get('type') != 'unsupported':
|
||||||
|
info['items'].append(i_info)
|
||||||
|
|
||||||
|
|
||||||
|
return info
|
||||||
|
|
||||||
|
def extract_playlist_metadata(polymer_json):
|
||||||
|
response, err = extract_response(polymer_json)
|
||||||
|
if err:
|
||||||
|
return {'error': err}
|
||||||
|
|
||||||
|
metadata = {'error': None}
|
||||||
|
header = deep_get(response, 'header', 'playlistHeaderRenderer', default={})
|
||||||
|
metadata['title'] = extract_str(header.get('title'))
|
||||||
|
|
||||||
|
metadata['first_video_id'] = deep_get(header, 'playEndpoint', 'watchEndpoint', 'videoId')
|
||||||
|
first_id = re.search(r'([a-z_\-]{11})', deep_get(header,
|
||||||
|
'thumbnail', 'thumbnails', 0, 'url', default=''))
|
||||||
|
if first_id:
|
||||||
|
conservative_update(metadata, 'first_video_id', first_id.group(1))
|
||||||
|
if metadata['first_video_id'] is None:
|
||||||
|
metadata['thumbnail'] = None
|
||||||
|
else:
|
||||||
|
metadata['thumbnail'] = 'https://i.ytimg.com/vi/' + metadata['first_video_id'] + '/mqdefault.jpg'
|
||||||
|
|
||||||
|
metadata['video_count'] = extract_int(header.get('numVideosText'))
|
||||||
|
metadata['description'] = extract_str(header.get('descriptionText'), default='')
|
||||||
|
metadata['author'] = extract_str(header.get('ownerText'))
|
||||||
|
metadata['author_id'] = multi_deep_get(header,
|
||||||
|
['ownerText', 'runs', 0, 'navigationEndpoint', 'browseEndpoint', 'browseId'],
|
||||||
|
['ownerEndpoint', 'browseEndpoint', 'browseId'])
|
||||||
|
if metadata['author_id']:
|
||||||
|
metadata['author_url'] = 'https://www.youtube.com/channel/' + metadata['author_id']
|
||||||
|
else:
|
||||||
|
metadata['author_url'] = None
|
||||||
|
metadata['view_count'] = extract_int(header.get('viewCountText'))
|
||||||
|
metadata['like_count'] = extract_int(header.get('likesCountWithoutLikeText'))
|
||||||
|
for stat in header.get('stats', ()):
|
||||||
|
text = extract_str(stat)
|
||||||
|
if 'videos' in text:
|
||||||
|
conservative_update(metadata, 'video_count', extract_int(text))
|
||||||
|
elif 'views' in text:
|
||||||
|
conservative_update(metadata, 'view_count', extract_int(text))
|
||||||
|
elif 'updated' in text:
|
||||||
|
metadata['time_published'] = extract_date(text)
|
||||||
|
|
||||||
|
microformat = deep_get(response, 'microformat', 'microformatDataRenderer',
|
||||||
|
default={})
|
||||||
|
conservative_update(
|
||||||
|
metadata, 'title', extract_str(microformat.get('title'))
|
||||||
|
)
|
||||||
|
conservative_update(
|
||||||
|
metadata, 'description', extract_str(microformat.get('description'))
|
||||||
|
)
|
||||||
|
conservative_update(
|
||||||
|
metadata, 'thumbnail', deep_get(microformat, 'thumbnail',
|
||||||
|
'thumbnails', -1, 'url')
|
||||||
|
)
|
||||||
|
|
||||||
|
return metadata
|
||||||
|
|
||||||
|
def extract_playlist_info(polymer_json):
|
||||||
|
response, err = extract_response(polymer_json)
|
||||||
|
if err:
|
||||||
|
return {'error': err}
|
||||||
|
info = {'error': None}
|
||||||
|
video_list, _ = extract_items(response)
|
||||||
|
|
||||||
|
info['items'] = [extract_item_info(renderer) for renderer in video_list]
|
||||||
|
|
||||||
|
info['metadata'] = extract_playlist_metadata(polymer_json)
|
||||||
|
|
||||||
|
return info
|
||||||
|
|
||||||
|
def _ctoken_metadata(ctoken):
|
||||||
|
result = dict()
|
||||||
|
params = proto.parse(proto.b64_to_bytes(ctoken))
|
||||||
|
result['video_id'] = proto.parse(params[2])[2].decode('ascii')
|
||||||
|
|
||||||
|
offset_information = proto.parse(params[6])
|
||||||
|
result['offset'] = offset_information.get(5, 0)
|
||||||
|
|
||||||
|
result['is_replies'] = False
|
||||||
|
if (3 in offset_information) and (2 in proto.parse(offset_information[3])):
|
||||||
|
result['is_replies'] = True
|
||||||
|
result['sort'] = None
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
result['sort'] = proto.parse(offset_information[4])[6]
|
||||||
|
except KeyError:
|
||||||
|
result['sort'] = 0
|
||||||
|
return result
|
||||||
|
|
||||||
|
def extract_comments_info(polymer_json, ctoken=None):
|
||||||
|
response, err = extract_response(polymer_json)
|
||||||
|
if err:
|
||||||
|
return {'error': err}
|
||||||
|
info = {'error': None}
|
||||||
|
|
||||||
|
if ctoken:
|
||||||
|
metadata = _ctoken_metadata(ctoken)
|
||||||
|
else:
|
||||||
|
metadata = {}
|
||||||
|
info['video_id'] = metadata.get('video_id')
|
||||||
|
info['offset'] = metadata.get('offset')
|
||||||
|
info['is_replies'] = metadata.get('is_replies')
|
||||||
|
info['sort'] = metadata.get('sort')
|
||||||
|
info['video_title'] = None
|
||||||
|
|
||||||
|
comments, ctoken = extract_items(response,
|
||||||
|
item_types={'commentThreadRenderer', 'commentRenderer'})
|
||||||
|
info['comments'] = []
|
||||||
|
info['ctoken'] = ctoken
|
||||||
|
for comment in comments:
|
||||||
|
comment_info = {}
|
||||||
|
|
||||||
|
if 'commentThreadRenderer' in comment: # top level comments
|
||||||
|
conservative_update(info, 'is_replies', False)
|
||||||
|
comment_thread = comment['commentThreadRenderer']
|
||||||
|
info['video_title'] = extract_str(comment_thread.get('commentTargetTitle'))
|
||||||
|
if 'replies' not in comment_thread:
|
||||||
|
comment_info['reply_count'] = 0
|
||||||
|
comment_info['reply_ctoken'] = None
|
||||||
|
else:
|
||||||
|
comment_info['reply_count'] = extract_int(deep_get(comment_thread,
|
||||||
|
'replies', 'commentRepliesRenderer', 'moreText'
|
||||||
|
), default=1) # With 1 reply, the text reads "View reply"
|
||||||
|
comment_info['reply_ctoken'] = multi_deep_get(
|
||||||
|
comment_thread,
|
||||||
|
['replies', 'commentRepliesRenderer', 'contents', 0,
|
||||||
|
'continuationItemRenderer', 'button', 'buttonRenderer',
|
||||||
|
'command', 'continuationCommand', 'token'],
|
||||||
|
['replies', 'commentRepliesRenderer', 'continuations', 0,
|
||||||
|
'nextContinuationData', 'continuation']
|
||||||
|
)
|
||||||
|
comment_renderer = deep_get(comment_thread, 'comment', 'commentRenderer', default={})
|
||||||
|
elif 'commentRenderer' in comment: # replies
|
||||||
|
comment_info['reply_count'] = 0 # replyCount, below, not present for replies even if the reply has further replies to it
|
||||||
|
comment_info['reply_ctoken'] = None
|
||||||
|
conservative_update(info, 'is_replies', True)
|
||||||
|
comment_renderer = comment['commentRenderer']
|
||||||
|
else:
|
||||||
|
comment_renderer = {}
|
||||||
|
|
||||||
|
# These 3 are sometimes absent, likely because the channel was deleted
|
||||||
|
comment_info['author'] = extract_str(comment_renderer.get('authorText'))
|
||||||
|
comment_info['author_url'] = normalize_url(deep_get(comment_renderer,
|
||||||
|
'authorEndpoint', 'commandMetadata', 'webCommandMetadata', 'url'))
|
||||||
|
comment_info['author_id'] = deep_get(comment_renderer,
|
||||||
|
'authorEndpoint', 'browseEndpoint', 'browseId')
|
||||||
|
|
||||||
|
comment_info['author_avatar'] = normalize_url(deep_get(
|
||||||
|
comment_renderer, 'authorThumbnail', 'thumbnails', 0, 'url'))
|
||||||
|
comment_info['id'] = comment_renderer.get('commentId')
|
||||||
|
comment_info['text'] = extract_formatted_text(comment_renderer.get('contentText'))
|
||||||
|
comment_info['time_published'] = extract_str(comment_renderer.get('publishedTimeText'))
|
||||||
|
comment_info['like_count'] = comment_renderer.get('likeCount')
|
||||||
|
comment_info['approx_like_count'] = extract_approx_int(
|
||||||
|
comment_renderer.get('voteCount'))
|
||||||
|
liberal_update(comment_info, 'reply_count', comment_renderer.get('replyCount'))
|
||||||
|
|
||||||
|
info['comments'].append(comment_info)
|
||||||
|
|
||||||
|
return info
|
||||||
948
youtube/yt_data_extract/watch_extraction.py
Normal file
948
youtube/yt_data_extract/watch_extraction.py
Normal file
@@ -0,0 +1,948 @@
|
|||||||
|
from .common import (get, multi_get, deep_get, multi_deep_get,
|
||||||
|
liberal_update, conservative_update, remove_redirect, normalize_url,
|
||||||
|
extract_str, extract_formatted_text, extract_int, extract_approx_int,
|
||||||
|
extract_date, check_missing_keys, extract_item_info, extract_items,
|
||||||
|
extract_response, concat_or_none, liberal_dict_update,
|
||||||
|
conservative_dict_update)
|
||||||
|
|
||||||
|
import json
|
||||||
|
import urllib.parse
|
||||||
|
import traceback
|
||||||
|
import re
|
||||||
|
|
||||||
|
# from https://github.com/ytdl-org/youtube-dl/blob/master/youtube_dl/extractor/youtube.py
|
||||||
|
_formats = {
|
||||||
|
'5': {'ext': 'flv', 'width': 400, 'height': 240, 'acodec': 'mp3', 'audio_bitrate': 64, 'vcodec': 'h263'},
|
||||||
|
'6': {'ext': 'flv', 'width': 450, 'height': 270, 'acodec': 'mp3', 'audio_bitrate': 64, 'vcodec': 'h263'},
|
||||||
|
'13': {'ext': '3gp', 'acodec': 'aac', 'vcodec': 'mp4v'},
|
||||||
|
'17': {'ext': '3gp', 'width': 176, 'height': 144, 'acodec': 'aac', 'audio_bitrate': 24, 'vcodec': 'mp4v'},
|
||||||
|
'18': {'ext': 'mp4', 'width': 640, 'height': 360, 'acodec': 'aac', 'audio_bitrate': 96, 'vcodec': 'h264'},
|
||||||
|
'22': {'ext': 'mp4', 'width': 1280, 'height': 720, 'acodec': 'aac', 'audio_bitrate': 192, 'vcodec': 'h264'},
|
||||||
|
'34': {'ext': 'flv', 'width': 640, 'height': 360, 'acodec': 'aac', 'audio_bitrate': 128, 'vcodec': 'h264'},
|
||||||
|
'35': {'ext': 'flv', 'width': 854, 'height': 480, 'acodec': 'aac', 'audio_bitrate': 128, 'vcodec': 'h264'},
|
||||||
|
# itag 36 videos are either 320x180 (BaW_jenozKc) or 320x240 (__2ABJjxzNo), audio_bitrate varies as well
|
||||||
|
'36': {'ext': '3gp', 'width': 320, 'acodec': 'aac', 'vcodec': 'mp4v'},
|
||||||
|
'37': {'ext': 'mp4', 'width': 1920, 'height': 1080, 'acodec': 'aac', 'audio_bitrate': 192, 'vcodec': 'h264'},
|
||||||
|
'38': {'ext': 'mp4', 'width': 4096, 'height': 3072, 'acodec': 'aac', 'audio_bitrate': 192, 'vcodec': 'h264'},
|
||||||
|
'43': {'ext': 'webm', 'width': 640, 'height': 360, 'acodec': 'vorbis', 'audio_bitrate': 128, 'vcodec': 'vp8'},
|
||||||
|
'44': {'ext': 'webm', 'width': 854, 'height': 480, 'acodec': 'vorbis', 'audio_bitrate': 128, 'vcodec': 'vp8'},
|
||||||
|
'45': {'ext': 'webm', 'width': 1280, 'height': 720, 'acodec': 'vorbis', 'audio_bitrate': 192, 'vcodec': 'vp8'},
|
||||||
|
'46': {'ext': 'webm', 'width': 1920, 'height': 1080, 'acodec': 'vorbis', 'audio_bitrate': 192, 'vcodec': 'vp8'},
|
||||||
|
'59': {'ext': 'mp4', 'width': 854, 'height': 480, 'acodec': 'aac', 'audio_bitrate': 128, 'vcodec': 'h264'},
|
||||||
|
'78': {'ext': 'mp4', 'width': 854, 'height': 480, 'acodec': 'aac', 'audio_bitrate': 128, 'vcodec': 'h264'},
|
||||||
|
|
||||||
|
|
||||||
|
# 3D videos
|
||||||
|
'82': {'ext': 'mp4', 'height': 360, 'format_note': '3D', 'acodec': 'aac', 'audio_bitrate': 128, 'vcodec': 'h264'},
|
||||||
|
'83': {'ext': 'mp4', 'height': 480, 'format_note': '3D', 'acodec': 'aac', 'audio_bitrate': 128, 'vcodec': 'h264'},
|
||||||
|
'84': {'ext': 'mp4', 'height': 720, 'format_note': '3D', 'acodec': 'aac', 'audio_bitrate': 192, 'vcodec': 'h264'},
|
||||||
|
'85': {'ext': 'mp4', 'height': 1080, 'format_note': '3D', 'acodec': 'aac', 'audio_bitrate': 192, 'vcodec': 'h264'},
|
||||||
|
'100': {'ext': 'webm', 'height': 360, 'format_note': '3D', 'acodec': 'vorbis', 'audio_bitrate': 128, 'vcodec': 'vp8'},
|
||||||
|
'101': {'ext': 'webm', 'height': 480, 'format_note': '3D', 'acodec': 'vorbis', 'audio_bitrate': 192, 'vcodec': 'vp8'},
|
||||||
|
'102': {'ext': 'webm', 'height': 720, 'format_note': '3D', 'acodec': 'vorbis', 'audio_bitrate': 192, 'vcodec': 'vp8'},
|
||||||
|
|
||||||
|
# Apple HTTP Live Streaming
|
||||||
|
'91': {'ext': 'mp4', 'height': 144, 'format_note': 'HLS', 'acodec': 'aac', 'audio_bitrate': 48, 'vcodec': 'h264'},
|
||||||
|
'92': {'ext': 'mp4', 'height': 240, 'format_note': 'HLS', 'acodec': 'aac', 'audio_bitrate': 48, 'vcodec': 'h264'},
|
||||||
|
'93': {'ext': 'mp4', 'height': 360, 'format_note': 'HLS', 'acodec': 'aac', 'audio_bitrate': 128, 'vcodec': 'h264'},
|
||||||
|
'94': {'ext': 'mp4', 'height': 480, 'format_note': 'HLS', 'acodec': 'aac', 'audio_bitrate': 128, 'vcodec': 'h264'},
|
||||||
|
'95': {'ext': 'mp4', 'height': 720, 'format_note': 'HLS', 'acodec': 'aac', 'audio_bitrate': 256, 'vcodec': 'h264'},
|
||||||
|
'96': {'ext': 'mp4', 'height': 1080, 'format_note': 'HLS', 'acodec': 'aac', 'audio_bitrate': 256, 'vcodec': 'h264'},
|
||||||
|
'132': {'ext': 'mp4', 'height': 240, 'format_note': 'HLS', 'acodec': 'aac', 'audio_bitrate': 48, 'vcodec': 'h264'},
|
||||||
|
'151': {'ext': 'mp4', 'height': 72, 'format_note': 'HLS', 'acodec': 'aac', 'audio_bitrate': 24, 'vcodec': 'h264'},
|
||||||
|
|
||||||
|
# DASH mp4 video
|
||||||
|
'133': {'ext': 'mp4', 'height': 240, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
'134': {'ext': 'mp4', 'height': 360, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
'135': {'ext': 'mp4', 'height': 480, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
'136': {'ext': 'mp4', 'height': 720, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
'137': {'ext': 'mp4', 'height': 1080, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
'138': {'ext': 'mp4', 'format_note': 'DASH video', 'vcodec': 'h264'}, # Height can vary (https://github.com/ytdl-org/youtube-dl/issues/4559)
|
||||||
|
'160': {'ext': 'mp4', 'height': 144, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
'212': {'ext': 'mp4', 'height': 480, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
'264': {'ext': 'mp4', 'height': 1440, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
'298': {'ext': 'mp4', 'height': 720, 'format_note': 'DASH video', 'vcodec': 'h264', 'fps': 60},
|
||||||
|
'299': {'ext': 'mp4', 'height': 1080, 'format_note': 'DASH video', 'vcodec': 'h264', 'fps': 60},
|
||||||
|
'266': {'ext': 'mp4', 'height': 2160, 'format_note': 'DASH video', 'vcodec': 'h264'},
|
||||||
|
|
||||||
|
# Dash mp4 audio
|
||||||
|
'139': {'ext': 'm4a', 'format_note': 'DASH audio', 'acodec': 'aac', 'audio_bitrate': 48, 'container': 'm4a_dash'},
|
||||||
|
'140': {'ext': 'm4a', 'format_note': 'DASH audio', 'acodec': 'aac', 'audio_bitrate': 128, 'container': 'm4a_dash'},
|
||||||
|
'141': {'ext': 'm4a', 'format_note': 'DASH audio', 'acodec': 'aac', 'audio_bitrate': 256, 'container': 'm4a_dash'},
|
||||||
|
'256': {'ext': 'm4a', 'format_note': 'DASH audio', 'acodec': 'aac', 'container': 'm4a_dash'},
|
||||||
|
'258': {'ext': 'm4a', 'format_note': 'DASH audio', 'acodec': 'aac', 'container': 'm4a_dash'},
|
||||||
|
'325': {'ext': 'm4a', 'format_note': 'DASH audio', 'acodec': 'dtse', 'container': 'm4a_dash'},
|
||||||
|
'328': {'ext': 'm4a', 'format_note': 'DASH audio', 'acodec': 'ec-3', 'container': 'm4a_dash'},
|
||||||
|
|
||||||
|
# Dash webm
|
||||||
|
'167': {'ext': 'webm', 'height': 360, 'width': 640, 'format_note': 'DASH video', 'container': 'webm', 'vcodec': 'vp8'},
|
||||||
|
'168': {'ext': 'webm', 'height': 480, 'width': 854, 'format_note': 'DASH video', 'container': 'webm', 'vcodec': 'vp8'},
|
||||||
|
'169': {'ext': 'webm', 'height': 720, 'width': 1280, 'format_note': 'DASH video', 'container': 'webm', 'vcodec': 'vp8'},
|
||||||
|
'170': {'ext': 'webm', 'height': 1080, 'width': 1920, 'format_note': 'DASH video', 'container': 'webm', 'vcodec': 'vp8'},
|
||||||
|
'218': {'ext': 'webm', 'height': 480, 'width': 854, 'format_note': 'DASH video', 'container': 'webm', 'vcodec': 'vp8'},
|
||||||
|
'219': {'ext': 'webm', 'height': 480, 'width': 854, 'format_note': 'DASH video', 'container': 'webm', 'vcodec': 'vp8'},
|
||||||
|
'278': {'ext': 'webm', 'height': 144, 'format_note': 'DASH video', 'container': 'webm', 'vcodec': 'vp9'},
|
||||||
|
'242': {'ext': 'webm', 'height': 240, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'243': {'ext': 'webm', 'height': 360, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'244': {'ext': 'webm', 'height': 480, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'245': {'ext': 'webm', 'height': 480, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'246': {'ext': 'webm', 'height': 480, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'247': {'ext': 'webm', 'height': 720, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'248': {'ext': 'webm', 'height': 1080, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'271': {'ext': 'webm', 'height': 1440, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
# itag 272 videos are either 3840x2160 (e.g. RtoitU2A-3E) or 7680x4320 (sLprVF6d7Ug)
|
||||||
|
'272': {'ext': 'webm', 'height': 2160, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'302': {'ext': 'webm', 'height': 720, 'format_note': 'DASH video', 'vcodec': 'vp9', 'fps': 60},
|
||||||
|
'303': {'ext': 'webm', 'height': 1080, 'format_note': 'DASH video', 'vcodec': 'vp9', 'fps': 60},
|
||||||
|
'308': {'ext': 'webm', 'height': 1440, 'format_note': 'DASH video', 'vcodec': 'vp9', 'fps': 60},
|
||||||
|
'313': {'ext': 'webm', 'height': 2160, 'format_note': 'DASH video', 'vcodec': 'vp9'},
|
||||||
|
'315': {'ext': 'webm', 'height': 2160, 'format_note': 'DASH video', 'vcodec': 'vp9', 'fps': 60},
|
||||||
|
|
||||||
|
# Dash webm audio
|
||||||
|
'171': {'ext': 'webm', 'acodec': 'vorbis', 'format_note': 'DASH audio', 'audio_bitrate': 128},
|
||||||
|
'172': {'ext': 'webm', 'acodec': 'vorbis', 'format_note': 'DASH audio', 'audio_bitrate': 256},
|
||||||
|
|
||||||
|
# Dash webm audio with opus inside
|
||||||
|
'249': {'ext': 'webm', 'format_note': 'DASH audio', 'acodec': 'opus', 'audio_bitrate': 50},
|
||||||
|
'250': {'ext': 'webm', 'format_note': 'DASH audio', 'acodec': 'opus', 'audio_bitrate': 70},
|
||||||
|
'251': {'ext': 'webm', 'format_note': 'DASH audio', 'acodec': 'opus', 'audio_bitrate': 160},
|
||||||
|
|
||||||
|
# RTMP (unnamed)
|
||||||
|
'_rtmp': {'protocol': 'rtmp'},
|
||||||
|
|
||||||
|
# av01 video only formats sometimes served with "unknown" codecs
|
||||||
|
'394': {'vcodec': 'av01.0.05M.08'},
|
||||||
|
'395': {'vcodec': 'av01.0.05M.08'},
|
||||||
|
'396': {'vcodec': 'av01.0.05M.08'},
|
||||||
|
'397': {'vcodec': 'av01.0.05M.08'},
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def _extract_from_video_information_renderer(renderer_content):
|
||||||
|
subtitle = extract_str(renderer_content.get('expandedSubtitle'),
|
||||||
|
default='')
|
||||||
|
info = {
|
||||||
|
'title': extract_str(renderer_content.get('title')),
|
||||||
|
'view_count': extract_int(subtitle),
|
||||||
|
'unlisted': False,
|
||||||
|
'live': 'watching' in subtitle,
|
||||||
|
}
|
||||||
|
for badge in renderer_content.get('badges', []):
|
||||||
|
if deep_get(badge, 'metadataBadgeRenderer', 'label') == 'Unlisted':
|
||||||
|
info['unlisted'] = True
|
||||||
|
return info
|
||||||
|
|
||||||
|
def _extract_likes_dislikes(renderer_content):
|
||||||
|
def extract_button_count(toggle_button_renderer):
|
||||||
|
# all the digits can be found in the accessibility data
|
||||||
|
count = extract_int(multi_deep_get(
|
||||||
|
toggle_button_renderer,
|
||||||
|
['defaultText', 'accessibility', 'accessibilityData', 'label'],
|
||||||
|
['accessibility', 'label'],
|
||||||
|
['accessibilityData', 'accessibilityData', 'label'],
|
||||||
|
['accessibilityText'],
|
||||||
|
))
|
||||||
|
|
||||||
|
# this count doesn't have all the digits, it's like 53K for instance
|
||||||
|
dumb_count = extract_int(extract_str(multi_get(
|
||||||
|
toggle_button_renderer, ['defaultText', 'title'])))
|
||||||
|
|
||||||
|
# The accessibility text will be "No likes" or "No dislikes" or
|
||||||
|
# something like that, but dumb count will be 0
|
||||||
|
if dumb_count == 0:
|
||||||
|
count = 0
|
||||||
|
return count
|
||||||
|
|
||||||
|
info = {
|
||||||
|
'like_count': None,
|
||||||
|
'dislike_count': None,
|
||||||
|
}
|
||||||
|
for button in renderer_content.get('buttons', ()):
|
||||||
|
if 'slimMetadataToggleButtonRenderer' in button:
|
||||||
|
button_renderer = button['slimMetadataToggleButtonRenderer']
|
||||||
|
count = extract_button_count(deep_get(button_renderer,
|
||||||
|
'button',
|
||||||
|
'toggleButtonRenderer'))
|
||||||
|
if 'isLike' in button_renderer:
|
||||||
|
info['like_count'] = count
|
||||||
|
elif 'isDislike' in button_renderer:
|
||||||
|
info['dislike_count'] = count
|
||||||
|
elif 'slimMetadataButtonRenderer' in button:
|
||||||
|
button_renderer = button['slimMetadataButtonRenderer']
|
||||||
|
liberal_update(info, 'like_count', extract_button_count(
|
||||||
|
multi_deep_get(button_renderer,
|
||||||
|
['button', 'segmentedLikeDislikeButtonRenderer',
|
||||||
|
'likeButton', 'toggleButtonRenderer'],
|
||||||
|
['button', 'segmentedLikeDislikeButtonViewModel',
|
||||||
|
'likeButtonViewModel', 'likeButtonViewModel',
|
||||||
|
'toggleButtonViewModel', 'toggleButtonViewModel',
|
||||||
|
'defaultButtonViewModel', 'buttonViewModel']
|
||||||
|
)
|
||||||
|
))
|
||||||
|
'''liberal_update(info, 'dislike_count', extract_button_count(
|
||||||
|
deep_get(
|
||||||
|
button_renderer, 'button',
|
||||||
|
'segmentedLikeDislikeButtonRenderer',
|
||||||
|
'dislikeButton', 'toggleButtonRenderer'
|
||||||
|
)
|
||||||
|
))'''
|
||||||
|
return info
|
||||||
|
|
||||||
|
def _extract_from_owner_renderer(renderer_content):
|
||||||
|
return {
|
||||||
|
'author': extract_str(renderer_content.get('title')),
|
||||||
|
'author_id': deep_get(
|
||||||
|
renderer_content,
|
||||||
|
'navigationEndpoint', 'browseEndpoint', 'browseId'),
|
||||||
|
}
|
||||||
|
|
||||||
|
def _extract_from_video_header_renderer(renderer_content):
|
||||||
|
return {
|
||||||
|
'title': extract_str(renderer_content.get('title')),
|
||||||
|
'time_published': extract_date(extract_str(
|
||||||
|
renderer_content.get('publishDate'))),
|
||||||
|
}
|
||||||
|
|
||||||
|
def _extract_from_description_renderer(renderer_content):
|
||||||
|
return {
|
||||||
|
'description': extract_str(
|
||||||
|
renderer_content.get('descriptionBodyText'), recover_urls=True),
|
||||||
|
}
|
||||||
|
|
||||||
|
def _extract_metadata_row_info(renderer_content):
|
||||||
|
# extract category and music list
|
||||||
|
info = {
|
||||||
|
'category': None,
|
||||||
|
'music_list': [],
|
||||||
|
}
|
||||||
|
|
||||||
|
current_song = {}
|
||||||
|
for row in deep_get(renderer_content, 'rows', default=[]):
|
||||||
|
row_title = extract_str(deep_get(row, 'metadataRowRenderer', 'title'), default='')
|
||||||
|
row_content = extract_str(deep_get(row, 'metadataRowRenderer', 'contents', 0))
|
||||||
|
if row_title == 'Category':
|
||||||
|
info['category'] = row_content
|
||||||
|
elif row_title in ('Song', 'Music'):
|
||||||
|
if current_song:
|
||||||
|
info['music_list'].append(current_song)
|
||||||
|
current_song = {'title': row_content}
|
||||||
|
elif row_title == 'Artist':
|
||||||
|
current_song['artist'] = row_content
|
||||||
|
elif row_title == 'Album':
|
||||||
|
current_song['album'] = row_content
|
||||||
|
elif row_title == 'Writers':
|
||||||
|
current_song['writers'] = row_content
|
||||||
|
elif row_title.startswith('Licensed'):
|
||||||
|
current_song['licensor'] = row_content
|
||||||
|
if current_song:
|
||||||
|
info['music_list'].append(current_song)
|
||||||
|
|
||||||
|
return info
|
||||||
|
|
||||||
|
def _extract_from_music_renderer(renderer_content):
|
||||||
|
# latest format for the music list
|
||||||
|
info = {
|
||||||
|
'music_list': [],
|
||||||
|
}
|
||||||
|
|
||||||
|
for carousel in renderer_content.get('carouselLockups', []):
|
||||||
|
song = {}
|
||||||
|
carousel = carousel.get('carouselLockupRenderer', {})
|
||||||
|
video_renderer = carousel.get('videoLockup', {})
|
||||||
|
video_renderer_info = extract_item_info(video_renderer)
|
||||||
|
video_id = video_renderer_info.get('id')
|
||||||
|
song['url'] = concat_or_none('https://www.youtube.com/watch?v=',
|
||||||
|
video_id)
|
||||||
|
song['title'] = video_renderer_info.get('title')
|
||||||
|
for row in carousel.get('infoRows', []):
|
||||||
|
row = row.get('infoRowRenderer', {})
|
||||||
|
title = extract_str(row.get('title'))
|
||||||
|
data = extract_str(row.get('defaultMetadata'))
|
||||||
|
if title == 'SONG':
|
||||||
|
song['title'] = data
|
||||||
|
elif title == 'ARTIST':
|
||||||
|
song['artist'] = data
|
||||||
|
elif title == 'ALBUM':
|
||||||
|
song['album'] = data
|
||||||
|
elif title == 'WRITERS':
|
||||||
|
song['writers'] = data
|
||||||
|
info['music_list'].append(song)
|
||||||
|
return info
|
||||||
|
|
||||||
|
def _extract_from_video_metadata(renderer_content):
|
||||||
|
info = _extract_from_video_information_renderer(renderer_content)
|
||||||
|
liberal_dict_update(info, _extract_likes_dislikes(renderer_content))
|
||||||
|
liberal_dict_update(info, _extract_from_owner_renderer(renderer_content))
|
||||||
|
liberal_dict_update(info, _extract_metadata_row_info(deep_get(
|
||||||
|
renderer_content, 'metadataRowContainer',
|
||||||
|
'metadataRowContainerRenderer', default={}
|
||||||
|
)))
|
||||||
|
liberal_update(info, 'title', extract_str(renderer_content.get('title')))
|
||||||
|
liberal_update(
|
||||||
|
info, 'description',
|
||||||
|
extract_str(renderer_content.get('description'), recover_urls=True)
|
||||||
|
)
|
||||||
|
liberal_update(info, 'time_published',
|
||||||
|
extract_date(renderer_content.get('dateText')))
|
||||||
|
return info
|
||||||
|
|
||||||
|
visible_extraction_dispatch = {
|
||||||
|
# Either these ones spread around in various places
|
||||||
|
'slimVideoInformationRenderer': _extract_from_video_information_renderer,
|
||||||
|
'slimVideoActionBarRenderer': _extract_likes_dislikes,
|
||||||
|
'slimOwnerRenderer': _extract_from_owner_renderer,
|
||||||
|
'videoDescriptionHeaderRenderer': _extract_from_video_header_renderer,
|
||||||
|
'videoDescriptionMusicSectionRenderer': _extract_from_music_renderer,
|
||||||
|
'expandableVideoDescriptionRenderer': _extract_from_description_renderer,
|
||||||
|
'metadataRowContainerRenderer': _extract_metadata_row_info,
|
||||||
|
# OR just this one, which contains SOME of the above inside it
|
||||||
|
'slimVideoMetadataRenderer': _extract_from_video_metadata,
|
||||||
|
}
|
||||||
|
|
||||||
|
def _extract_watch_info_mobile(top_level):
|
||||||
|
'''Scrapes information from the visible page'''
|
||||||
|
info = {}
|
||||||
|
response = top_level.get('response', {})
|
||||||
|
|
||||||
|
# this renderer has the stuff visible on the page
|
||||||
|
# check for playlist
|
||||||
|
items, _ = extract_items(response,
|
||||||
|
item_types={'singleColumnWatchNextResults'})
|
||||||
|
if items:
|
||||||
|
watch_next_results = items[0]['singleColumnWatchNextResults']
|
||||||
|
playlist = deep_get(watch_next_results, 'playlist', 'playlist')
|
||||||
|
if playlist is None:
|
||||||
|
info['playlist'] = None
|
||||||
|
else:
|
||||||
|
info['playlist'] = {}
|
||||||
|
info['playlist']['title'] = playlist.get('title')
|
||||||
|
info['playlist']['author'] = extract_str(multi_get(playlist,
|
||||||
|
'ownerName', 'longBylineText', 'shortBylineText', 'ownerText'))
|
||||||
|
author_id = deep_get(playlist, 'longBylineText', 'runs', 0,
|
||||||
|
'navigationEndpoint', 'browseEndpoint', 'browseId')
|
||||||
|
info['playlist']['author_id'] = author_id
|
||||||
|
info['playlist']['author_url'] = concat_or_none(
|
||||||
|
'https://www.youtube.com/channel/', author_id)
|
||||||
|
info['playlist']['id'] = playlist.get('playlistId')
|
||||||
|
info['playlist']['url'] = concat_or_none(
|
||||||
|
'https://www.youtube.com/playlist?list=',
|
||||||
|
info['playlist']['id'])
|
||||||
|
info['playlist']['video_count'] = playlist.get('totalVideos')
|
||||||
|
info['playlist']['current_index'] = playlist.get('currentIndex')
|
||||||
|
info['playlist']['items'] = [
|
||||||
|
extract_item_info(i) for i in playlist.get('contents', ())]
|
||||||
|
else:
|
||||||
|
info['playlist'] = None
|
||||||
|
|
||||||
|
# use dispatch table to get information scattered in various renderers
|
||||||
|
items, _ = extract_items(
|
||||||
|
response,
|
||||||
|
item_types=visible_extraction_dispatch.keys(),
|
||||||
|
search_engagement_panels=True
|
||||||
|
)
|
||||||
|
found = set()
|
||||||
|
for renderer in items:
|
||||||
|
name, renderer_content = list(renderer.items())[0]
|
||||||
|
found.add(name)
|
||||||
|
liberal_dict_update(
|
||||||
|
info,
|
||||||
|
visible_extraction_dispatch[name](renderer_content)
|
||||||
|
)
|
||||||
|
# Call the function on blank dict for any that weren't found
|
||||||
|
# so that the empty keys get added
|
||||||
|
for name in visible_extraction_dispatch.keys() - found:
|
||||||
|
liberal_dict_update(info, visible_extraction_dispatch[name]({}))
|
||||||
|
|
||||||
|
# comment section info
|
||||||
|
items, _ = extract_items(response, item_types={
|
||||||
|
'commentSectionRenderer', 'commentsEntryPointHeaderRenderer'})
|
||||||
|
if items:
|
||||||
|
header_type = list(items[0])[0]
|
||||||
|
comment_info = items[0][header_type]
|
||||||
|
# This seems to be some kind of A/B test being done on mobile, where
|
||||||
|
# this is present instead of the normal commentSectionRenderer. It can
|
||||||
|
# be seen here:
|
||||||
|
# https://www.androidpolice.com/2019/10/31/google-youtube-app-comment-section-below-videos/
|
||||||
|
# https://www.youtube.com/watch?v=bR5Q-wD-6qo
|
||||||
|
if header_type == 'commentsEntryPointHeaderRenderer':
|
||||||
|
comment_count_text = extract_str(multi_get(
|
||||||
|
comment_info, 'commentCount', 'headerText'))
|
||||||
|
else:
|
||||||
|
comment_count_text = extract_str(deep_get(comment_info,
|
||||||
|
'header', 'commentSectionHeaderRenderer', 'countText'))
|
||||||
|
if comment_count_text == 'Comments': # just this with no number, means 0 comments
|
||||||
|
info['comment_count'] = '0'
|
||||||
|
else:
|
||||||
|
info['comment_count'] = extract_approx_int(comment_count_text)
|
||||||
|
info['comments_disabled'] = False
|
||||||
|
else: # no comment section present means comments are disabled
|
||||||
|
info['comment_count'] = '0'
|
||||||
|
info['comments_disabled'] = True
|
||||||
|
|
||||||
|
# check for limited state
|
||||||
|
items, _ = extract_items(response, item_types={'limitedStateMessageRenderer'})
|
||||||
|
if items:
|
||||||
|
info['limited_state'] = True
|
||||||
|
else:
|
||||||
|
info['limited_state'] = False
|
||||||
|
|
||||||
|
# related videos
|
||||||
|
related, _ = extract_items(response)
|
||||||
|
info['related_videos'] = [extract_item_info(renderer) for renderer in related]
|
||||||
|
|
||||||
|
return info
|
||||||
|
|
||||||
|
def _extract_watch_info_desktop(top_level):
|
||||||
|
info = {
|
||||||
|
'comment_count': None,
|
||||||
|
'comments_disabled': None,
|
||||||
|
'limited_state': None,
|
||||||
|
'playlist': None,
|
||||||
|
}
|
||||||
|
|
||||||
|
video_info = {}
|
||||||
|
for renderer in deep_get(top_level, 'response', 'contents', 'twoColumnWatchNextResults', 'results', 'results', 'contents', default=()):
|
||||||
|
if renderer and list(renderer.keys())[0] in ('videoPrimaryInfoRenderer', 'videoSecondaryInfoRenderer'):
|
||||||
|
video_info.update(list(renderer.values())[0])
|
||||||
|
|
||||||
|
info.update(_extract_metadata_row_info(video_info))
|
||||||
|
info['description'] = extract_str(video_info.get('description', None), recover_urls=True)
|
||||||
|
info['time_published'] = extract_date(extract_str(video_info.get('dateText', None)))
|
||||||
|
|
||||||
|
likes_dislikes = deep_get(video_info, 'sentimentBar', 'sentimentBarRenderer', 'tooltip', default='').split('/')
|
||||||
|
if len(likes_dislikes) == 2:
|
||||||
|
info['like_count'] = extract_int(likes_dislikes[0])
|
||||||
|
info['dislike_count'] = extract_int(likes_dislikes[1])
|
||||||
|
else:
|
||||||
|
info['like_count'] = None
|
||||||
|
info['dislike_count'] = None
|
||||||
|
|
||||||
|
info['title'] = extract_str(video_info.get('title', None))
|
||||||
|
info['author'] = extract_str(deep_get(video_info, 'owner', 'videoOwnerRenderer', 'title'))
|
||||||
|
info['author_id'] = deep_get(video_info, 'owner', 'videoOwnerRenderer', 'navigationEndpoint', 'browseEndpoint', 'browseId')
|
||||||
|
info['view_count'] = extract_int(extract_str(deep_get(video_info, 'viewCount', 'videoViewCountRenderer', 'viewCount')))
|
||||||
|
|
||||||
|
related = deep_get(top_level, 'response', 'contents', 'twoColumnWatchNextResults', 'secondaryResults', 'secondaryResults', 'results', default=[])
|
||||||
|
info['related_videos'] = [extract_item_info(renderer) for renderer in related]
|
||||||
|
|
||||||
|
return info
|
||||||
|
|
||||||
|
def update_format_with_codec_info(fmt, codec):
|
||||||
|
if any(codec.startswith(c) for c in ('av', 'vp', 'h263', 'h264', 'mp4v')):
|
||||||
|
if codec == 'vp8.0':
|
||||||
|
codec = 'vp8'
|
||||||
|
conservative_update(fmt, 'vcodec', codec)
|
||||||
|
elif (codec.startswith('mp4a')
|
||||||
|
or codec in ('opus', 'mp3', 'aac', 'dtse', 'ec-3', 'vorbis',
|
||||||
|
'ac-3')):
|
||||||
|
conservative_update(fmt, 'acodec', codec)
|
||||||
|
else:
|
||||||
|
print('Warning: unrecognized codec: ' + codec)
|
||||||
|
|
||||||
|
fmt_type_re = re.compile(
|
||||||
|
r'(text|audio|video)/([\w0-9]+); codecs="([^"]+)"')
|
||||||
|
def update_format_with_type_info(fmt, yt_fmt):
|
||||||
|
# 'type' for invidious api format
|
||||||
|
mime_type = multi_get(yt_fmt, 'mimeType', 'type')
|
||||||
|
if mime_type is None:
|
||||||
|
return
|
||||||
|
match = re.fullmatch(fmt_type_re, mime_type)
|
||||||
|
if match is None:
|
||||||
|
print('Warning: Could not read mimetype', mime_type)
|
||||||
|
return
|
||||||
|
type, fmt['ext'], codecs = match.groups()
|
||||||
|
codecs = codecs.split(', ')
|
||||||
|
for codec in codecs:
|
||||||
|
update_format_with_codec_info(fmt, codec)
|
||||||
|
if type == 'audio':
|
||||||
|
assert len(codecs) == 1
|
||||||
|
|
||||||
|
def _extract_formats(info, player_response):
|
||||||
|
streaming_data = player_response.get('streamingData', {})
|
||||||
|
yt_formats = streaming_data.get('formats', []) + streaming_data.get('adaptiveFormats', [])
|
||||||
|
|
||||||
|
info['formats'] = []
|
||||||
|
# because we may retry the extract_formats with a different player_response
|
||||||
|
# so keep what we have
|
||||||
|
conservative_update(info, 'hls_manifest_url',
|
||||||
|
streaming_data.get('hlsManifestUrl'))
|
||||||
|
conservative_update(info, 'dash_manifest_url',
|
||||||
|
streaming_data.get('dash_manifest_url'))
|
||||||
|
|
||||||
|
for yt_fmt in yt_formats:
|
||||||
|
itag = yt_fmt.get('itag')
|
||||||
|
|
||||||
|
# Translated audio track
|
||||||
|
# Example: https://www.youtube.com/watch?v=gF9kkB0UWYQ
|
||||||
|
# Only get the original language for now so a foreign
|
||||||
|
# translation will not be picked just because it comes first
|
||||||
|
if deep_get(yt_fmt, 'audioTrack', 'audioIsDefault') is False:
|
||||||
|
continue
|
||||||
|
|
||||||
|
fmt = {}
|
||||||
|
fmt['itag'] = itag
|
||||||
|
fmt['ext'] = None
|
||||||
|
fmt['audio_bitrate'] = None
|
||||||
|
fmt['bitrate'] = yt_fmt.get('bitrate')
|
||||||
|
fmt['acodec'] = None
|
||||||
|
fmt['vcodec'] = None
|
||||||
|
fmt['width'] = yt_fmt.get('width')
|
||||||
|
fmt['height'] = yt_fmt.get('height')
|
||||||
|
fmt['file_size'] = extract_int(yt_fmt.get('contentLength'))
|
||||||
|
fmt['audio_sample_rate'] = extract_int(yt_fmt.get('audioSampleRate'))
|
||||||
|
fmt['duration_ms'] = yt_fmt.get('approxDurationMs')
|
||||||
|
fmt['fps'] = yt_fmt.get('fps')
|
||||||
|
fmt['init_range'] = yt_fmt.get('initRange')
|
||||||
|
fmt['index_range'] = yt_fmt.get('indexRange')
|
||||||
|
for key in ('init_range', 'index_range'):
|
||||||
|
if fmt[key]:
|
||||||
|
fmt[key]['start'] = int(fmt[key]['start'])
|
||||||
|
fmt[key]['end'] = int(fmt[key]['end'])
|
||||||
|
update_format_with_type_info(fmt, yt_fmt)
|
||||||
|
cipher = dict(urllib.parse.parse_qsl(multi_get(yt_fmt,
|
||||||
|
'cipher', 'signatureCipher', default='')))
|
||||||
|
if cipher:
|
||||||
|
fmt['url'] = cipher.get('url')
|
||||||
|
else:
|
||||||
|
fmt['url'] = yt_fmt.get('url')
|
||||||
|
fmt['s'] = cipher.get('s')
|
||||||
|
fmt['sp'] = cipher.get('sp')
|
||||||
|
|
||||||
|
# update with information from big table
|
||||||
|
hardcoded_itag_info = _formats.get(str(itag), {})
|
||||||
|
for key, value in hardcoded_itag_info.items():
|
||||||
|
conservative_update(fmt, key, value) # prefer info from Youtube
|
||||||
|
fmt['quality'] = hardcoded_itag_info.get('height')
|
||||||
|
conservative_update(
|
||||||
|
fmt, 'quality',
|
||||||
|
extract_int(yt_fmt.get('quality'), whole_word=False)
|
||||||
|
)
|
||||||
|
conservative_update(
|
||||||
|
fmt, 'quality',
|
||||||
|
extract_int(yt_fmt.get('qualityLabel'), whole_word=False)
|
||||||
|
)
|
||||||
|
|
||||||
|
info['formats'].append(fmt)
|
||||||
|
|
||||||
|
# get ip address
|
||||||
|
if info['formats']:
|
||||||
|
query_string = (info['formats'][0].get('url') or '?').split('?')[1]
|
||||||
|
info['ip_address'] = deep_get(
|
||||||
|
urllib.parse.parse_qs(query_string), 'ip', 0)
|
||||||
|
else:
|
||||||
|
info['ip_address'] = None
|
||||||
|
|
||||||
|
hls_regex = re.compile(r'[\w_-]+=(?:"[^"]+"|[^",]+),')
|
||||||
|
def extract_hls_formats(hls_manifest):
|
||||||
|
'''returns hls_formats, err'''
|
||||||
|
hls_formats = []
|
||||||
|
try:
|
||||||
|
lines = hls_manifest.splitlines()
|
||||||
|
i = 0
|
||||||
|
while i < len(lines):
|
||||||
|
if lines[i].startswith('#EXT-X-STREAM-INF'):
|
||||||
|
fmt = {'acodec': None, 'vcodec': None, 'height': None,
|
||||||
|
'width': None, 'fps': None, 'audio_bitrate': None,
|
||||||
|
'itag': None, 'file_size': None, 'duration_ms': None,
|
||||||
|
'audio_sample_rate': None, 'url': None}
|
||||||
|
properties = lines[i].split(':')[1]
|
||||||
|
properties += ',' # make regex work for last key-value pair
|
||||||
|
|
||||||
|
for pair in hls_regex.findall(properties):
|
||||||
|
key, value = pair.rstrip(',').split('=')
|
||||||
|
if key == 'CODECS':
|
||||||
|
for codec in value.strip('"').split(','):
|
||||||
|
update_format_with_codec_info(fmt, codec)
|
||||||
|
elif key == 'RESOLUTION':
|
||||||
|
fmt['width'], fmt['height'] = map(int, value.split('x'))
|
||||||
|
fmt['resolution'] = value
|
||||||
|
elif key == 'FRAME-RATE':
|
||||||
|
fmt['fps'] = int(value)
|
||||||
|
i += 1
|
||||||
|
fmt['url'] = lines[i]
|
||||||
|
assert fmt['url'].startswith('http')
|
||||||
|
fmt['ext'] = 'm3u8'
|
||||||
|
hls_formats.append(fmt)
|
||||||
|
i += 1
|
||||||
|
except Exception as e:
|
||||||
|
traceback.print_exc()
|
||||||
|
return [], str(e)
|
||||||
|
return hls_formats, None
|
||||||
|
|
||||||
|
|
||||||
|
def _extract_playability_error(info, player_response, error_prefix=''):
|
||||||
|
if info['formats']:
|
||||||
|
info['playability_status'] = None
|
||||||
|
info['playability_error'] = None
|
||||||
|
return
|
||||||
|
|
||||||
|
playability_status = deep_get(player_response, 'playabilityStatus', 'status', default=None)
|
||||||
|
info['playability_status'] = playability_status
|
||||||
|
|
||||||
|
playability_reason = extract_str(multi_deep_get(player_response,
|
||||||
|
['playabilityStatus', 'reason'],
|
||||||
|
['playabilityStatus', 'errorScreen', 'playerErrorMessageRenderer', 'reason'],
|
||||||
|
default='Could not find playability error')
|
||||||
|
)
|
||||||
|
|
||||||
|
if playability_status not in (None, 'OK'):
|
||||||
|
info['playability_error'] = error_prefix + playability_reason
|
||||||
|
elif not info['playability_error']: # do not override
|
||||||
|
info['playability_error'] = error_prefix + 'Unknown playability error'
|
||||||
|
|
||||||
|
SUBTITLE_FORMATS = ('srv1', 'srv2', 'srv3', 'ttml', 'vtt')
|
||||||
|
def extract_watch_info(polymer_json):
|
||||||
|
info = {'playability_error': None, 'error': None,
|
||||||
|
'player_response_missing': None}
|
||||||
|
|
||||||
|
if isinstance(polymer_json, dict):
|
||||||
|
top_level = polymer_json
|
||||||
|
elif isinstance(polymer_json, (list, tuple)):
|
||||||
|
top_level = {}
|
||||||
|
for page_part in polymer_json:
|
||||||
|
if not isinstance(page_part, dict):
|
||||||
|
return {'error': 'Invalid page part'}
|
||||||
|
top_level.update(page_part)
|
||||||
|
else:
|
||||||
|
return {'error': 'Invalid top level polymer data'}
|
||||||
|
|
||||||
|
error = check_missing_keys(top_level,
|
||||||
|
['player', 'args'],
|
||||||
|
['player', 'assets', 'js'],
|
||||||
|
['playerResponse'],
|
||||||
|
)
|
||||||
|
if error:
|
||||||
|
info['playability_error'] = error
|
||||||
|
|
||||||
|
player_response = top_level.get('playerResponse', {})
|
||||||
|
|
||||||
|
# usually, only the embedded one has the urls
|
||||||
|
player_args = deep_get(top_level, 'player', 'args', default={})
|
||||||
|
if 'player_response' in player_args:
|
||||||
|
embedded_player_response = json.loads(player_args['player_response'])
|
||||||
|
else:
|
||||||
|
embedded_player_response = {}
|
||||||
|
|
||||||
|
# captions
|
||||||
|
info['automatic_caption_languages'] = []
|
||||||
|
info['manual_caption_languages'] = []
|
||||||
|
info['_manual_caption_language_names'] = {} # language name written in that language, needed in some cases to create the url
|
||||||
|
info['translation_languages'] = []
|
||||||
|
captions_info = player_response.get('captions', {})
|
||||||
|
info['_captions_base_url'] = normalize_url(deep_get(captions_info, 'playerCaptionsRenderer', 'baseUrl'))
|
||||||
|
# Sometimes the above playerCaptionsRender is randomly missing
|
||||||
|
# Extract base_url from one of the captions by removing lang specifiers
|
||||||
|
if not info['_captions_base_url']:
|
||||||
|
base_url = normalize_url(deep_get(
|
||||||
|
captions_info,
|
||||||
|
'playerCaptionsTracklistRenderer',
|
||||||
|
'captionTracks',
|
||||||
|
0,
|
||||||
|
'baseUrl'
|
||||||
|
))
|
||||||
|
if base_url:
|
||||||
|
url_parts = urllib.parse.urlparse(base_url)
|
||||||
|
qs = urllib.parse.parse_qs(url_parts.query)
|
||||||
|
for key in ('tlang', 'lang', 'name', 'kind', 'fmt'):
|
||||||
|
if key in qs:
|
||||||
|
del qs[key]
|
||||||
|
base_url = urllib.parse.urlunparse(url_parts._replace(
|
||||||
|
query=urllib.parse.urlencode(qs, doseq=True)))
|
||||||
|
info['_captions_base_url'] = base_url
|
||||||
|
for caption_track in deep_get(captions_info, 'playerCaptionsTracklistRenderer', 'captionTracks', default=()):
|
||||||
|
lang_code = caption_track.get('languageCode')
|
||||||
|
if not lang_code:
|
||||||
|
continue
|
||||||
|
if caption_track.get('kind') == 'asr':
|
||||||
|
info['automatic_caption_languages'].append(lang_code)
|
||||||
|
else:
|
||||||
|
info['manual_caption_languages'].append(lang_code)
|
||||||
|
base_url = caption_track.get('baseUrl', '')
|
||||||
|
lang_name = deep_get(urllib.parse.parse_qs(urllib.parse.urlparse(base_url).query), 'name', 0)
|
||||||
|
if lang_name:
|
||||||
|
info['_manual_caption_language_names'][lang_code] = lang_name
|
||||||
|
|
||||||
|
for translation_lang_info in deep_get(captions_info, 'playerCaptionsTracklistRenderer', 'translationLanguages', default=()):
|
||||||
|
lang_code = translation_lang_info.get('languageCode')
|
||||||
|
if lang_code:
|
||||||
|
info['translation_languages'].append(lang_code)
|
||||||
|
if translation_lang_info.get('isTranslatable') == False:
|
||||||
|
print('WARNING: Found non-translatable caption language')
|
||||||
|
|
||||||
|
# formats
|
||||||
|
_extract_formats(info, embedded_player_response)
|
||||||
|
if not info['formats']:
|
||||||
|
_extract_formats(info, player_response)
|
||||||
|
|
||||||
|
# see https://github.com/user234683/youtube-local/issues/22#issuecomment-706395160
|
||||||
|
info['player_urls_missing'] = (
|
||||||
|
not info['formats'] and not embedded_player_response)
|
||||||
|
|
||||||
|
# playability errors
|
||||||
|
_extract_playability_error(info, player_response)
|
||||||
|
|
||||||
|
# check age-restriction
|
||||||
|
info['age_restricted'] = (info['playability_status'] == 'LOGIN_REQUIRED' and info['playability_error'] and ' age' in info['playability_error'])
|
||||||
|
|
||||||
|
# base_js (for decryption of signatures)
|
||||||
|
info['base_js'] = deep_get(top_level, 'player', 'assets', 'js')
|
||||||
|
if info['base_js']:
|
||||||
|
info['base_js'] = normalize_url(info['base_js'])
|
||||||
|
# must uniquely identify url
|
||||||
|
info['player_name'] = urllib.parse.urlparse(info['base_js']).path
|
||||||
|
else:
|
||||||
|
info['player_name'] = None
|
||||||
|
|
||||||
|
# extract stuff from visible parts of page
|
||||||
|
mobile = 'singleColumnWatchNextResults' in deep_get(top_level, 'response', 'contents', default={})
|
||||||
|
if mobile:
|
||||||
|
info.update(_extract_watch_info_mobile(top_level))
|
||||||
|
else:
|
||||||
|
info.update(_extract_watch_info_desktop(top_level))
|
||||||
|
|
||||||
|
# stuff from videoDetails. Use liberal_update to prioritize info from videoDetails over existing info
|
||||||
|
vd = deep_get(top_level, 'playerResponse', 'videoDetails', default={})
|
||||||
|
liberal_update(info, 'title', extract_str(vd.get('title')))
|
||||||
|
liberal_update(info, 'duration', extract_int(vd.get('lengthSeconds')))
|
||||||
|
liberal_update(info, 'view_count', extract_int(vd.get('viewCount')))
|
||||||
|
# videos with no description have a blank string
|
||||||
|
liberal_update(info, 'description', vd.get('shortDescription'))
|
||||||
|
liberal_update(info, 'id', vd.get('videoId'))
|
||||||
|
liberal_update(info, 'author', vd.get('author'))
|
||||||
|
liberal_update(info, 'author_id', vd.get('channelId'))
|
||||||
|
info['was_live'] = vd.get('isLiveContent')
|
||||||
|
conservative_update(info, 'unlisted', not vd.get('isCrawlable', True)) #isCrawlable is false on limited state videos even if they aren't unlisted
|
||||||
|
liberal_update(info, 'tags', vd.get('keywords', []))
|
||||||
|
|
||||||
|
# fallback stuff from microformat
|
||||||
|
mf = deep_get(top_level, 'playerResponse', 'microformat', 'playerMicroformatRenderer', default={})
|
||||||
|
conservative_update(info, 'title', extract_str(mf.get('title')))
|
||||||
|
conservative_update(info, 'duration', extract_int(mf.get('lengthSeconds')))
|
||||||
|
# this gives the view count for limited state videos
|
||||||
|
conservative_update(info, 'view_count', extract_int(mf.get('viewCount')))
|
||||||
|
conservative_update(info, 'description', extract_str(mf.get('description'), recover_urls=True))
|
||||||
|
conservative_update(info, 'author', mf.get('ownerChannelName'))
|
||||||
|
conservative_update(info, 'author_id', mf.get('externalChannelId'))
|
||||||
|
conservative_update(info, 'live', deep_get(mf, 'liveBroadcastDetails',
|
||||||
|
'isLiveNow'))
|
||||||
|
liberal_update(info, 'unlisted', mf.get('isUnlisted'))
|
||||||
|
liberal_update(info, 'category', mf.get('category'))
|
||||||
|
liberal_update(info, 'time_published', mf.get('publishDate'))
|
||||||
|
liberal_update(info, 'time_uploaded', mf.get('uploadDate'))
|
||||||
|
family_safe = mf.get('isFamilySafe')
|
||||||
|
if family_safe is None:
|
||||||
|
conservative_update(info, 'age_restricted', None)
|
||||||
|
else:
|
||||||
|
conservative_update(info, 'age_restricted', not family_safe)
|
||||||
|
info['allowed_countries'] = mf.get('availableCountries', [])
|
||||||
|
|
||||||
|
# other stuff
|
||||||
|
info['author_url'] = 'https://www.youtube.com/channel/' + info['author_id'] if info['author_id'] else None
|
||||||
|
info['storyboard_spec_url'] = deep_get(player_response, 'storyboards', 'playerStoryboardSpecRenderer', 'spec')
|
||||||
|
|
||||||
|
return info
|
||||||
|
|
||||||
|
single_char_codes = {
|
||||||
|
'n': '\n',
|
||||||
|
'\\': '\\',
|
||||||
|
'"': '"',
|
||||||
|
"'": "'",
|
||||||
|
'b': '\b',
|
||||||
|
'f': '\f',
|
||||||
|
'n': '\n',
|
||||||
|
'r': '\r',
|
||||||
|
't': '\t',
|
||||||
|
'v': '\x0b',
|
||||||
|
'0': '\x00',
|
||||||
|
'\n': '', # backslash followed by literal newline joins lines
|
||||||
|
}
|
||||||
|
def js_escape_replace(match):
|
||||||
|
r'''Resolves javascript string escape sequences such as \x..'''
|
||||||
|
# some js-strings in the watch page html include them for no reason
|
||||||
|
# https://mathiasbynens.be/notes/javascript-escapes
|
||||||
|
escaped_sequence = match.group(1)
|
||||||
|
if escaped_sequence[0] in ('x', 'u'):
|
||||||
|
return chr(int(escaped_sequence[1:], base=16))
|
||||||
|
|
||||||
|
# In javascript, if it's not one of those escape codes, it's just the
|
||||||
|
# literal character. e.g., "\a" = "a"
|
||||||
|
return single_char_codes.get(escaped_sequence, escaped_sequence)
|
||||||
|
|
||||||
|
# works but complicated and unsafe:
|
||||||
|
#PLAYER_RESPONSE_RE = re.compile(r'<script[^>]*?>[^<]*?var ytInitialPlayerResponse = ({(?:"(?:[^"\\]|\\.)*?"|[^"])+?});')
|
||||||
|
|
||||||
|
# Because there are sometimes additional statements after the json object
|
||||||
|
# so we just capture all of those until end of script and tell json decoder
|
||||||
|
# to ignore extra stuff after the json object
|
||||||
|
PLAYER_RESPONSE_RE = re.compile(r'<script[^>]*?>[^<]*?var ytInitialPlayerResponse = ({.*?)</script>')
|
||||||
|
INITIAL_DATA_RE = re.compile(r"<script[^>]*?>var ytInitialData = '(.+?[^\\])';")
|
||||||
|
BASE_JS_RE = re.compile(r'jsUrl":\s*"([\w\-\./]+?/base.js)"')
|
||||||
|
JS_STRING_ESCAPE_RE = re.compile(r'\\([^xu]|x..|u....)')
|
||||||
|
def extract_watch_info_from_html(watch_html):
|
||||||
|
base_js_match = BASE_JS_RE.search(watch_html)
|
||||||
|
player_response_match = PLAYER_RESPONSE_RE.search(watch_html)
|
||||||
|
initial_data_match = INITIAL_DATA_RE.search(watch_html)
|
||||||
|
|
||||||
|
if base_js_match is not None:
|
||||||
|
base_js_url = base_js_match.group(1)
|
||||||
|
else:
|
||||||
|
base_js_url = None
|
||||||
|
|
||||||
|
if player_response_match is not None:
|
||||||
|
decoder = json.JSONDecoder()
|
||||||
|
# this will make it ignore extra stuff after end of object
|
||||||
|
player_response = decoder.raw_decode(player_response_match.group(1))[0]
|
||||||
|
else:
|
||||||
|
return {'error': 'Could not find ytInitialPlayerResponse'}
|
||||||
|
player_response = None
|
||||||
|
|
||||||
|
if initial_data_match is not None:
|
||||||
|
initial_data = initial_data_match.group(1)
|
||||||
|
initial_data = JS_STRING_ESCAPE_RE.sub(js_escape_replace, initial_data)
|
||||||
|
initial_data = json.loads(initial_data)
|
||||||
|
else:
|
||||||
|
print('extract_watch_info_from_html: failed to find initialData')
|
||||||
|
initial_data = None
|
||||||
|
|
||||||
|
# imitate old format expected by extract_watch_info
|
||||||
|
fake_polymer_json = {
|
||||||
|
'player': {
|
||||||
|
'args': {},
|
||||||
|
'assets': {
|
||||||
|
'js': base_js_url
|
||||||
|
}
|
||||||
|
},
|
||||||
|
'playerResponse': player_response,
|
||||||
|
'response': initial_data,
|
||||||
|
}
|
||||||
|
|
||||||
|
return extract_watch_info(fake_polymer_json)
|
||||||
|
|
||||||
|
|
||||||
|
def captions_available(info):
|
||||||
|
return bool(info['_captions_base_url'])
|
||||||
|
|
||||||
|
|
||||||
|
def get_caption_url(info, language, format, automatic=False, translation_language=None):
|
||||||
|
'''Gets the url for captions with the given language and format. If automatic is True, get the automatic captions for that language. If translation_language is given, translate the captions from `language` to `translation_language`. If automatic is true and translation_language is given, the automatic captions will be translated.'''
|
||||||
|
url = info['_captions_base_url']
|
||||||
|
if not url:
|
||||||
|
return None
|
||||||
|
url += '&lang=' + language
|
||||||
|
url += '&fmt=' + format
|
||||||
|
if automatic:
|
||||||
|
url += '&kind=asr'
|
||||||
|
elif language in info['_manual_caption_language_names']:
|
||||||
|
url += '&name=' + urllib.parse.quote(info['_manual_caption_language_names'][language], safe='')
|
||||||
|
|
||||||
|
if translation_language:
|
||||||
|
url += '&tlang=' + translation_language
|
||||||
|
return url
|
||||||
|
|
||||||
|
def update_with_new_urls(info, player_response):
|
||||||
|
'''Inserts urls from player_response json'''
|
||||||
|
ERROR_PREFIX = 'Error getting missing player or bypassing age-restriction: '
|
||||||
|
|
||||||
|
try:
|
||||||
|
player_response = json.loads(player_response)
|
||||||
|
except json.decoder.JSONDecodeError:
|
||||||
|
traceback.print_exc()
|
||||||
|
info['playability_error'] = ERROR_PREFIX + 'Failed to parse json response'
|
||||||
|
return
|
||||||
|
|
||||||
|
_extract_formats(info, player_response)
|
||||||
|
_extract_playability_error(info, player_response, error_prefix=ERROR_PREFIX)
|
||||||
|
|
||||||
|
def requires_decryption(info):
|
||||||
|
return ('formats' in info) and info['formats'] and info['formats'][0]['s']
|
||||||
|
|
||||||
|
# adapted from youtube-dl and invidious:
|
||||||
|
# https://github.com/omarroth/invidious/blob/master/src/invidious/helpers/signatures.cr
|
||||||
|
decrypt_function_re = re.compile(r'function\(a\)\{(a=a\.split\(""\)[^\}{]+)return a\.join\(""\)\}')
|
||||||
|
# gives us e.g. rt, .xK, 5 from rt.xK(a,5) or rt, ["xK"], 5 from rt["xK"](a,5)
|
||||||
|
# (var, operation, argument)
|
||||||
|
var_op_arg_re = re.compile(r'(\w+)(\.\w+|\["[^"]+"\])\(a,(\d+)\)')
|
||||||
|
def extract_decryption_function(info, base_js):
|
||||||
|
'''Insert decryption function into info. Return error string if not successful.
|
||||||
|
Decryption function is a list of list[2] of numbers.
|
||||||
|
It is advisable to cache the decryption function (uniquely identified by info['player_name']) so base.js (1 MB) doesn't need to be redownloaded each time'''
|
||||||
|
info['decryption_function'] = None
|
||||||
|
decrypt_function_match = decrypt_function_re.search(base_js)
|
||||||
|
if decrypt_function_match is None:
|
||||||
|
return 'Could not find decryption function in base.js'
|
||||||
|
|
||||||
|
function_body = decrypt_function_match.group(1).split(';')[1:-1]
|
||||||
|
if not function_body:
|
||||||
|
return 'Empty decryption function body'
|
||||||
|
|
||||||
|
var_with_operation_match = var_op_arg_re.fullmatch(function_body[0])
|
||||||
|
if var_with_operation_match is None:
|
||||||
|
return 'Could not find var_name'
|
||||||
|
|
||||||
|
var_name = var_with_operation_match.group(1)
|
||||||
|
var_body_match = re.search(r'var ' + re.escape(var_name) + r'=\{(.*?)\};', base_js, flags=re.DOTALL)
|
||||||
|
if var_body_match is None:
|
||||||
|
return 'Could not find var_body'
|
||||||
|
|
||||||
|
operations = var_body_match.group(1).replace('\n', '').split('},')
|
||||||
|
if not operations:
|
||||||
|
return 'Did not find any definitions in var_body'
|
||||||
|
operations[-1] = operations[-1][:-1] # remove the trailing '}' since we split by '},' on the others
|
||||||
|
operation_definitions = {}
|
||||||
|
for op in operations:
|
||||||
|
colon_index = op.find(':')
|
||||||
|
opening_brace_index = op.find('{')
|
||||||
|
|
||||||
|
if colon_index == -1 or opening_brace_index == -1:
|
||||||
|
return 'Could not parse operation'
|
||||||
|
op_name = op[:colon_index]
|
||||||
|
op_body = op[opening_brace_index+1:]
|
||||||
|
if op_body == 'a.reverse()':
|
||||||
|
operation_definitions[op_name] = 0
|
||||||
|
elif op_body == 'a.splice(0,b)':
|
||||||
|
operation_definitions[op_name] = 1
|
||||||
|
elif op_body.startswith('var c=a[0]'):
|
||||||
|
operation_definitions[op_name] = 2
|
||||||
|
else:
|
||||||
|
return 'Unknown op_body: ' + op_body
|
||||||
|
|
||||||
|
decryption_function = []
|
||||||
|
for op_with_arg in function_body:
|
||||||
|
match = var_op_arg_re.fullmatch(op_with_arg)
|
||||||
|
if match is None:
|
||||||
|
return 'Could not parse operation with arg'
|
||||||
|
op_name = match.group(2).strip('[].')
|
||||||
|
if op_name not in operation_definitions:
|
||||||
|
return 'Unknown op_name: ' + str(op_name)
|
||||||
|
op_argument = match.group(3)
|
||||||
|
decryption_function.append([operation_definitions[op_name], int(op_argument)])
|
||||||
|
|
||||||
|
info['decryption_function'] = decryption_function
|
||||||
|
return False
|
||||||
|
|
||||||
|
def _operation_2(a, b):
|
||||||
|
c = a[0]
|
||||||
|
a[0] = a[b % len(a)]
|
||||||
|
a[b % len(a)] = c
|
||||||
|
|
||||||
|
def decrypt_signatures(info):
|
||||||
|
'''Applies info['decryption_function'] to decrypt all the signatures. Return err.'''
|
||||||
|
if not info.get('decryption_function'):
|
||||||
|
return 'decryption_function not in info'
|
||||||
|
for format in info['formats']:
|
||||||
|
if not format['s'] or not format['sp'] or not format['url']:
|
||||||
|
print('Warning: s, sp, or url not in format')
|
||||||
|
continue
|
||||||
|
|
||||||
|
a = list(format['s'])
|
||||||
|
for op, argument in info['decryption_function']:
|
||||||
|
if op == 0:
|
||||||
|
a.reverse()
|
||||||
|
elif op == 1:
|
||||||
|
a = a[argument:]
|
||||||
|
else:
|
||||||
|
_operation_2(a, argument)
|
||||||
|
|
||||||
|
signature = ''.join(a)
|
||||||
|
format['url'] += '&' + format['sp'] + '=' + signature
|
||||||
|
return False
|
||||||
Reference in New Issue
Block a user